 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Switching Without Forgetting via Proximal Decoupling
Apr 20, 2026In continual learning, the primary challenge is to learn new information without forgetting old knowledge. A common solution addresses this trade-off through regularization, penalizing changes to parameters critical for previous tasks. In most cases, this regularization term is directly added to the training loss and optimized with standard gradient descent, which blends learning and retention signals into a single update and does not explicitly separate essential parameters from redundant ones. As task sequences grow, this coupling can over-constrain the model, limiting forward transfer and leading to inefficient use of capacity. We propose a different approach that separates task learning from stability enforcement via operator splitting. The learning step focuses on minimizing the current task loss, while a proximal stability step applies a sparse regularizer to prune unnecessary parameters and preserve task-relevant ones. This turns the stability-plasticity into a negotiated update between two complementary operators, rather than a conflicting gradient. We provide theoretical justification for the splitting method on the continual-learning objective, and demonstrate that our proposed solver achieves state-of-the-art results on standard benchmarks, improving both stability and adaptability without the need for replay buffers, Bayesian sampling, or meta-learning components.
Multi-Domain Learning with Global Expert Mapping
Apr 20, 2026Human perception generalizes well across different domains, but most vision models struggle beyond their training data. This gap motivates multi-dataset learning, where a single model is trained on diverse datasets to improve robustness under domain shifts. However, unified training remains challenging due to inconsistencies in data distributions and label semantics. Mixture-of-Experts (MoE) models provide a scalable solution by routing inputs to specialized subnetworks (experts). Yet, existing MoEs often fail to specialize effectively, as their load-balancing mechanisms enforce uniform input distribution across experts. This fairness conflicts with domain-aware routing, causing experts to learn redundant representations, and reducing performance especially on rare or out-of-distribution domains. We propose GEM (Global Expert Mapping), a planner-compiler framework that replaces the learned router with a global scheduler. Our planner, based on linear programming relaxation, computes a fractional assignment of datasets to experts, while the compiler applies hierarchical rounding to convert this soft plan into a deterministic, capacity-aware mapping. Unlike prior MoEs, GEM avoids balancing loss, resolves the conflict between fairness and specialization, and produces interpretable routing. Experiments show that GEM-DINO achieves state-of-the-art performance on the UODB benchmark, with notable gains on underrepresented datasets and solves task interference in few-shot adaptation scenarios.
HMR-Net: Hierarchical Modular Routing for Cross-Domain Object Detection in Aerial Images
Apr 20, 2026Despite advances in object detection, aerial imagery remains a challenging domain, as models often fail to generalize across variations in spatial resolution, scene composition, and semantic label coverage. Differences in geographic context, sensor characteristics, and object distributions across datasets limit the capacity of conventional models to learn consistent and transferable representations. Shared methods trained on such data tend to impose a unified representation across fundamentally different domains, resulting in poor performance on region-specific content and less flexibility when dealing with novel object categories. To address this, we propose a novel modular learning framework that enables structured specialization in aerial detection. Our method introduces a hierarchical routing mechanism with two levels of modularity: a global expert assignment layer that uses latent geographic embeddings to route datasets to specialized processing modules, and a local scene decomposition mechanism that allocates image subregions to region-specific sub-modules. This allows our method to specialize across datasets and within complex scenes. Additionally, the framework contains a conditional expert module that uses external semantic information (e.g., category names or textual descriptions) to enable detection of novel object categories during inference, without the need for retraining or fine-tuning. By moving beyond monolithic representations, our method offers an adaptive framework for remote sensing object detection. Comprehensive evaluations on four datasets highlight improvements in multi-dataset generalization, regional specialization, and open-category detection.
