 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional Correspondence Framework in Detection Transformer
Mar 06, 2025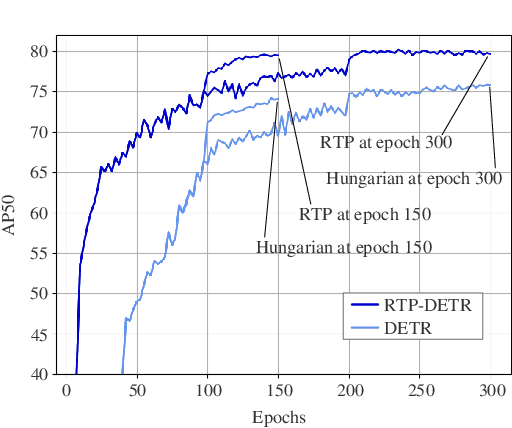
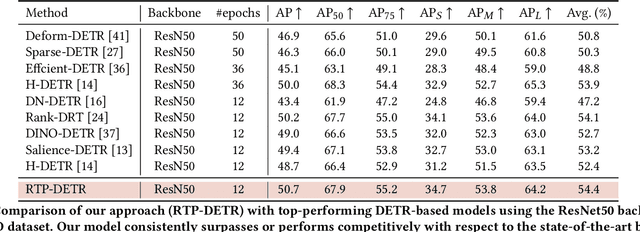
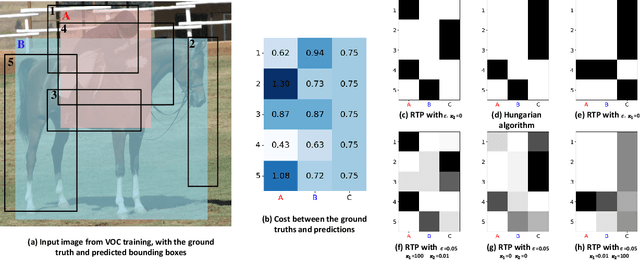
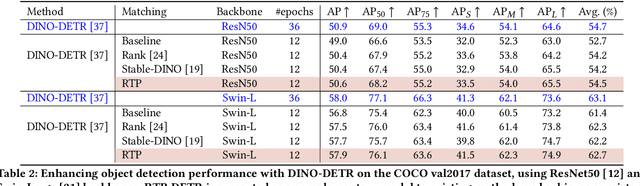
The Detection Transformer (DETR), by incorporating the Hungarian algorithm, has significantly simplified the matching process in object detection tasks. This algorithm facilitates optimal one-to-one matching of predicted bounding boxes to ground-truth annotations during training. While effective, this strict matching process does not inherently account for the varying densities and distributions of objects, leading to suboptimal correspondences such as failing to handle multiple detections of the same object or missing small objects. To address this, we propose the Regularized Transport Plan (RTP). RTP introduces a flexible matching strategy that captures the cost of aligning predictions with ground truths to find the most accurate correspondences between these sets. By utilizing the differentiable Sinkhorn algorithm, RTP allows for soft, fractional matching rather than strict one-to-one assignments. This approach enhances the model's capability to manage varying object densities and distributions effectively. Our extensive evaluations on the MS-COCO and VOC benchmarks demonstrate the effectiveness of our approach. RTP-DETR, surpassing the performance of the Deform-DETR and the recently introduced DINO-DETR, achieving absolute gains in mAP of +3.8% and +1.7%, respectively.
