 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Patches: Mining Interpretable Part-Prototypes for Explainable AI
Apr 16, 2025Deep learning has provided considerable advancements for multimedia systems, yet the interpretability of deep models remains a challenge. State-of-the-art post-hoc explainability methods, such as GradCAM, provide visual interpretation based on heatmaps but lack conceptual clarity. Prototype-based approaches, like ProtoPNet and PIPNet, offer a more structured explanation but rely on fixed patches, limiting their robustness and semantic consistency. To address these limitations, a part-prototypical concept mining network (PCMNet) is proposed that dynamically learns interpretable prototypes from meaningful regions. PCMNet clusters prototypes into concept groups, creating semantically grounded explanations without requiring additional annotations. Through a joint process of unsupervised part discovery and concept activation vector extraction, PCMNet effectively captures discriminative concepts and makes interpretable classification decisions. Our extensive experiments comparing PCMNet against state-of-the-art methods on multiple datasets show that it can provide a high level of interpretability, stability, and robustness under clean and occluded scenarios.
Bidirectional Multi-Step Domain Generalization for Visible-Infrared Person Re-Identification
Mar 16, 2024



A key challenge in visible-infrared person re-identification (V-I ReID) is training a backbone model capable of effectively addressing the significant discrepancies across modalities. State-of-the-art methods that generate a single intermediate bridging domain are often less effective, as this generated domain may not adequately capture sufficient common discriminant information. This paper introduces the Bidirectional Multi-step Domain Generalization (BMDG), a novel approach for unifying feature representations across diverse modalities. BMDG creates multiple virtual intermediate domains by finding and aligning body part features extracted from both I and V modalities. Indeed, BMDG aims to reduce the modality gaps in two steps. First, it aligns modalities in feature space by learning shared and modality-invariant body part prototypes from V and I images. Then, it generalizes the feature representation by applying bidirectional multi-step learning, which progressively refines feature representations in each step and incorporates more prototypes from both modalities. In particular, our method minimizes the cross-modal gap by identifying and aligning shared prototypes that capture key discriminative features across modalities, then uses multiple bridging steps based on this information to enhance the feature representation. Experiments conducted on challenging V-I ReID datasets indicate that our BMDG approach outperforms state-of-the-art part-based models or methods that generate an intermediate domain from V-I person ReID.
Adaptive Generation of Privileged Intermediate Information for Visible-Infrared Person Re-Identification
Jul 06, 2023



Visible-infrared person re-identification seeks to retrieve images of the same individual captured over a distributed network of RGB and IR sensors. Several V-I ReID approaches directly integrate both V and I modalities to discriminate persons within a shared representation space. However, given the significant gap in data distributions between V and I modalities, cross-modal V-I ReID remains challenging. Some recent approaches improve generalization by leveraging intermediate spaces that can bridge V and I modalities, yet effective methods are required to select or generate data for such informative domains. In this paper, the Adaptive Generation of Privileged Intermediate Information training approach is introduced to adapt and generate a virtual domain that bridges discriminant information between the V and I modalities. The key motivation behind AGPI^2 is to enhance the training of a deep V-I ReID backbone by generating privileged images that provide additional information. These privileged images capture shared discriminative features that are not easily accessible within the original V or I modalities alone. Towards this goal, a non-linear generative module is trained with an adversarial objective, translating V images into intermediate spaces with a smaller domain shift w.r.t. the I domain. Meanwhile, the embedding module within AGPI^2 aims to produce similar features for both V and generated images, encouraging the extraction of features that are common to all modalities. In addition to these contributions, AGPI^2 employs adversarial objectives for adapting the intermediate images, which play a crucial role in creating a non-modality-specific space to address the large domain shifts between V and I domains. Experimental results conducted on challenging V-I ReID datasets indicate that AGPI^2 increases matching accuracy without extra computational resources during inference.
