 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Geometric Temporal Dynamics for Face Anti-Spoofing
Jun 25, 2023



Face anti-spoofing (FAS) is indispensable for a face recognition system. Many texture-driven countermeasures were developed against presentation attacks (PAs), but the performance against unseen domains or unseen spoofing types is still unsatisfactory. Instead of exhaustively collecting all the spoofing variations and making binary decisions of live/spoof, we offer a new perspective on the FAS task to distinguish between normal and abnormal movements of live and spoof presentations. We propose Geometry-Aware Interaction Network (GAIN), which exploits dense facial landmarks with spatio-temporal graph convolutional network (ST-GCN) to establish a more interpretable and modularized FAS model. Additionally, with our cross-attention feature interaction mechanism, GAIN can be easily integrated with other existing methods to significantly boost performance. Our approach achieves state-of-the-art performance in the standard intra- and cross-dataset evaluations. Moreover, our model outperforms state-of-the-art methods by a large margin in the cross-dataset cross-type protocol on CASIA-SURF 3DMask (+10.26% higher AUC score), exhibiting strong robustness against domain shifts and unseen spoofing types.
Kinship Representation Learning with Face Componential Relation
Apr 22, 2023Kinship recognition aims to determine whether the subjects in two facial images are kin or non-kin, which is an emerging and challenging problem. However, most previous methods focus on heuristic designs without considering the spatial correlation between face images. In this paper, we aim to learn discriminative kinship representations embedded with the relation information between face components (e.g., eyes, nose, etc.). To achieve this goal, we propose the Face Componential Relation Network, which learns the relationship between face components among images with a cross-attention mechanism, which automatically learns the important facial regions for kinship recognition. Moreover, we propose Face Componential Relation Network (FaCoRNet), which adapts the loss function by the guidance from cross-attention to learn more discriminative feature representations. The proposed FaCoRNet outperforms previous state-of-the-art methods by large margins for the largest public kinship recognition FIW benchmark. The code will be publicly released upon acceptance.
Streamlined Framework for Agile Forecasting Model Development towards Efficient Inventory Management
Apr 13, 2023



This paper proposes a framework for developing forecasting models by streamlining the connections between core components of the developmental process. The proposed framework enables swift and robust integration of new datasets, experimentation on different algorithms, and selection of the best models. We start with the datasets of different issues and apply pre-processing steps to clean and engineer meaningful representations of time-series data. To identify robust training configurations, we introduce a novel mechanism of multiple cross-validation strategies. We apply different evaluation metrics to find the best-suited models for varying applications. One of the referent applications is our participation in the intelligent forecasting competition held by the United States Agency of International Development (USAID). Finally, we leverage the flexibility of the framework by applying different evaluation metrics to assess the performance of the models in inventory management settings.
Development of a deep learning-based tool to assist wound classification
Mar 29, 2023



This paper presents a deep learning-based wound classification tool that can assist medical personnel in non-wound care specialization to classify five key wound conditions, namely deep wound, infected wound, arterial wound, venous wound, and pressure wound, given color images captured using readily available cameras. The accuracy of the classification is vital for appropriate wound management. The proposed wound classification method adopts a multi-task deep learning framework that leverages the relationships among the five key wound conditions for a unified wound classification architecture. With differences in Cohen's kappa coefficients as the metrics to compare our proposed model with humans, the performance of our model was better or non-inferior to those of all human medical personnel. Our convolutional neural network-based model is the first to classify five tasks of deep, infected, arterial, venous, and pressure wounds simultaneously with good accuracy. The proposed model is compact and matches or exceeds the performance of human doctors and nurses. Medical personnel who do not specialize in wound care can potentially benefit from an app equipped with the proposed deep learning model.
Interpretable estimation of the risk of heart failure hospitalization from a 30-second electrocardiogram
Nov 04, 2022



Survival modeling in healthcare relies on explainable statistical models; yet, their underlying assumptions are often simplistic and, thus, unrealistic. Machine learning models can estimate more complex relationships and lead to more accurate predictions, but are non-interpretable. This study shows it is possible to estimate hospitalization for congestive heart failure by a 30 seconds single-lead electrocardiogram signal. Using a machine learning approach not only results in greater predictive power but also provides clinically meaningful interpretations. We train an eXtreme Gradient Boosting accelerated failure time model and exploit SHapley Additive exPlanations values to explain the effect of each feature on predictions. Our model achieved a concordance index of 0.828 and an area under the curve of 0.853 at one year and 0.858 at two years on a held-out test set of 6,573 patients. These results show that a rapid test based on an electrocardiogram could be crucial in targeting and treating high-risk individuals.