Multisource Semisupervised Adversarial Domain Generalization Network for Cross-Scene Sea\textendash Land Clutter Classification
Feb 09, 2024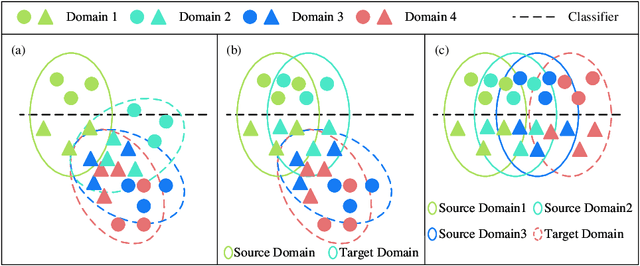
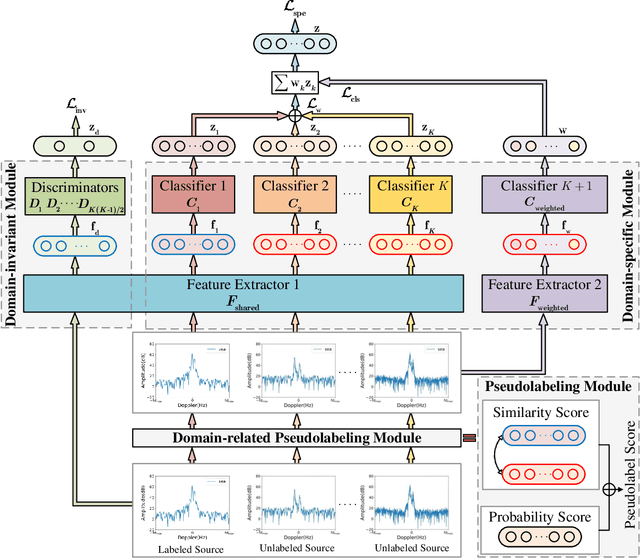
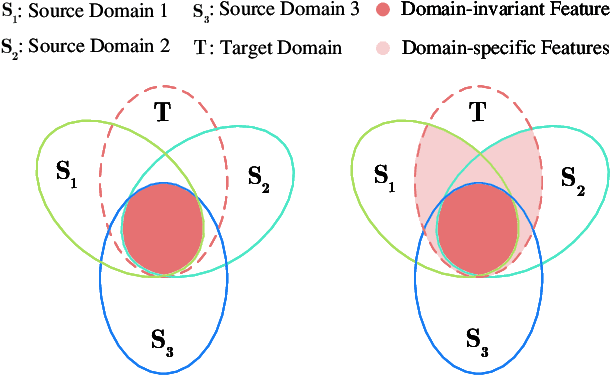
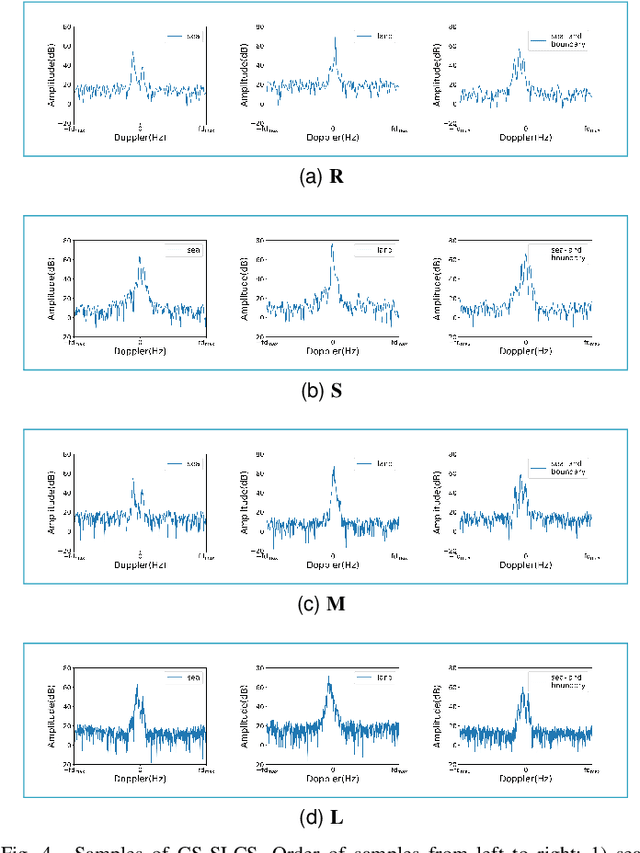
Deep learning (DL)-based sea\textendash land clutter classification for sky-wave over-the-horizon-radar (OTHR) has become a novel research topic. In engineering applications, real-time predictions of sea\textendash land clutter with existing distribution discrepancies are crucial. To solve this problem, this article proposes a novel Multisource Semisupervised Adversarial Domain Generalization Network (MSADGN) for cross-scene sea\textendash land clutter classification. MSADGN can extract domain-invariant and domain-specific features from one labeled source domain and multiple unlabeled source domains, and then generalize these features to an arbitrary unseen target domain for real-time prediction of sea\textendash land clutter. Specifically, MSADGN consists of three modules: domain-related pseudolabeling module, domain-invariant module, and domain-specific module. The first module introduces an improved pseudolabel method called domain-related pseudolabel, which is designed to generate reliable pseudolabels to fully exploit unlabeled source domains. The second module utilizes a generative adversarial network (GAN) with a multidiscriminator to extract domain-invariant features, to enhance the model's transferability in the target domain. The third module employs a parallel multiclassifier branch to extract domain-specific features, to enhance the model's discriminability in the target domain. The effectiveness of our method is validated in twelve domain generalizations (DG) scenarios. Meanwhile, we selected 10 state-of-the-art DG methods for comparison. The experimental results demonstrate the superiority of our method.
