 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlined Framework for Agile Forecasting Model Development towards Efficient Inventory Management
Apr 13, 2023This paper proposes a framework for developing forecasting models by streamlining the connections between core components of the developmental process. The proposed framework enables swift and robust integration of new datasets, experimentation on different algorithms, and selection of the best models. We start with the datasets of different issues and apply pre-processing steps to clean and engineer meaningful representations of time-series data. To identify robust training configurations, we introduce a novel mechanism of multiple cross-validation strategies. We apply different evaluation metrics to find the best-suited models for varying applications. One of the referent applications is our participation in the intelligent forecasting competition held by the United States Agency of International Development (USAID). Finally, we leverage the flexibility of the framework by applying different evaluation metrics to assess the performance of the models in inventory management settings.
Interpretable estimation of the risk of heart failure hospitalization from a 30-second electrocardiogram
Nov 04, 2022



Survival modeling in healthcare relies on explainable statistical models; yet, their underlying assumptions are often simplistic and, thus, unrealistic. Machine learning models can estimate more complex relationships and lead to more accurate predictions, but are non-interpretable. This study shows it is possible to estimate hospitalization for congestive heart failure by a 30 seconds single-lead electrocardiogram signal. Using a machine learning approach not only results in greater predictive power but also provides clinically meaningful interpretations. We train an eXtreme Gradient Boosting accelerated failure time model and exploit SHapley Additive exPlanations values to explain the effect of each feature on predictions. Our model achieved a concordance index of 0.828 and an area under the curve of 0.853 at one year and 0.858 at two years on a held-out test set of 6,573 patients. These results show that a rapid test based on an electrocardiogram could be crucial in targeting and treating high-risk individuals.
Fuzzy k-Nearest Neighbors with monotonicity constraints: Moving towards the robustness of monotonic noise
Mar 05, 2020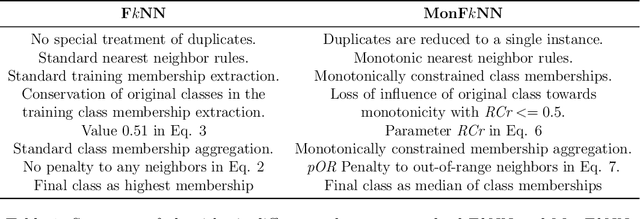
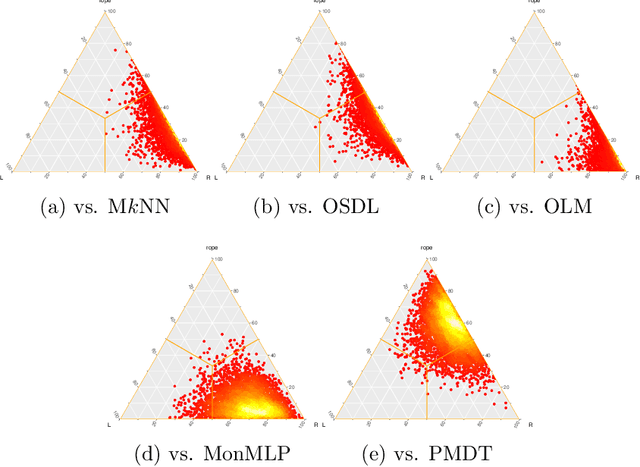
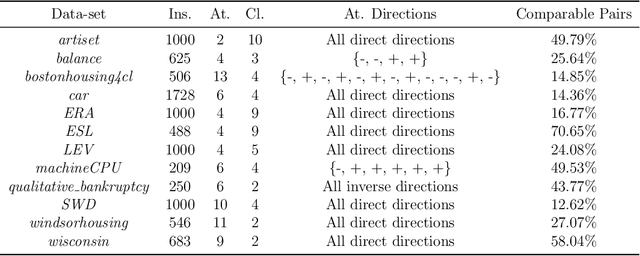
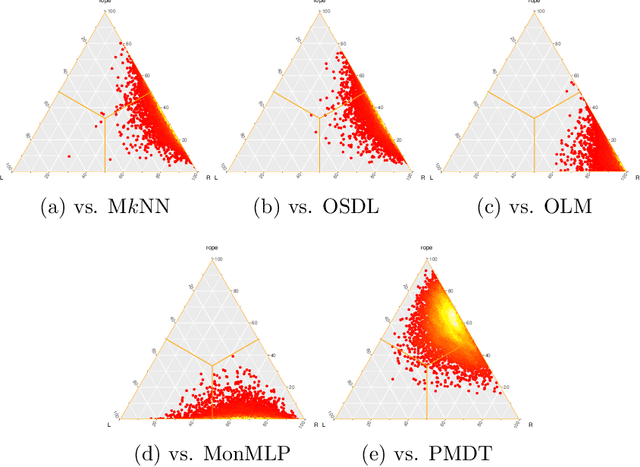
This paper proposes a new model based on Fuzzy k-Nearest Neighbors for classification with monotonic constraints, Monotonic Fuzzy k-NN (MonFkNN). Real-life data-sets often do not comply with monotonic constraints due to class noise. MonFkNN incorporates a new calculation of fuzzy memberships, which increases robustness against monotonic noise without the need for relabeling. Our proposal has been designed to be adaptable to the different needs of the problem being tackled. In several experimental studies, we show significant improvements in accuracy while matching the best degree of monotonicity obtained by comparable methods. We also show that MonFkNN empirically achieves improved performance compared with Monotonic k-NN in the presence of large amounts of class noise.