 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaDrift: A Time-dependent Causal Generator of Drifting Data Streams
Feb 23, 2026This work presents Causal Drift Generator (CaDrift), a time-dependent synthetic data generator framework based on Structural Causal Models (SCMs). The framework produces a virtually infinite combination of data streams with controlled shift events and time-dependent data, making it a tool to evaluate methods under evolving data. CaDrift synthesizes various distributional and covariate shifts by drifting mapping functions of the SCM, which change underlying cause-and-effect relationships between features and the target. In addition, CaDrift models occasional perturbations by leveraging interventions in causal modeling. Experimental results show that, after distributional shift events, the accuracy of classifiers tends to drop, followed by a gradual retrieval, confirming the generator's effectiveness in simulating shifts. The framework has been made available on GitHub.
PIPES: A Meta-dataset of Machine Learning Pipelines
Sep 11, 2025Solutions to the Algorithm Selection Problem (ASP) in machine learning face the challenge of high computational costs associated with evaluating various algorithms' performances on a given dataset. To mitigate this cost, the meta-learning field can leverage previously executed experiments shared in online repositories such as OpenML. OpenML provides an extensive collection of machine learning experiments. However, an analysis of OpenML's records reveals limitations. It lacks diversity in pipelines, specifically when exploring data preprocessing steps/blocks, such as scaling or imputation, resulting in limited representation. Its experiments are often focused on a few popular techniques within each pipeline block, leading to an imbalanced sample. To overcome the observed limitations of OpenML, we propose PIPES, a collection of experiments involving multiple pipelines designed to represent all combinations of the selected sets of techniques, aiming at diversity and completeness. PIPES stores the results of experiments performed applying 9,408 pipelines to 300 datasets. It includes detailed information on the pipeline blocks, training and testing times, predictions, performances, and the eventual error messages. This comprehensive collection of results allows researchers to perform analyses across diverse and representative pipelines and datasets. PIPES also offers potential for expansion, as additional data and experiments can be incorporated to support the meta-learning community further. The data, code, supplementary material, and all experiments can be found at https://github.com/cynthiamaia/PIPES.git.
Imbalanced Regression Pipeline Recommendation
Jul 16, 2025Imbalanced problems are prevalent in various real-world scenarios and are extensively explored in classification tasks. However, they also present challenges for regression tasks due to the rarity of certain target values. A common alternative is to employ balancing algorithms in preprocessing to address dataset imbalance. However, due to the variety of resampling methods and learning models, determining the optimal solution requires testing many combinations. Furthermore, the learning model, dataset, and evaluation metric affect the best strategies. This work proposes the Meta-learning for Imbalanced Regression (Meta-IR) framework, which diverges from existing literature by training meta-classifiers to recommend the best pipeline composed of the resampling strategy and learning model per task in a zero-shot fashion. The meta-classifiers are trained using a set of meta-features to learn how to map the meta-features to the classes indicating the best pipeline. We propose two formulations: Independent and Chained. Independent trains the meta-classifiers to separately indicate the best learning algorithm and resampling strategy. Chained involves a sequential procedure where the output of one meta-classifier is used as input for another to model intrinsic relationship factors. The Chained scenario showed superior performance, suggesting a relationship between the learning algorithm and the resampling strategy per task. Compared with AutoML frameworks, Meta-IR obtained better results. Moreover, compared with baselines of six learning algorithms and six resampling algorithms plus no resampling, totaling 42 (6 X 7) configurations, Meta-IR outperformed all of them. The code, data, and further information of the experiments can be found on GitHub: https://github.com/JusciAvelino/Meta-IR.
Resampling strategies for imbalanced regression: a survey and empirical analysis
Jul 16, 2025Imbalanced problems can arise in different real-world situations, and to address this, certain strategies in the form of resampling or balancing algorithms are proposed. This issue has largely been studied in the context of classification, and yet, the same problem features in regression tasks, where target values are continuous. This work presents an extensive experimental study comprising various balancing and predictive models, and wich uses metrics to capture important elements for the user and to evaluate the predictive model in an imbalanced regression data context. It also proposes a taxonomy for imbalanced regression approaches based on three crucial criteria: regression model, learning process, and evaluation metrics. The study offers new insights into the use of such strategies, highlighting the advantages they bring to each model's learning process, and indicating directions for further studies. The code, data and further information related to the experiments performed herein can be found on GitHub: https://github.com/JusciAvelino/imbalancedRegression.
Beyond Patches: Mining Interpretable Part-Prototypes for Explainable AI
Apr 16, 2025Deep learning has provided considerable advancements for multimedia systems, yet the interpretability of deep models remains a challenge. State-of-the-art post-hoc explainability methods, such as GradCAM, provide visual interpretation based on heatmaps but lack conceptual clarity. Prototype-based approaches, like ProtoPNet and PIPNet, offer a more structured explanation but rely on fixed patches, limiting their robustness and semantic consistency. To address these limitations, a part-prototypical concept mining network (PCMNet) is proposed that dynamically learns interpretable prototypes from meaningful regions. PCMNet clusters prototypes into concept groups, creating semantically grounded explanations without requiring additional annotations. Through a joint process of unsupervised part discovery and concept activation vector extraction, PCMNet effectively captures discriminative concepts and makes interpretable classification decisions. Our extensive experiments comparing PCMNet against state-of-the-art methods on multiple datasets show that it can provide a high level of interpretability, stability, and robustness under clean and occluded scenarios.