Adaptation of Weakly Supervised Localization in Histopathology by Debiasing Predictions
Mar 12, 2026Weakly Supervised Object Localization (WSOL) models enable joint classification and region-of-interest localization in histology images using only image-class supervision. When deployed in a target domain, distributions shift remains a major cause of performance degradation, especially when applied on new organs or institutions with different staining protocols and scanner characteristics. Under stronger cross-domain shifts, WSOL predictions can become biased toward dominant classes, producing highly skewed pseudo-label distributions in the target domain. Source-Free (Unsupervised) Domain Adaptation (SFDA) methods are commonly employed to address domain shift. However, because they rely on self-training, the initial bias is reinforced over training iterations, degrading both classification and localization tasks. We identify this amplification of prediction bias as a primary obstacle to the SFDA of WSOL models in histopathology. This paper introduces \sfdadep, a method inspired by machine unlearning that formulates SFDA as an iterative process of identifying and correcting prediction bias. It periodically identifies target images from over-predicted classes and selectively reduces the predictive confidence for uncertain (high entropy) images, while preserving confident predictions. This process reduces the drift of decision boundaries and bias toward dominant classes. A jointly optimized pixel-level classifier further restores discriminative localization features under distribution shift. Extensive experiments on cross-organ and -center histopathology benchmarks (glas, CAMELYON-16, CAMELYON-17) with several WSOL models show that SFDA-DeP consistently improves classification and localization over state-of-the-art SFDA baselines. {\small Code: \href{https://anonymous.4open.science/r/SFDA-DeP-1797/}{anonymous.4open.science/r/SFDA-DeP-1797/}}
IntRec: Intent-based Retrieval with Contrastive Refinement
Feb 19, 2026Retrieving user-specified objects from complex scenes remains a challenging task, especially when queries are ambiguous or involve multiple similar objects. Existing open-vocabulary detectors operate in a one-shot manner, lacking the ability to refine predictions based on user feedback. To address this, we propose IntRec, an interactive object retrieval framework that refines predictions based on user feedback. At its core is an Intent State (IS) that maintains dual memory sets for positive anchors (confirmed cues) and negative constraints (rejected hypotheses). A contrastive alignment function ranks candidate objects by maximizing similarity to positive cues while penalizing rejected ones, enabling fine-grained disambiguation in cluttered scenes. Our interactive framework provides substantial improvements in retrieval accuracy without additional supervision. On LVIS, IntRec achieves 35.4 AP, outperforming OVMR, CoDet, and CAKE by +2.3, +3.7, and +0.5, respectively. On the challenging LVIS-Ambiguous benchmark, it improves performance by +7.9 AP over its one-shot baseline after a single corrective feedback, with less than 30 ms of added latency per interaction.
Finding Structure in Continual Learning
Feb 04, 2026Learning from a stream of tasks usually pits plasticity against stability: acquiring new knowledge often causes catastrophic forgetting of past information. Most methods address this by summing competing loss terms, creating gradient conflicts that are managed with complex and often inefficient strategies such as external memory replay or parameter regularization. We propose a reformulation of the continual learning objective using Douglas-Rachford Splitting (DRS). This reframes the learning process not as a direct trade-off, but as a negotiation between two decoupled objectives: one promoting plasticity for new tasks and the other enforcing stability of old knowledge. By iteratively finding a consensus through their proximal operators, DRS provides a more principled and stable learning dynamic. Our approach achieves an efficient balance between stability and plasticity without the need for auxiliary modules or complex add-ons, providing a simpler yet more powerful paradigm for continual learning systems.
From Missing Pieces to Masterpieces: Image Completion with Context-Adaptive Diffusion
Apr 19, 2025Image completion is a challenging task, particularly when ensuring that generated content seamlessly integrates with existing parts of an image. While recent diffusion models have shown promise, they often struggle with maintaining coherence between known and unknown (missing) regions. This issue arises from the lack of explicit spatial and semantic alignment during the diffusion process, resulting in content that does not smoothly integrate with the original image. Additionally, diffusion models typically rely on global learned distributions rather than localized features, leading to inconsistencies between the generated and existing image parts. In this work, we propose ConFill, a novel framework that introduces a Context-Adaptive Discrepancy (CAD) model to ensure that intermediate distributions of known and unknown regions are closely aligned throughout the diffusion process. By incorporating CAD, our model progressively reduces discrepancies between generated and original images at each diffusion step, leading to contextually aligned completion. Moreover, ConFill uses a new Dynamic Sampling mechanism that adaptively increases the sampling rate in regions with high reconstruction complexity. This approach enables precise adjustments, enhancing detail and integration in restored areas. Extensive experiments demonstrate that ConFill outperforms current methods, setting a new benchmark in image completion.
Beyond Patches: Mining Interpretable Part-Prototypes for Explainable AI
Apr 16, 2025Deep learning has provided considerable advancements for multimedia systems, yet the interpretability of deep models remains a challenge. State-of-the-art post-hoc explainability methods, such as GradCAM, provide visual interpretation based on heatmaps but lack conceptual clarity. Prototype-based approaches, like ProtoPNet and PIPNet, offer a more structured explanation but rely on fixed patches, limiting their robustness and semantic consistency. To address these limitations, a part-prototypical concept mining network (PCMNet) is proposed that dynamically learns interpretable prototypes from meaningful regions. PCMNet clusters prototypes into concept groups, creating semantically grounded explanations without requiring additional annotations. Through a joint process of unsupervised part discovery and concept activation vector extraction, PCMNet effectively captures discriminative concepts and makes interpretable classification decisions. Our extensive experiments comparing PCMNet against state-of-the-art methods on multiple datasets show that it can provide a high level of interpretability, stability, and robustness under clean and occluded scenarios.
