 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNFiLD-inlet: Synthetic Turbulence Inflow Using Generative Latent Diffusion Models with Neural Fields
Nov 21, 2024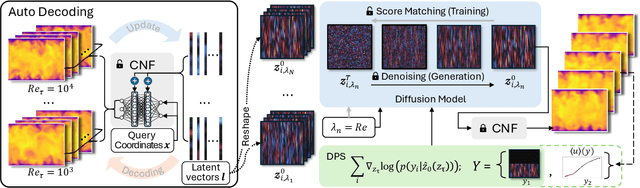
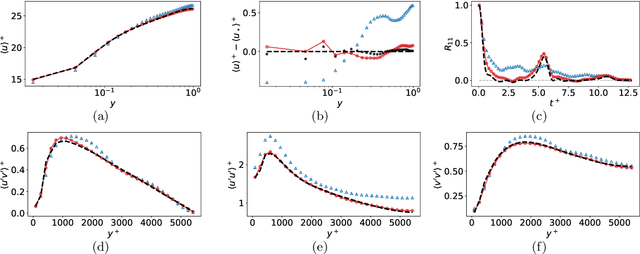
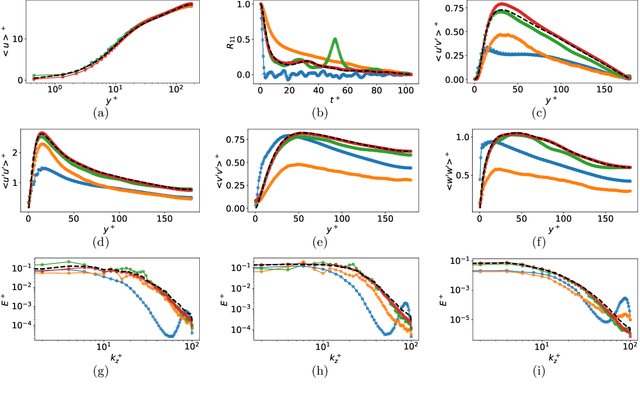
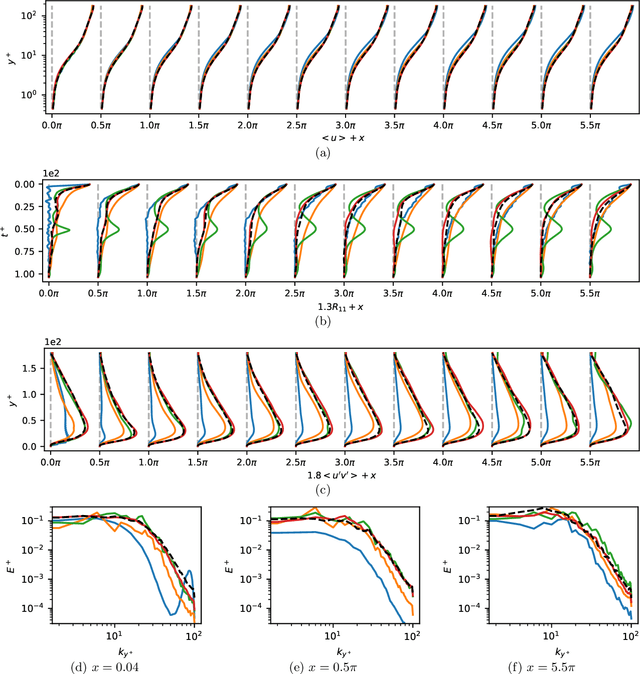
Eddy-resolving turbulence simulations require stochastic inflow conditions that accurately replicate the complex, multi-scale structures of turbulence. Traditional recycling-based methods rely on computationally expensive precursor simulations, while existing synthetic inflow generators often fail to reproduce realistic coherent structures of turbulence. Recent advances in deep learning (DL) have opened new possibilities for inflow turbulence generation, yet many DL-based methods rely on deterministic, autoregressive frameworks prone to error accumulation, resulting in poor robustness for long-term predictions. In this work, we present CoNFiLD-inlet, a novel DL-based inflow turbulence generator that integrates diffusion models with a conditional neural field (CNF)-encoded latent space to produce realistic, stochastic inflow turbulence. By parameterizing inflow conditions using Reynolds numbers, CoNFiLD-inlet generalizes effectively across a wide range of Reynolds numbers ($Re_\tau$ between $10^3$ and $10^4$) without requiring retraining or parameter tuning. Comprehensive validation through a priori and a posteriori tests in Direct Numerical Simulation (DNS) and Wall-Modeled Large Eddy Simulation (WMLES) demonstrates its high fidelity, robustness, and scalability, positioning it as an efficient and versatile solution for inflow turbulence synthesis.