Fusion for Visual-Infrared Person ReID in Real-World Surveillance Using Corrupted Multimodal Data
Apr 29, 2023Visible-infrared person re-identification (V-I ReID) seeks to match images of individuals captured over a distributed network of RGB and IR cameras. The task is challenging due to the significant differences between V and I modalities, especially under real-world conditions, where images are corrupted by, e.g, blur, noise, and weather. Indeed, state-of-art V-I ReID models cannot leverage corrupted modality information to sustain a high level of accuracy. In this paper, we propose an efficient model for multimodal V-I ReID -- named Multimodal Middle Stream Fusion (MMSF) -- that preserves modality-specific knowledge for improved robustness to corrupted multimodal images. In addition, three state-of-art attention-based multimodal fusion models are adapted to address corrupted multimodal data in V-I ReID, allowing to dynamically balance each modality importance. Recently, evaluation protocols have been proposed to assess the robustness of ReID models under challenging real-world scenarios. However, these protocols are limited to unimodal V settings. For realistic evaluation of multimodal (and cross-modal) V-I person ReID models, we propose new challenging corrupted datasets for scenarios where V and I cameras are co-located (CL) and not co-located (NCL). Finally, the benefits of our Masking and Local Multimodal Data Augmentation (ML-MDA) strategy are explored to improve the robustness of ReID models to multimodal corruption. Our experiments on clean and corrupted versions of the SYSU-MM01, RegDB, and ThermalWORLD datasets indicate the multimodal V-I ReID models that are more likely to perform well in real-world operational conditions. In particular, our ML-MDA is an important strategy for a V-I person ReID system to sustain high accuracy and robustness when processing corrupted multimodal images. Also, our multimodal ReID model MMSF outperforms every method under CL and NCL camera scenarios.
Multimodal Data Augmentation for Visual-Infrared Person ReID with Corrupted Data
Nov 22, 2022The re-identification (ReID) of individuals over a complex network of cameras is a challenging task, especially under real-world surveillance conditions. Several deep learning models have been proposed for visible-infrared (V-I) person ReID to recognize individuals from images captured using RGB and IR cameras. However, performance may decline considerably if RGB and IR images captured at test time are corrupted (e.g., noise, blur, and weather conditions). Although various data augmentation (DA) methods have been explored to improve the generalization capacity, these are not adapted for V-I person ReID. In this paper, a specialized DA strategy is proposed to address this multimodal setting. Given both the V and I modalities, this strategy allows to diminish the impact of corruption on the accuracy of deep person ReID models. Corruption may be modality-specific, and an additional modality often provides complementary information. Our multimodal DA strategy is designed specifically to encourage modality collaboration and reinforce generalization capability. For instance, punctual masking of modalities forces the model to select the informative modality. Local DA is also explored for advanced selection of features within and among modalities. The impact of training baseline fusion models for V-I person ReID using the proposed multimodal DA strategy is assessed on corrupted versions of the SYSU-MM01, RegDB, and ThermalWORLD datasets in terms of complexity and efficiency. Results indicate that using our strategy provides V-I ReID models the ability to exploit both shared and individual modality knowledge so they can outperform models trained with no or unimodal DA. GitHub code: https://github.com/art2611/ML-MDA.