On Forecast Stability
Oct 26, 2023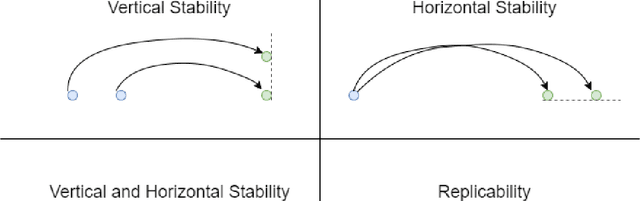

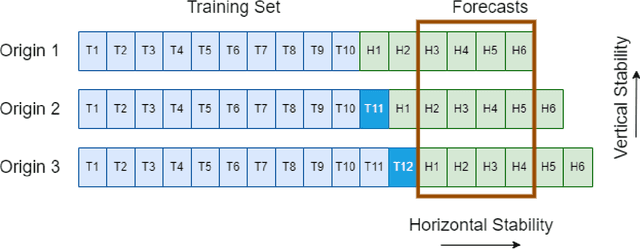

Forecasts are typically not produced in a vacuum but in a business context, where forecasts are generated on a regular basis and interact with each other. For decisions, it may be important that forecasts do not change arbitrarily, and are stable in some sense. However, this area has received only limited attention in the forecasting literature. In this paper, we explore two types of forecast stability that we call vertical stability and horizontal stability. The existing works in the literature are only applicable to certain base models and extending these frameworks to be compatible with any base model is not straightforward. Furthermore, these frameworks can only stabilise the forecasts vertically. To fill this gap, we propose a simple linear-interpolation-based approach that is applicable to stabilise the forecasts provided by any base model vertically and horizontally. The approach can produce both accurate and stable forecasts. Using N-BEATS, Pooled Regression and LightGBM as the base models, in our evaluation on four publicly available datasets, the proposed framework is able to achieve significantly higher stability and/or accuracy compared to a set of benchmarks including a state-of-the-art forecast stabilisation method across three error metrics and six stability metrics.
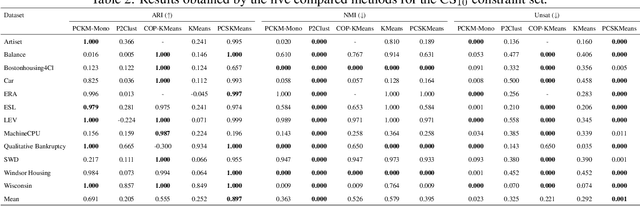
Semi-Supervised Constrained Clustering: An In-Depth Overview, Ranked Taxonomy and Future Research Directions
Feb 28, 2023Clustering is a well-known unsupervised machine learning approach capable of automatically grouping discrete sets of instances with similar characteristics. Constrained clustering is a semi-supervised extension to this process that can be used when expert knowledge is available to indicate constraints that can be exploited. Well-known examples of such constraints are must-link (indicating that two instances belong to the same group) and cannot-link (two instances definitely do not belong together). The research area of constrained clustering has grown significantly over the years with a large variety of new algorithms and more advanced types of constraints being proposed. However, no unifying overview is available to easily understand the wide variety of available methods, constraints and benchmarks. To remedy this, this study presents in-detail the background of constrained clustering and provides a novel ranked taxonomy of the types of constraints that can be used in constrained clustering. In addition, it focuses on the instance-level pairwise constraints, and gives an overview of its applications and its historical context. Finally, it presents a statistical analysis covering 307 constrained clustering methods, categorizes them according to their features, and provides a ranking score indicating which methods have the most potential based on their popularity and validation quality. Finally, based upon this analysis, potential pitfalls and future research directions are provided.