Rational-WENO: A lightweight, physically-consistent three-point weighted essentially non-oscillatory scheme
Sep 13, 2024



Conventional WENO3 methods are known to be highly dissipative at lower resolutions, introducing significant errors in the pre-asymptotic regime. In this paper, we employ a rational neural network to accurately estimate the local smoothness of the solution, dynamically adapting the stencil weights based on local solution features. As rational neural networks can represent fast transitions between smooth and sharp regimes, this approach achieves a granular reconstruction with significantly reduced dissipation, improving the accuracy of the simulation. The network is trained offline on a carefully chosen dataset of analytical functions, bypassing the need for differentiable solvers. We also propose a robust model selection criterion based on estimates of the interpolation's convergence order on a set of test functions, which correlates better with the model performance in downstream tasks. We demonstrate the effectiveness of our approach on several one-, two-, and three-dimensional fluid flow problems: our scheme generalizes across grid resolutions while handling smooth and discontinuous solutions. In most cases, our rational network-based scheme achieves higher accuracy than conventional WENO3 with the same stencil size, and in a few of them, it achieves accuracy comparable to WENO5, which uses a larger stencil.
Development of a deep learning-based tool to assist wound classification
Mar 29, 2023



This paper presents a deep learning-based wound classification tool that can assist medical personnel in non-wound care specialization to classify five key wound conditions, namely deep wound, infected wound, arterial wound, venous wound, and pressure wound, given color images captured using readily available cameras. The accuracy of the classification is vital for appropriate wound management. The proposed wound classification method adopts a multi-task deep learning framework that leverages the relationships among the five key wound conditions for a unified wound classification architecture. With differences in Cohen's kappa coefficients as the metrics to compare our proposed model with humans, the performance of our model was better or non-inferior to those of all human medical personnel. Our convolutional neural network-based model is the first to classify five tasks of deep, infected, arterial, venous, and pressure wounds simultaneously with good accuracy. The proposed model is compact and matches or exceeds the performance of human doctors and nurses. Medical personnel who do not specialize in wound care can potentially benefit from an app equipped with the proposed deep learning model.