A Mixed-Domain Self-Attention Network for Multilabel Cardiac Irregularity Classification Using Reduced-Lead Electrocardiogram
Apr 29, 2022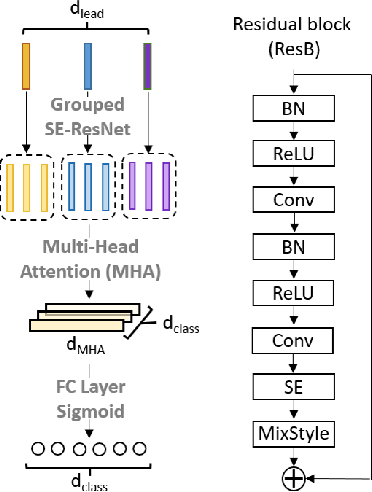
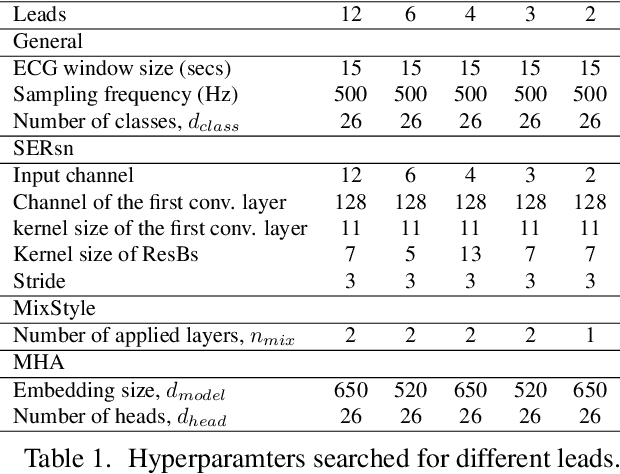
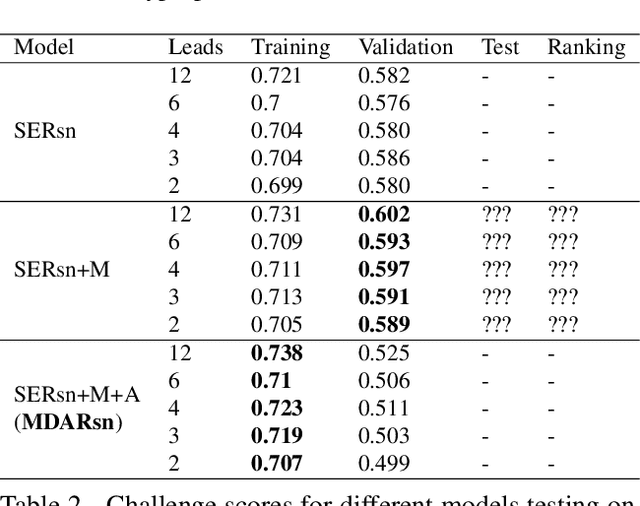
Electrocardiogram(ECG) is commonly used to detect cardiac irregularities such as atrial fibrillation, bradycardia, and other irregular complexes. While previous studies have achieved great accomplishment classifying these irregularities with standard 12-lead ECGs, there existed limited evidence demonstrating the utility of reduced-lead ECGs in capturing a wide-range of diagnostic information. In addition, classification model's generalizability across multiple recording sources also remained uncovered. As part of the PhysioNet Computing in Cardiology Challenge 2021, our team HaoWan AIeC, proposed Mixed-Domain Self-Attention Resnet (MDARsn) to identify cardiac abnormalities from reduced-lead ECG. Our classifiers received scores of 0.602, 0.593, 0.597, 0.591, and 0.589 (ranked 54th, 37th, 38th, 38th, and 39th) for the 12-lead, 6-lead, 4-lead, 3-lead, and 2-lead versions of the hidden validation set with the evaluation metric defined by the challenge.