Semi-supervised Clustering with Two Types of Background Knowledge: Fusing Pairwise Constraints and Monotonicity Constraints
Feb 25, 2023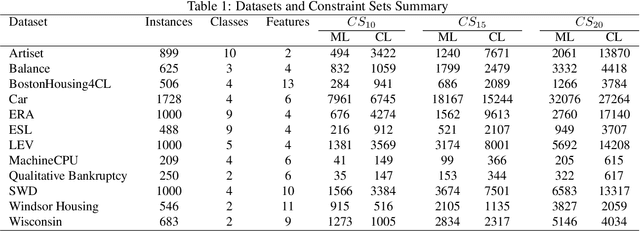


This study addresses the problem of performing clustering in the presence of two types of background knowledge: pairwise constraints and monotonicity constraints. To achieve this, the formal framework to perform clustering under monotonicity constraints is, firstly, defined, resulting in a specific distance measure. Pairwise constraints are integrated afterwards by designing an objective function which combines the proposed distance measure and a pairwise constraint-based penalty term, in order to fuse both types of information. This objective function can be optimized with an EM optimization scheme. The proposed method serves as the first approach to the problem it addresses, as it is the first method designed to work with the two types of background knowledge mentioned above. Our proposal is tested in a variety of benchmark datasets and in a real-world case of study.
Handling Imbalanced Classification Problems With Support Vector Machines via Evolutionary Bilevel Optimization
Apr 21, 2022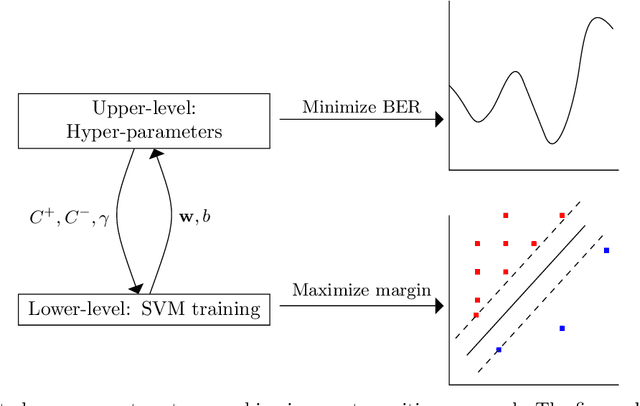
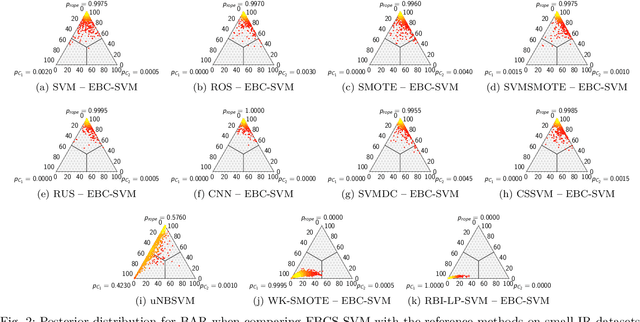
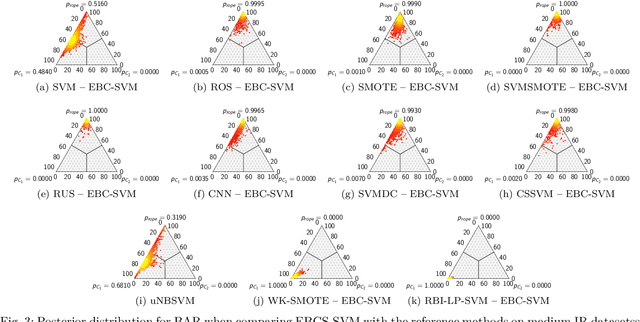
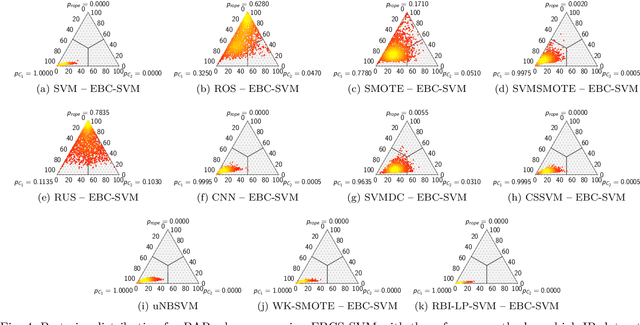
Support vector machines (SVMs) are popular learning algorithms to deal with binary classification problems. They traditionally assume equal misclassification costs for each class; however, real-world problems may have an uneven class distribution. This article introduces EBCS-SVM: evolutionary bilevel cost-sensitive SVMs. EBCS-SVM handles imbalanced classification problems by simultaneously learning the support vectors and optimizing the SVM hyperparameters, which comprise the kernel parameter and misclassification