Next Day Wildfire Spread: A Machine Learning Data Set to Predict Wildfire Spreading from Remote-Sensing Data
Dec 04, 2021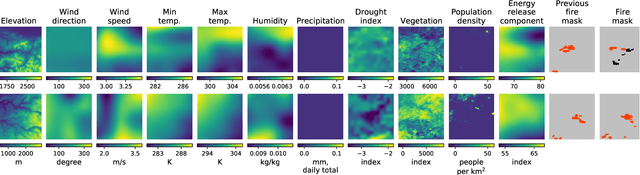
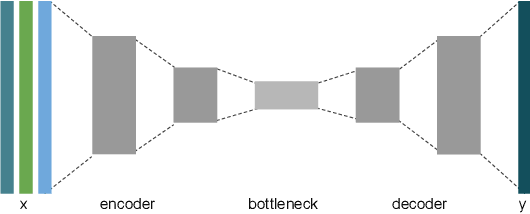
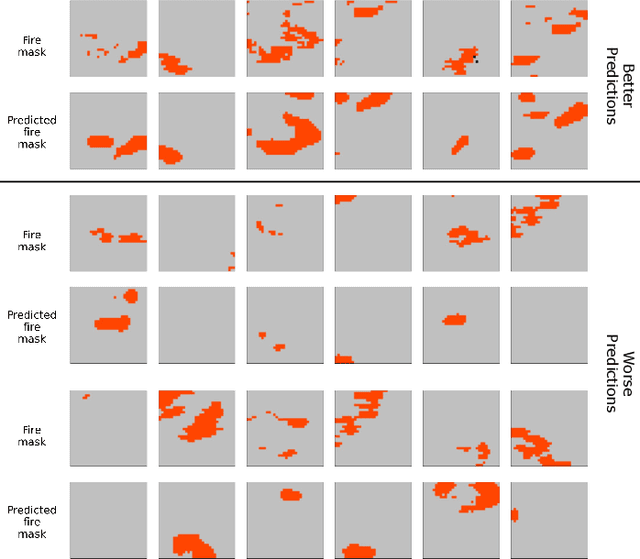
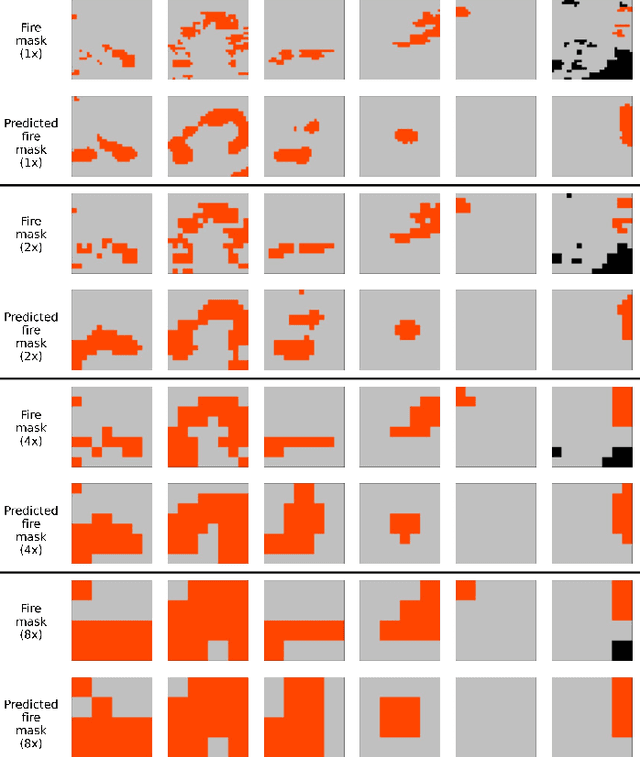
Predicting wildfire spread is critical for land management and disaster preparedness. To this end, we present `Next Day Wildfire Spread,' a curated, large-scale, multivariate data set of historical wildfires aggregating nearly a decade of remote-sensing data across the United States. In contrast to existing fire data sets based on Earth observation satellites, our data set combines 2D fire data with multiple explanatory variables (e.g., topography, vegetation, weather, drought index, population density) aligned over 2D regions, providing a feature-rich data set for machine learning. To demonstrate the usefulness of this data set, we implement a convolutional autoencoder that takes advantage of the spatial information of this data to predict wildfire spread. We compare the performance of the neural network with other machine learning models: logistic regression and random forest. This data set can be used as a benchmark for developing wildfire propagation models based on remote sensing data for a lead time of one day.