Domain-Generalized Textured Surface Anomaly Detection
Mar 23, 2022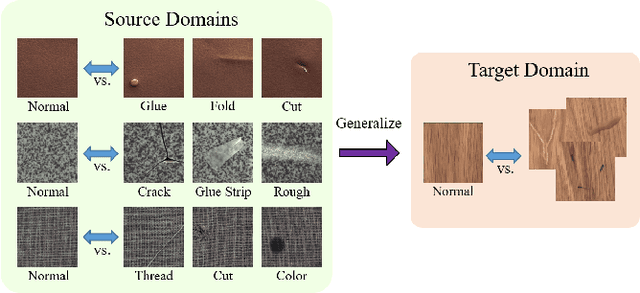
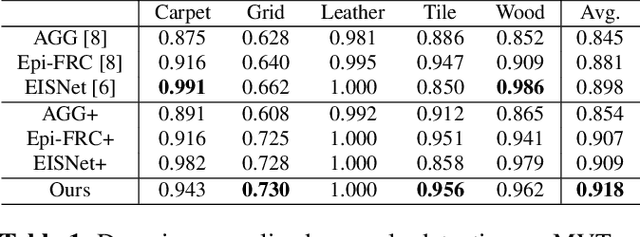
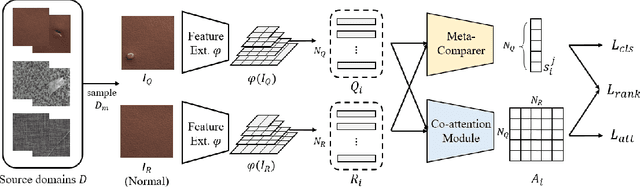
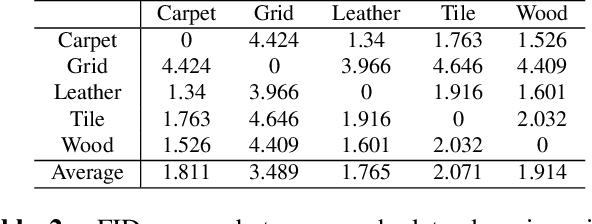
Anomaly detection aims to identify abnormal data that deviates from the normal ones, while typically requiring a sufficient amount of normal data to train the model for performing this task. Despite the success of recent anomaly detection methods, performing anomaly detection in an unseen domain remain a challenging task. In this paper, we address the task of domain-generalized textured surface anomaly detection. By observing normal and abnormal surface data across multiple source domains, our model is expected to be generalized to an unseen textured surface of interest, in which only a small number of normal data can be observed during testing. Although with only image-level labels observed in the training data, our patch-based meta-learning model exhibits promising generalization ability: not only can it generalize to unseen image domains, but it can also localize abnormal regions in the query image. Our experiments verify that our model performs favorably against state-of-the-art anomaly detection and domain generalization approaches in various settings.
Transition Motion Tensor: A Data-Driven Approach for Versatile and Controllable Agents in Physically Simulated Environments
Nov 30, 2021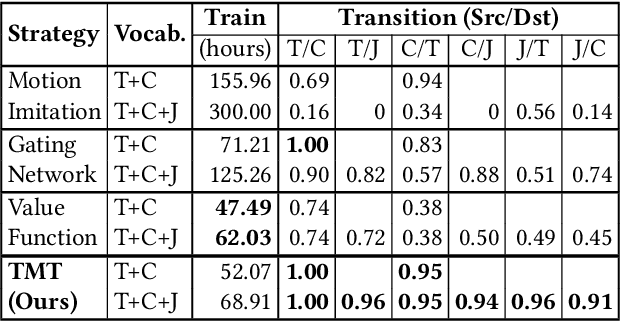
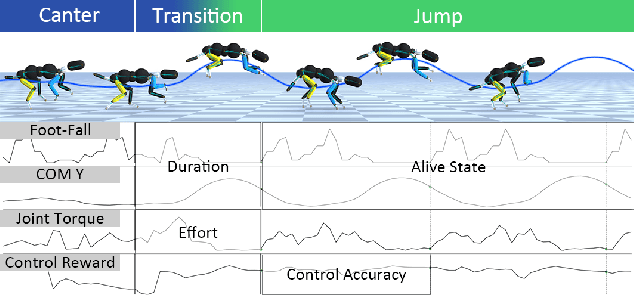
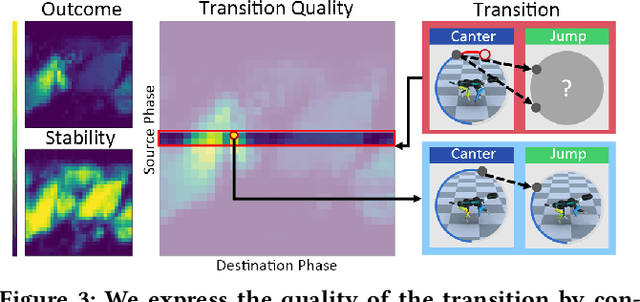
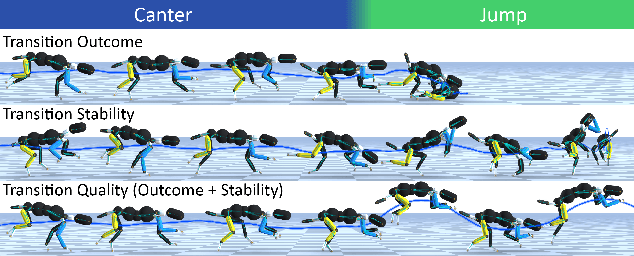
This paper proposes the Transition Motion Tensor, a data-driven framework that creates novel and physically accurate transitions outside of the motion dataset. It enables simulated characters to adopt new motion skills efficiently and robustly without modifying existing ones. Given several physically simulated controllers specializing in different motions, the tensor serves as a temporal guideline to transition between them. Through querying the tensor for transitions that best fit user-defined preferences, we can create a unified controller capable of producing novel transitions and solving complex tasks that may require multiple motions to work coherently. We apply our framework on both quadrupeds and bipeds, perform quantitative and qualitative evaluations on transition quality, and demonstrate its capability of tackling complex motion planning problems while following user control directives.