Multi-view autoencoders for Fake News Detection
Apr 10, 2025Given the volume and speed at which fake news spreads across social media, automatic fake news detection has become a highly important task. However, this task presents several challenges, including extracting textual features that contain relevant information about fake news. Research about fake news detection shows that no single feature extraction technique consistently outperforms the others across all scenarios. Nevertheless, different feature extraction techniques can provide complementary information about the textual data and enable a more comprehensive representation of the content. This paper proposes using multi-view autoencoders to generate a joint feature representation for fake news detection by integrating several feature extraction techniques commonly used in the literature. Experiments on fake news datasets show a significant improvement in classification performance compared to individual views (feature representations). We also observed that selecting a subset of the views instead of composing a latent space with all the views can be advantageous in terms of accuracy and computational effort. For further details, including source codes, figures, and datasets, please refer to the project's repository: https://github.com/ingrydpereira/multiview-fake-news.
SEREP: Semantic Facial Expression Representation for Robust In-the-Wild Capture and Retargeting
Dec 18, 2024Monocular facial performance capture in-the-wild is challenging due to varied capture conditions, face shapes, and expressions. Most current methods rely on linear 3D Morphable Models, which represent facial expressions independently of identity at the vertex displacement level. We propose SEREP (Semantic Expression Representation), a model that disentangles expression from identity at the semantic level. It first learns an expression representation from unpaired 3D facial expressions using a cycle consistency loss. Then we train a model to predict expression from monocular images using a novel semi-supervised scheme that relies on domain adaptation. In addition, we introduce MultiREX, a benchmark addressing the lack of evaluation resources for the expression capture task. Our experiments show that SEREP outperforms state-of-the-art methods, capturing challenging expressions and transferring them to novel identities.
Image Retrieval Methods in the Dissimilarity Space
Dec 11, 2024



Image retrieval methods rely on metric learning to train backbone feature extraction models that can extract discriminant queries and reference (gallery) feature representations for similarity matching. Although state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large datasets, image retrieval remains challenging in many real-world video analytics and surveillance applications, e.g., person re-identification. Using the Euclidean space for matching limits the performance in real-world applications due to the curse of dimensionality, overfitting, and sensitivity to noisy data. We argue that the feature dissimilarity space is more suitable for similarity matching, and propose a dichotomy transformation to project query and reference embeddings into a single embedding in the dissimilarity space. We also advocate for end-to-end training of a backbone and binary classification models for pair-wise matching. As opposed to comparing the distance between queries and reference embeddings, we show the benefits of classifying the single dissimilarity space embedding (as similar or