Deep Learning Models for Predicting Wildfires from Historical Remote-Sensing Data
Oct 15, 2020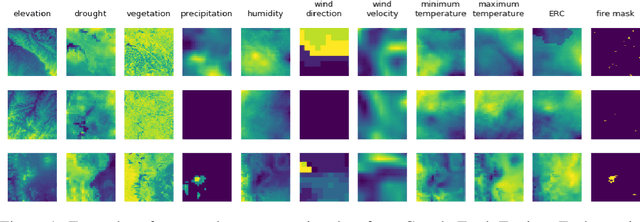
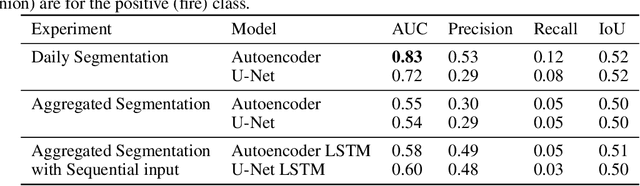
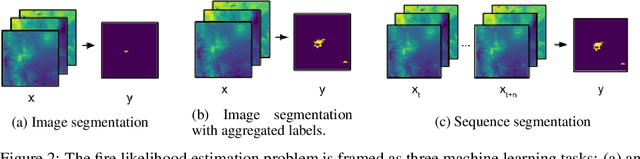

Identifying regions that have high likelihood for wildfires is a key component of land and forestry management and disaster preparedness. We create a data set by aggregating nearly a decade of remote-sensing data and historical fire records to predict wildfires. This prediction problem is framed as three machine learning tasks. Results are compared and analyzed for four different deep learning models to estimate wildfire likelihood. The results demonstrate that deep learning models can successfully identify areas of high fire likelihood using aggregated data about vegetation, weather, and topography with an AUC of 83%.
Scaling Up Collaborative Filtering Data Sets through Randomized Fractal Expansions
Apr 08, 2019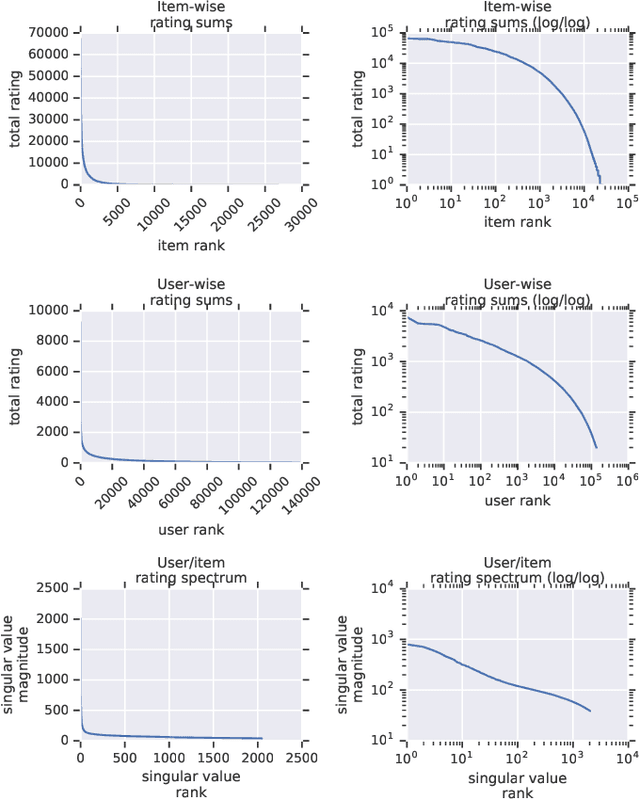
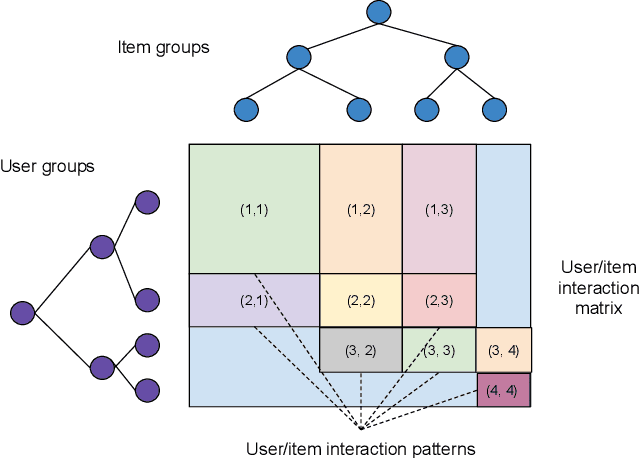
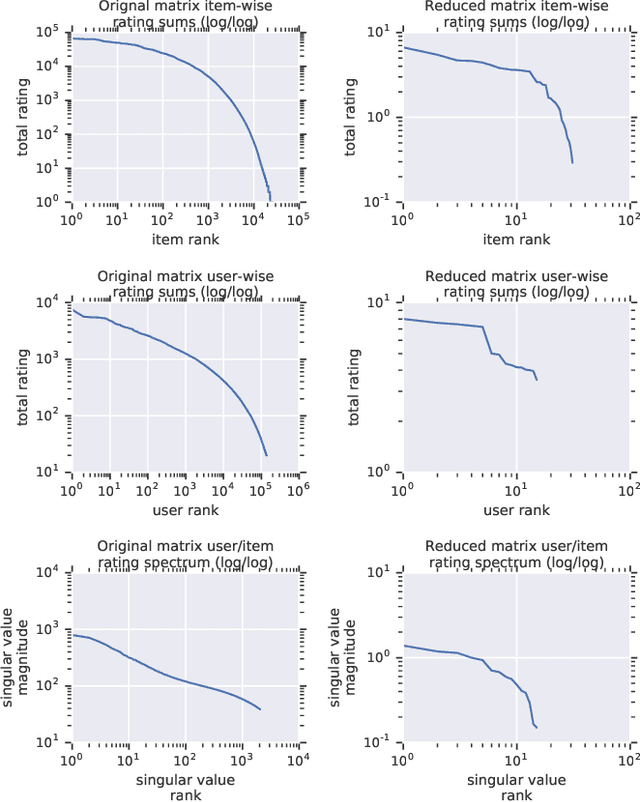
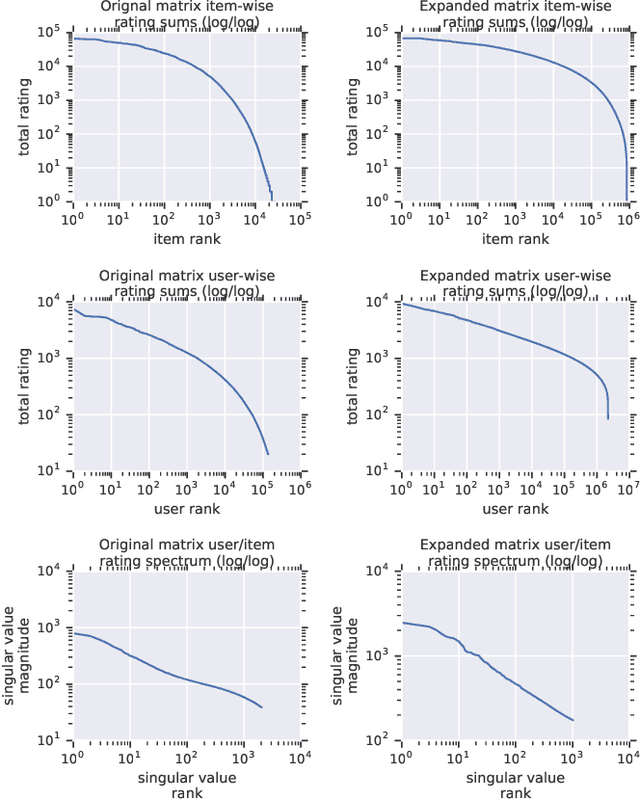
Recommender system research suffers from a disconnect between the size of academic data sets and the scale of industrial production systems. In order to bridge that gap, we propose to generate large-scale user/item interaction data sets by expanding pre-existing public data sets. Our key contribution is a technique that expands user/item incidence matrices matrices to large numbers of rows (users), columns (items), and non-zero values (interactions). The proposed method adapts Kronecker Graph Theory to preserve key higher order statistical properties such as the fat-tailed distribution of user engagements, item popularity, and singular value spectra of user/item interaction matrices. Preserving such properties is key to building large realistic synthetic data sets which in turn can be employed reliably to benchmark recommender systems and the systems employed to train them. We further apply our stochastic expansion algorithm to the binarized MovieLens 20M data set, which comprises 20M interactions between 27K movies and 138K users. The resulting expanded data set has 1.2B ratings, 2.2M users, and 855K items, which can be scaled up or down.