TrustMAE: A Noise-Resilient Defect Classification Framework using Memory-Augmented Auto-Encoders with Trust Regions
Dec 29, 2020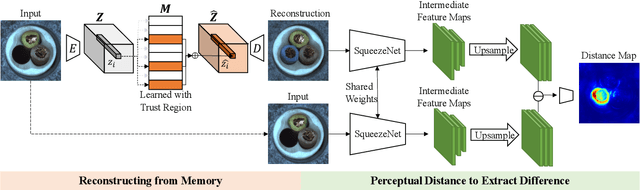
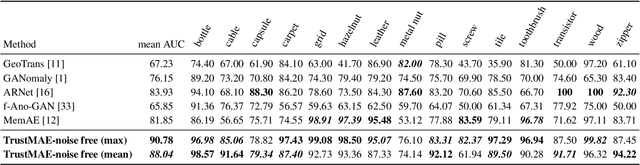
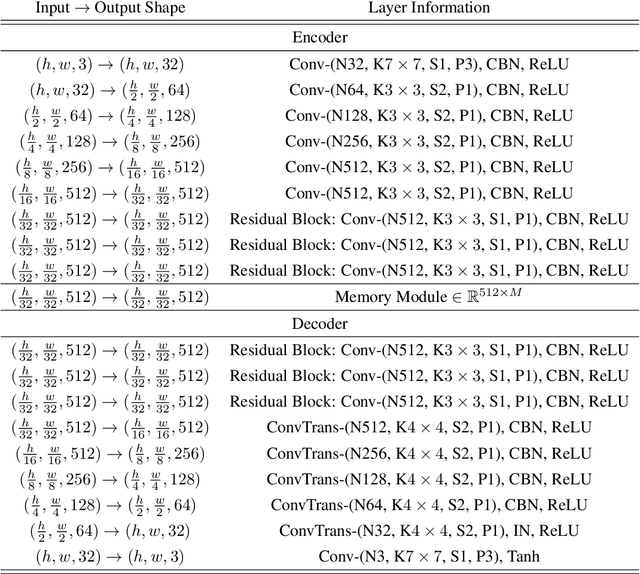
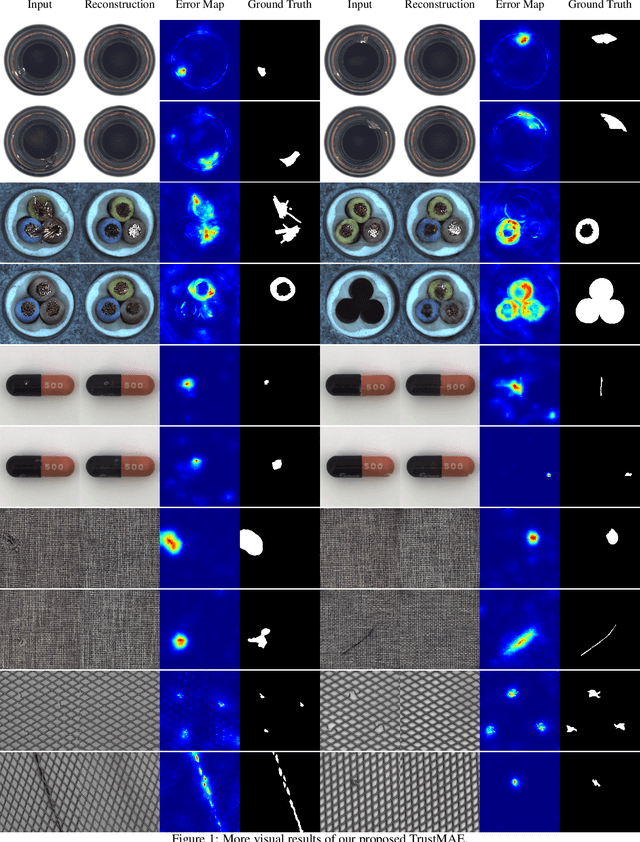
In this paper, we propose a framework called TrustMAE to address the problem of product defect classification. Instead of relying on defective images that are difficult to collect and laborious to label, our framework can accept datasets with unlabeled images. Moreover, unlike most anomaly detection methods, our approach is robust against noises, or defective images, in the training dataset. Our framework uses a memory-augmented auto-encoder with a sparse memory addressing scheme to avoid over-generalizing the auto-encoder, and a novel trust-region memory updating scheme to keep the noises away from the memory slots. The result is a framework that can reconstruct defect-free images and identify the defective regions using a perceptual distance network. When compared against various state-of-the-art baselines, our approach performs competitively under noise-free MVTec datasets. More importantly, it remains effective at a noise level up to 40% while significantly outperforming other baselines.