costs. The resulting optimization problem is a bilevel problem, where the lower level determines the support vectors and the upper level the hyperparameters. This optimization problem is solved using an evolutionary algorithm (EA) at the upper level and sequential minimal optimization (SMO) at the lower level. These two methods work in a nested fashion, that is, the optimal support vectors help guide the search of the hyperparameters, and the lower level is initialized based on previous successful solutions. The proposed method is assessed using 70 datasets of imbalanced classification and compared with several state-of-the-art methods. The experimental results, supported by a Bayesian test, provided evidence of the effectiveness of EBCS-SVM when working with highly imbalanced datasets.
* Copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Fuzzy k-Nearest Neighbors with monotonicity constraints: Moving towards the robustness of monotonic noise
Mar 05, 2020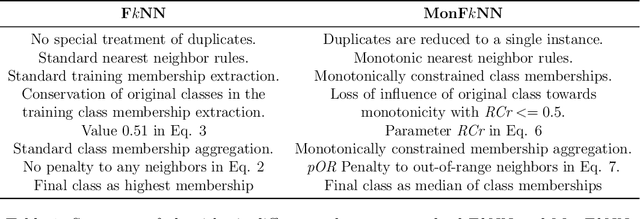
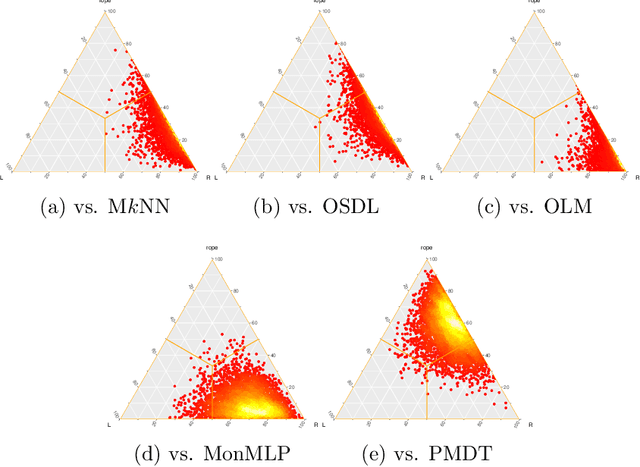
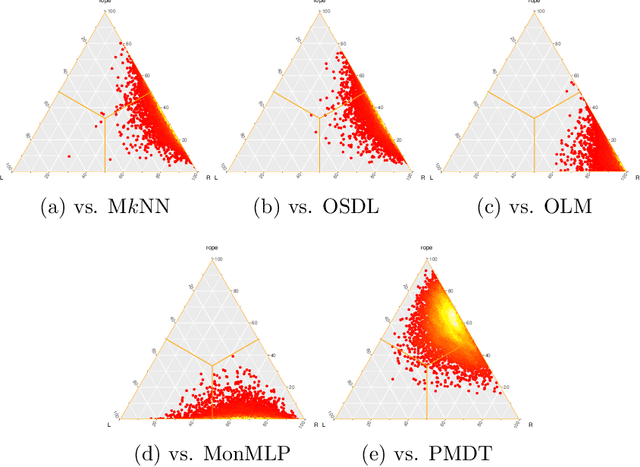
This paper proposes a new model based on Fuzzy k-Nearest Neighbors for classification with monotonic constraints, Monotonic Fuzzy k-NN (MonFkNN). Real-life data-sets often do not comply with monotonic constraints due to class noise. MonFkNN incorporates a new calculation of fuzzy memberships, which increases robustness against monotonic noise without the need for relabeling. Our proposal has been designed to be adaptable to the different needs of the problem being tackled. In several experimental studies, we show significant improvements in accuracy while matching the best degree of monotonicity obtained by comparable methods. We also show that MonFkNN empirically achieves improved performance compared with Monotonic k-NN in the presence of large amounts of class noise.