Visible-Infrared Person Re-Identification Using Privileged Intermediate Information
Sep 19, 2022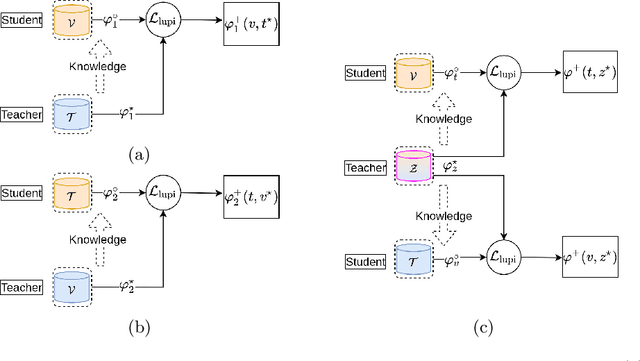
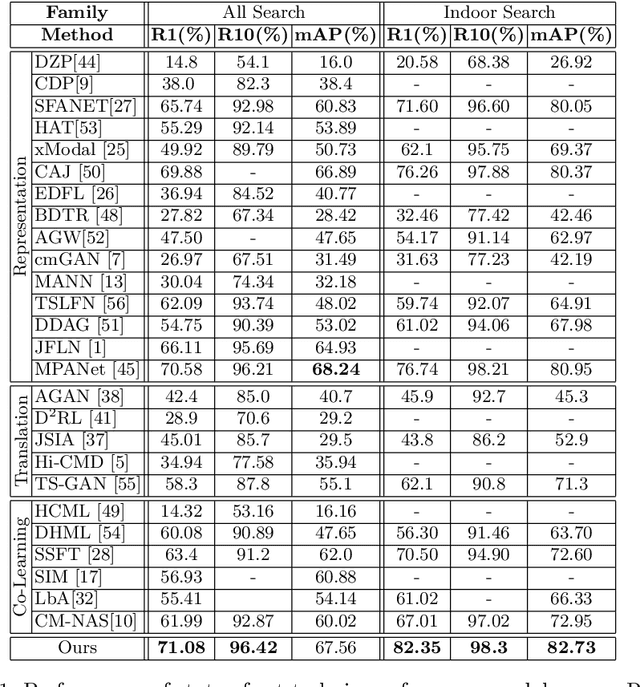

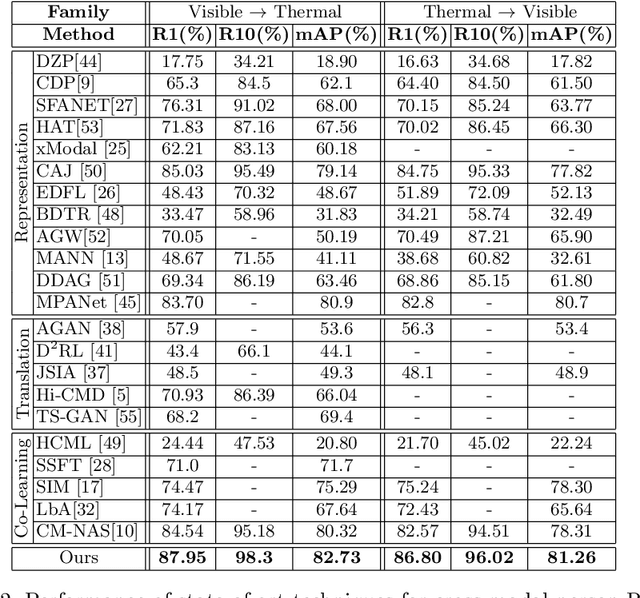
Visible-infrared person re-identification (ReID) aims to recognize a same person of interest across a network of RGB and IR cameras. Some deep learning (DL) models have directly incorporated both modalities to discriminate persons in a joint representation space. However, this cross-modal ReID problem remains challenging due to the large domain shift in data distributions between RGB and IR modalities. % This paper introduces a novel approach for a creating intermediate virtual domain that acts as bridges between the two main domains (i.e., RGB and IR modalities) during training. This intermediate domain is considered as privileged information (PI) that is unavailable at test time, and allows formulating this cross-modal matching task as a problem in learning under privileged information (LUPI). We devised a new method to generate images between visible and infrared domains that provide additional information to train a deep ReID model through an intermediate domain adaptation. In particular, by employing color-free and multi-step triplet loss objectives during training, our method provides common feature representation spaces that are robust to large visible-infrared domain shifts. % Experimental results on challenging visible-infrared ReID datasets indicate that our proposed approach consistently improves matching accuracy, without any computational overhead at test time. The code is available at: \href{https://github.com/alehdaghi/Cross-Modal-Re-ID-via-LUPI}{https://github.com/alehdaghi/Cross-Modal-Re-ID-via-LUPI}