dissimilar), especially when trained end-to-end. We propose a method to train the max-margin classifier together with the backbone feature extractor by applying constraints to the L2 norm of the classifier weights along with the hinge loss. Our extensive experiments on challenging image retrieval datasets and using diverse feature extraction backbones highlight the benefits of similarity matching in the dissimilarity space. In particular, when jointly training the feature extraction backbone and regularised classifier for matching, the dissimilarity space provides a higher level of accuracy.
MLRS-PDS: A Meta-learning recommendation of dynamic ensemble selection pipelines
Jul 10, 2024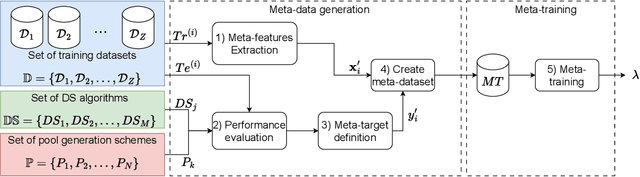
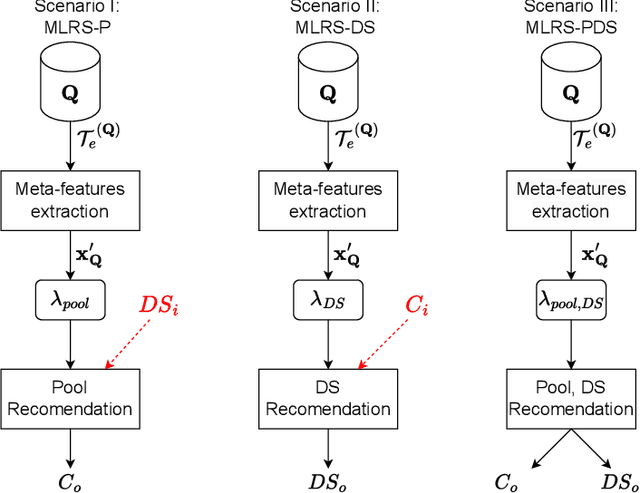
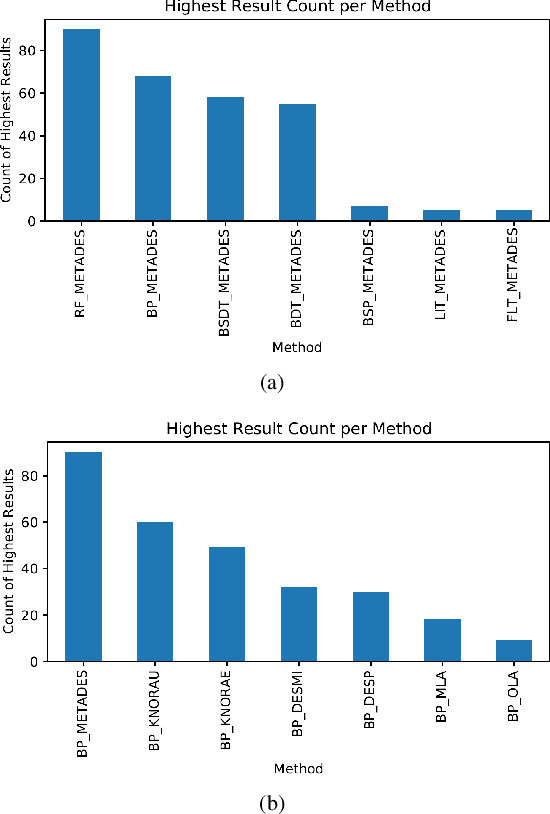
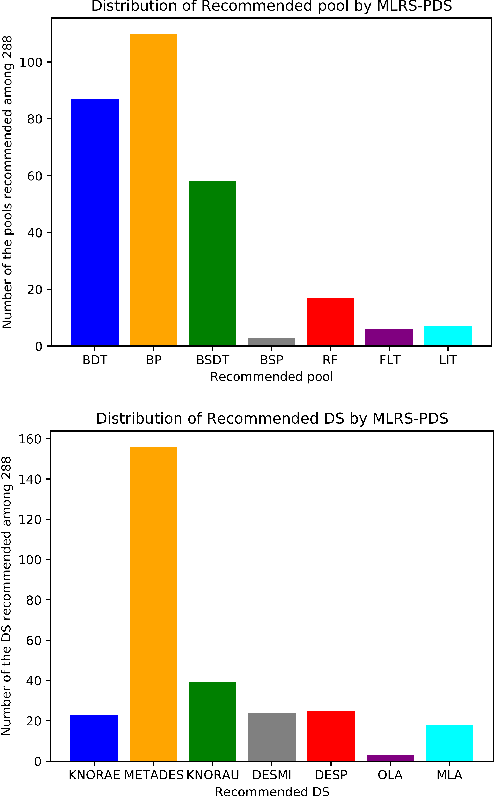
Dynamic Selection (DS), where base classifiers are chosen from a classifier's pool for each new instance at test time, has shown to be highly effective in pattern recognition. However, instability and redundancy in the classifier pools can impede computational efficiency and accuracy in dynamic ensemble selection. This paper introduces a meta-learning recommendation system (MLRS) to recommend the optimal pool generation scheme for DES methods tailored to individual datasets. The system employs a meta-model built from dataset meta-features to predict the most suitable pool generation scheme and DES method for a given dataset. Through an extensive experimental study encompassing 288 datasets, we demonstrate that this meta-learning recommendation system outperforms traditional fixed pool or DES method selection strategies, highlighting the efficacy of a meta-learning approach in refining DES method selection. The source code, datasets, and supplementary results can be found in this project's GitHub repository: https://github.com/Menelau/MLRS-PDS.
Bidirectional Multi-Step Domain Generalization for Visible-Infrared Person Re-Identification
Mar 16, 2024



A key challenge in visible-infrared person re-identification (V-I ReID) is training a backbone model capable of effectively addressing the significant discrepancies across modalities. State-of-the-art methods that generate a single intermediate bridging domain are often less effective, as this generated domain may not adequately capture sufficient common discriminant information. This paper introduces the Bidirectional Multi-step Domain Generalization (BMDG), a novel approach for unifying feature representations across diverse modalities. BMDG creates multiple virtual intermediate domains by finding and aligning body part features extracted from both I and V modalities. Indeed, BMDG aims to reduce the modality gaps in two steps. First, it aligns modalities in feature space by learning shared and modality-invariant body part prototypes from V and I images. Then, it generalizes the feature representation by applying bidirectional multi-step learning, which progressively refines feature representations in each step and incorporates more prototypes from both modalities. In particular, our method minimizes the cross-modal gap by identifying and aligning shared prototypes that capture key discriminative features across modalities, then uses multiple bridging steps based on this information to enhance the feature representation. Experiments conducted on challenging V-I ReID datasets indicate that our BMDG approach outperforms state-of-the-art part-based models or methods that generate an intermediate domain from V-I person ReID.