Comprehensive Taxonomies of Nature- and Bio-inspired Optimization: Inspiration versus Algorithmic Behavior, Critical Analysis and Recommendations
Feb 20, 2020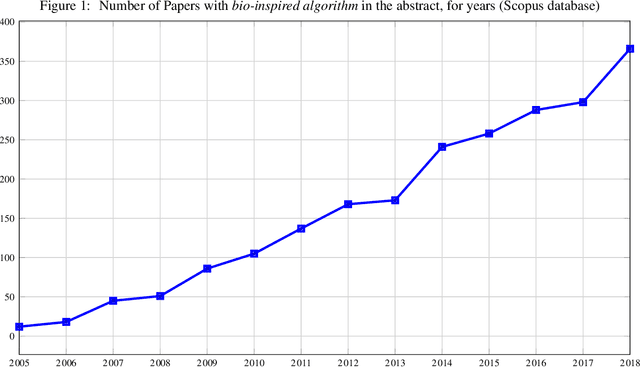
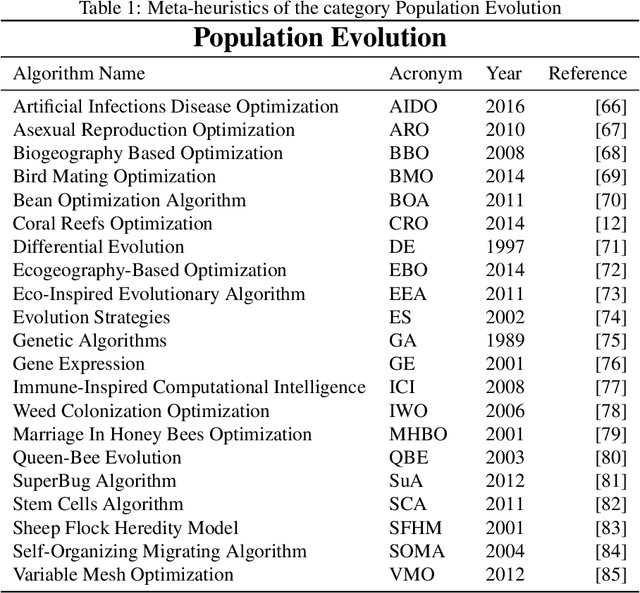
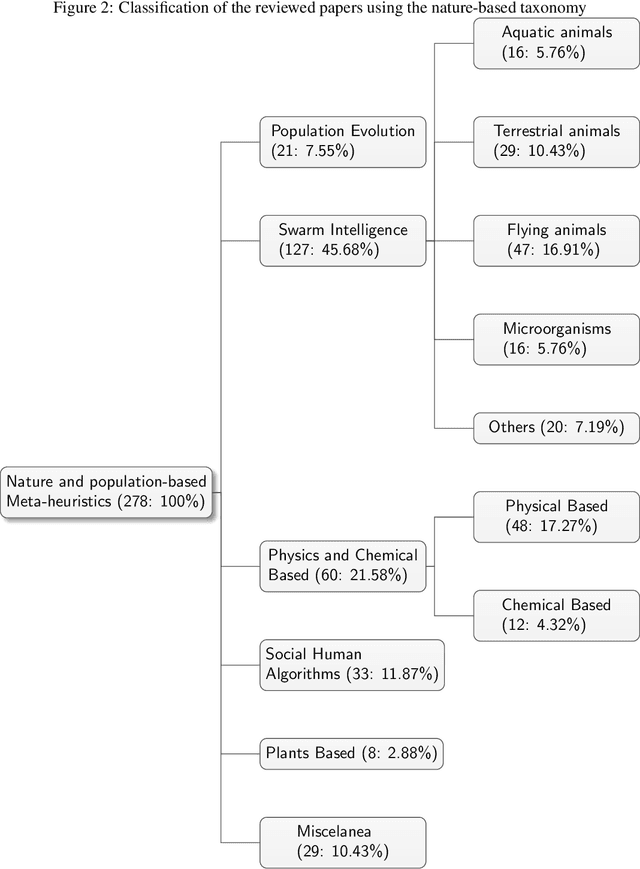
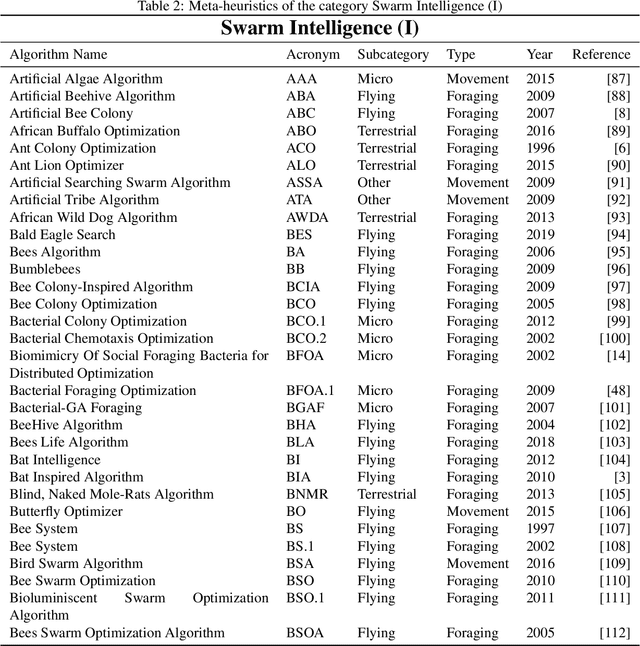
In recent years, a great variety of nature- and bio-inspired algorithms has been reported in the literature. This algorithmic family simulates different biological processes observed in Nature in order to efficiently address complex optimization problems. In the last years the number of bio-inspired optimization approaches in literature has grown considerably, reaching unprecedented levels that dark the future prospects of this field of research. This paper addresses this problem by proposing two comprehensive, principle-based taxonomies that allow researchers to organize existing and future algorithmic developments into well-defined categories, considering two different criteria: the source of inspiration and the behavior of each algorithm. Using these taxonomies we review more than three hundred publications dealing with nature-inspired and bio-inspired algorithms, and proposals falling within each of these categories are examined, leading to a critical summary of design trends and similarities between them, and the identification of the most similar classical algorithm for each reviewed paper. From our analysis we conclude that a poor relationship is often found between the natural inspiration of an algorithm and its behavior. Furthermore, similarities in terms of behavior between different algorithms are greater than what is claimed in their public disclosure: specifically, we show that more than one-third of the reviewed bio-inspired solvers are versions of classical algorithms. Grounded on the conclusions of our critical analysis, we give several recommendations and points of improvement for better methodological practices in this active and growing research field.
Smart Data based Ensemble for Imbalanced Big Data Classification
Jan 16, 2020

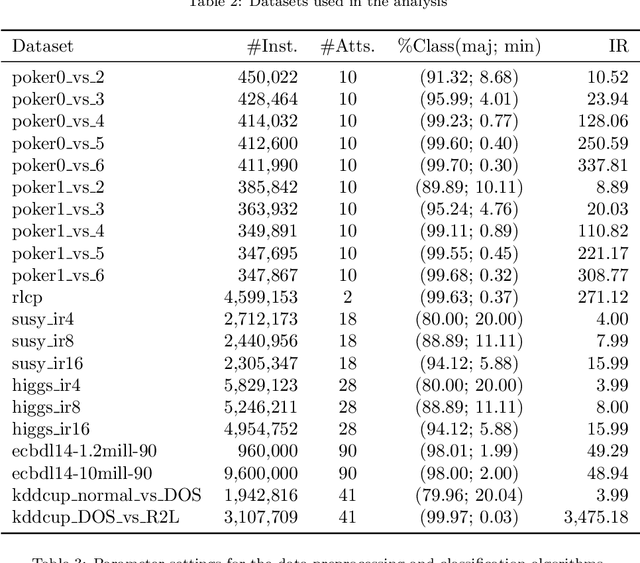
Big Data scenarios pose a new challenge to traditional data mining algorithms, since they are not prepared to work with such amount of data. Smart Data refers to data of enough quality to improve the outcome from a data mining algorithm. Existing data mining algorithms unability to handle Big Datasets prevents the transition from Big to Smart Data. Automation in data acquisition that characterizes Big Data also brings some problems, such as differences in data size per class. This will lead classifiers to lean towards the most represented classes. This problem is known as imbalanced data distribution, where one class is underrepresented in the dataset. Ensembles of classifiers are machine learning methods that improve the performance of a single base classifier by the combination of several of them. Ensembles are not exempt from the imbalanced classification problem. To deal with this issue, the ensemble method have to be designed specifically. In this paper, a data preprocessing ensemble for imbalanced Big Data classification is presented, with focus on two-class problems. Experiments carried out in 21 Big Datasets have proved that our ensemble classifier outperforms classic machine learning models with an added data balancing method, such as Random Forests.