CARL: Controllable Agent with Reinforcement Learning for Quadruped Locomotion
May 11, 2020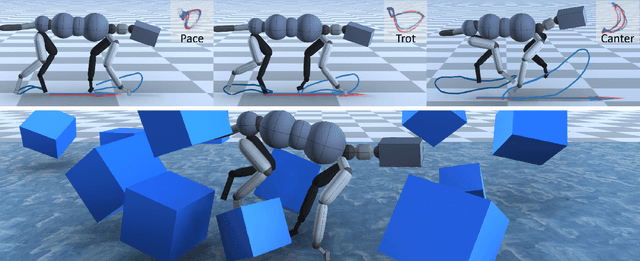
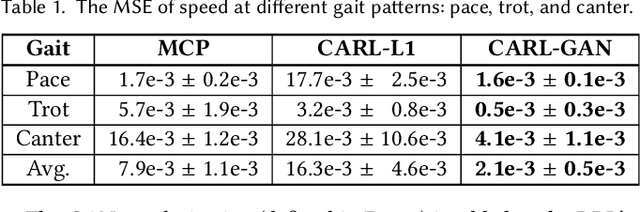
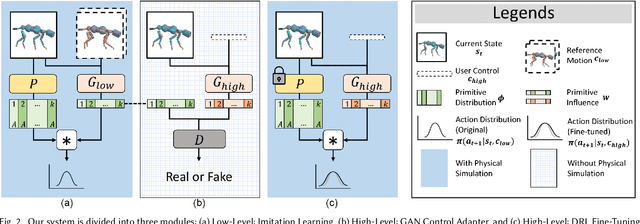
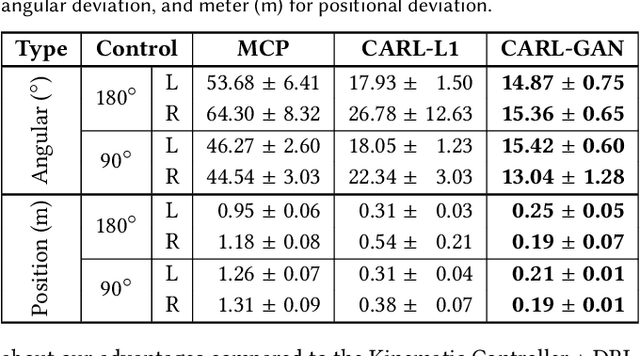
Motion synthesis in a dynamic environment has been a long-standing problem for character animation. Methods using motion capture data tend to scale poorly in complex environments because of their larger capturing and labeling requirement. Physics-based controllers are effective in this regard, albeit less controllable. In this paper, we present CARL, a quadruped agent that can be controlled with high-level directives and react naturally to dynamic environments. Starting with an agent that can imitate individual animation clips, we use Generative Adversarial Networks to adapt high-level controls, such as speed and heading, to action distributions that correspond to the original animations. Further fine-tuning through the deep reinforcement learning enables the agent to recover from unseen external perturbations while producing smooth transitions. It then becomes straightforward to create autonomous agents in dynamic environments by adding navigation modules over the entire process. We evaluate our approach by measuring the agent's ability to follow user control and provide a visual analysis of the generated motion to show its effectiveness.