Scalable Realistic Recommendation Datasets through Fractal Expansions
Jan 23, 2019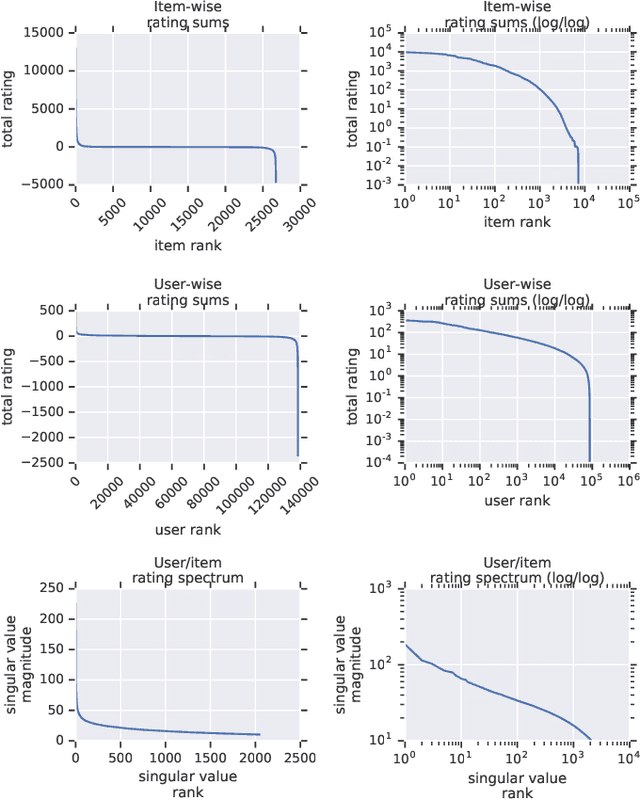
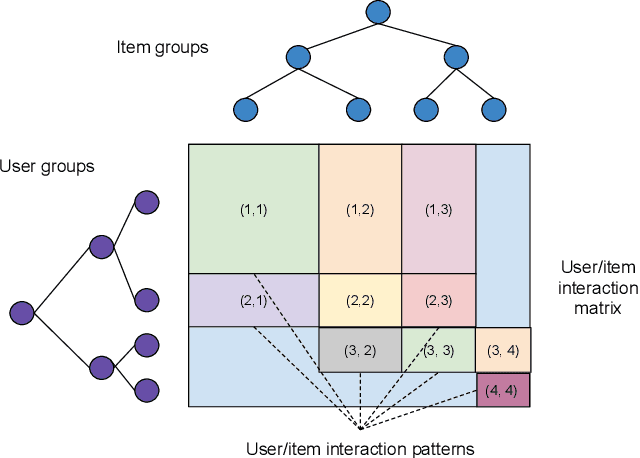
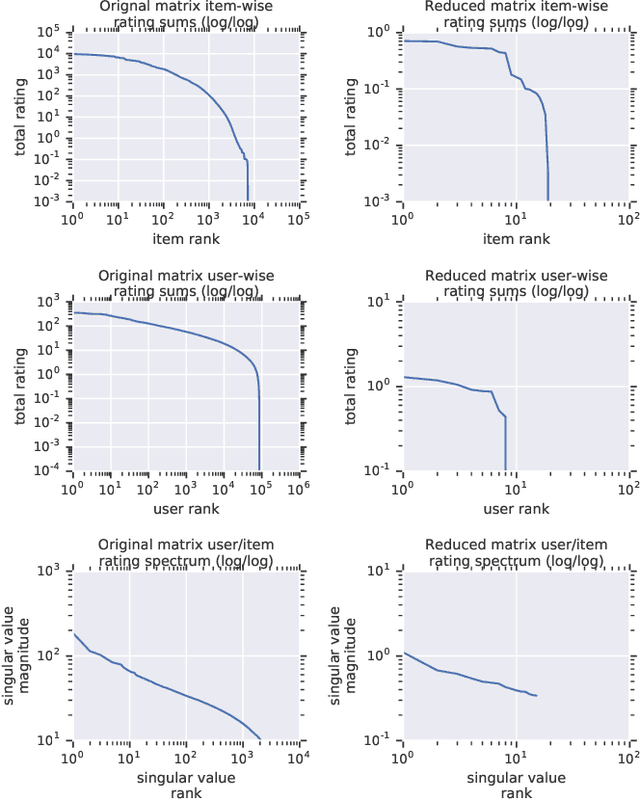
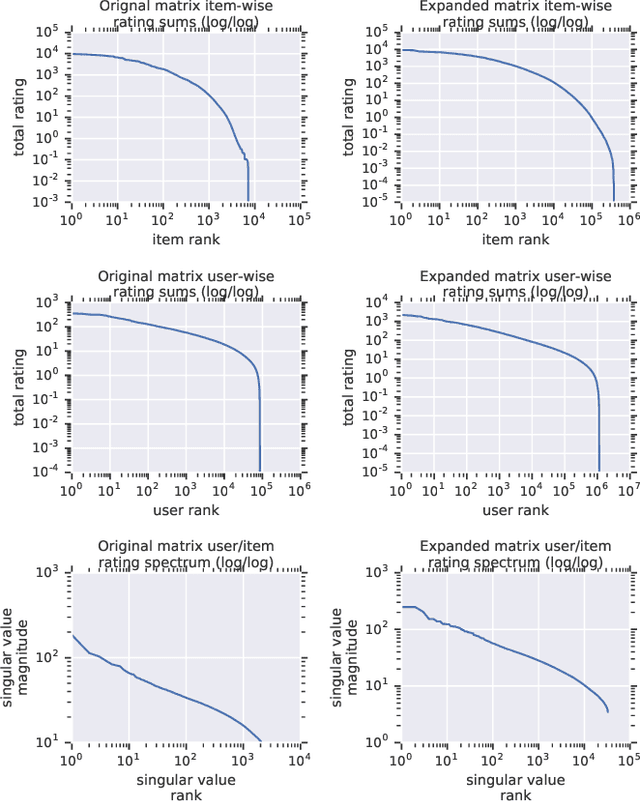
Recommender System research suffers currently from a disconnect between the size of academic data sets and the scale of industrial production systems. In order to bridge that gap we propose to generate more massive user/item interaction data sets by expanding pre-existing public data sets. User/item incidence matrices record interactions between users and items on a given platform as a large sparse matrix whose rows correspond to users and whose columns correspond to items. Our technique expands such matrices to larger numbers of rows (users), columns (items) and non zero values (interactions) while preserving key higher order statistical properties. We adapt the Kronecker Graph Theory to user/item incidence matrices and show that the corresponding fractal expansions preserve the fat-tailed distributions of user engagements, item popularity and singular value spectra of user/item interaction matrices. Preserving such properties is key to building large realistic synthetic data sets which in turn can be employed reliably to benchmark Recommender Systems and the systems employed to train them. We provide algorithms to produce such expansions and apply them to the MovieLens 20 million data set comprising 20 million ratings of 27K movies by 138K users. The resulting expanded data set has 10 billion ratings, 2 million items and 864K users in its smaller version and can be scaled up or down. A larger version features 655 billion ratings, 7 million items and 17 million users.