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
Oct 22, 2019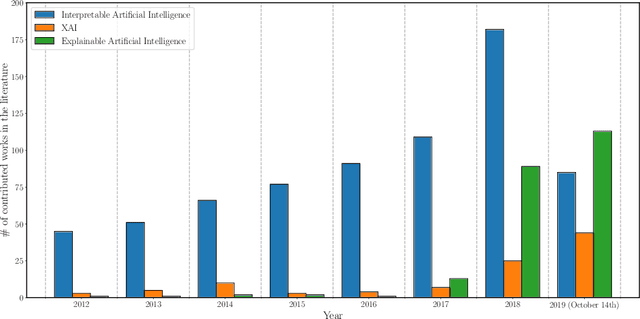
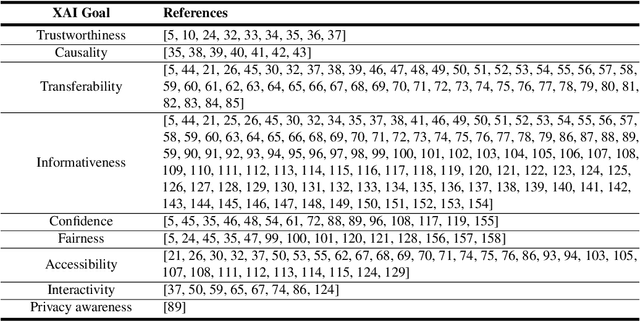
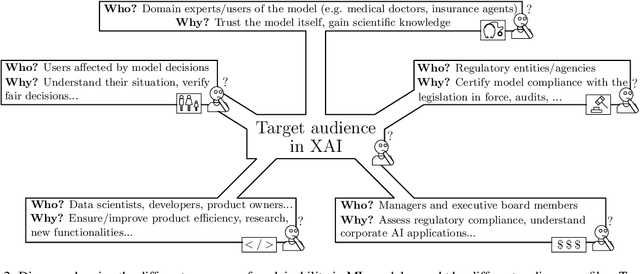

In the last years, Artificial Intelligence (AI) has achieved a notable momentum that may deliver the best of expectations over many application sectors across the field. For this to occur, the entire community stands in front of the barrier of explainability, an inherent problem of AI techniques brought by sub-symbolism (e.g. ensembles or Deep Neural Networks) that were not present in the last hype of AI. Paradigms underlying this problem fall within the so-called eXplainable AI (XAI) field, which is acknowledged as a crucial feature for the practical deployment of AI models. This overview examines the existing literature in the field of XAI, including a prospect toward what is yet to be reached. We summarize previous efforts to define explainability in Machine Learning, establishing a novel definition that covers prior conceptual propositions with a major focus on the audience for which explainability is sought. We then propose and discuss about a taxonomy of recent contributions related to the explainability of different Machine Learning models, including those aimed at Deep Learning methods for which a second taxonomy is built. This literature analysis serves as the background for a series of challenges faced by XAI, such as the crossroads between data fusion and explainability. Our prospects lead toward the concept of Responsible Artificial Intelligence, namely, a methodology for the large-scale implementation of AI methods in real organizations with fairness, model explainability and accountability at its core. Our ultimate goal is to provide newcomers to XAI with a reference material in order to stimulate future research advances, but also to encourage experts and professionals from other disciplines to embrace the benefits of AI in their activity sectors, without any prior bias for its lack of interpretability.