HalluShift: Measuring Distribution Shifts towards Hallucination Detection in LLMs
Apr 13, 2025



Large Language Models (LLMs) have recently garnered widespread attention due to their adeptness at generating innovative responses to the given prompts across a multitude of domains. However, LLMs often suffer from the inherent limitation of hallucinations and generate incorrect information while maintaining well-structured and coherent responses. In this work, we hypothesize that hallucinations stem from the internal dynamics of LLMs. Our observations indicate that, during passage generation, LLMs tend to deviate from factual accuracy in subtle parts of responses, eventually shifting toward misinformation. This phenomenon bears a resemblance to human cognition, where individuals may hallucinate while maintaining logical coherence, embedding uncertainty within minor segments of their speech. To investigate this further, we introduce an innovative approach, HalluShift, designed to analyze the distribution shifts in the internal state space and token probabilities of the LLM-generated responses. Our method attains superior performance compared to existing baselines across various benchmark datasets. Our codebase is available at https://github.com/sharanya-dasgupta001/hallushift.
Fractional Correspondence Framework in Detection Transformer
Mar 06, 2025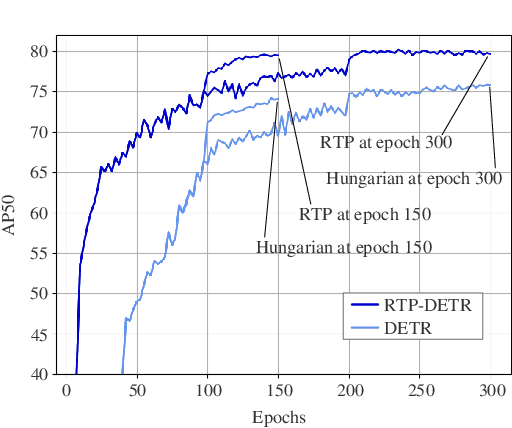
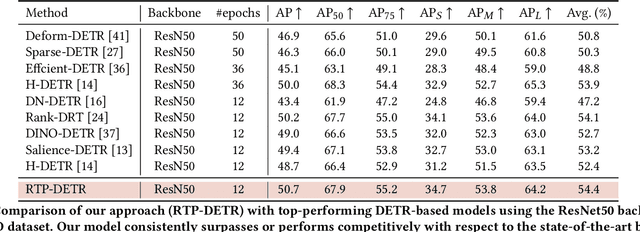
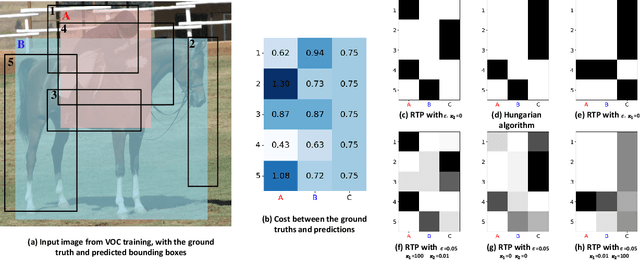
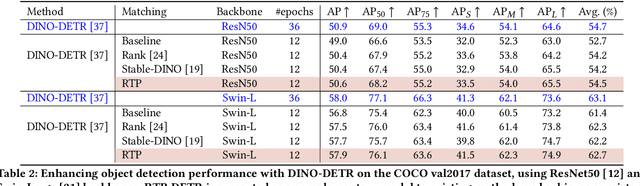
The Detection Transformer (DETR), by incorporating the Hungarian algorithm, has significantly simplified the matching process in object detection tasks. This algorithm facilitates optimal one-to-one matching of predicted bounding boxes to ground-truth annotations during training. While effective, this strict matching process does not inherently account for the varying densities and distributions of objects, leading to suboptimal correspondences such as failing to handle multiple detections of the same object or missing small objects. To address this, we propose the Regularized Transport Plan (RTP). RTP introduces a flexible matching strategy that captures the cost of aligning predictions with ground truths to find the most accurate correspondences between these sets. By utilizing the differentiable Sinkhorn algorithm, RTP allows for soft, fractional matching rather than strict one-to-one assignments. This approach enhances the model's capability to manage varying object densities and distributions effectively. Our extensive evaluations on the MS-COCO and VOC benchmarks demonstrate the effectiveness of our approach. RTP-DETR, surpassing the performance of the Deform-DETR and the recently introduced DINO-DETR, achieving absolute gains in mAP of +3.8% and +1.7%, respectively.