 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Brings the Frisbee: Probing Hidden Hallucination Factors in Large Vision-Language Model via Causality Analysis
Dec 04, 2024
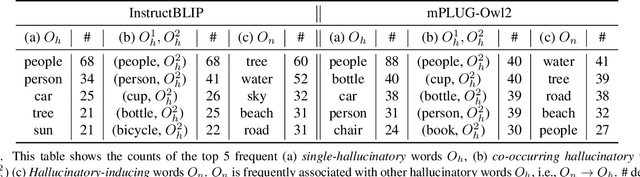

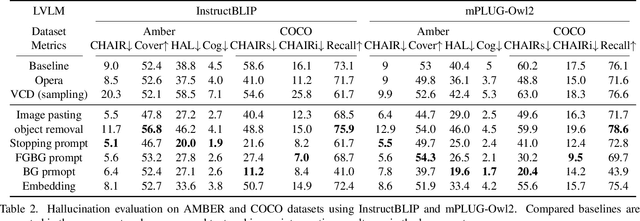
Recent advancements in large vision-language models (LVLM) have significantly enhanced their ability to comprehend visual inputs alongside natural language. However, a major challenge in their real-world application is hallucination, where LVLMs generate non-existent visual elements, eroding user trust. The underlying mechanism driving this multimodal hallucination is poorly understood. Minimal research has illuminated whether contexts such as sky, tree, or grass field involve the LVLM in hallucinating a frisbee. We hypothesize that hidden factors, such as objects, contexts, and semantic foreground-background structures, induce hallucination. This study proposes a novel causal approach: a hallucination probing system to identify these hidden factors. By analyzing the causality between images, text prompts, and network saliency, we systematically explore interventions to block these factors. Our experimental findings show that a straightforward technique based on our analysis can significantly reduce hallucinations. Additionally, our analyses indicate the potential to edit network internals to minimize hallucinated outputs.
Application of Disentanglement to Map Registration Problem
Aug 26, 2024Geospatial data come from various sources, such as satellites, aircraft, and LiDAR. The variability of the source is not limited to the types of data acquisition techniques, as we have maps from different time periods. To incorporate these data for a coherent analysis, it is essential to first align different "styles" of geospatial data to its matching images that point to the same location on the surface of the Earth. In this paper, we approach the image registration as a two-step process of (1) extracting geospatial contents invariant to visual (and any other non-content-related) information, and (2) matching the data based on such (purely) geospatial contents. We hypothesize that a combination of $\beta$-VAE-like architecture [2] and adversarial training will achieve both the disentanglement of the geographic information and artistic styles and generation of new map tiles by composing the encoded geographic information with any artistic style.
Comparison between the Structures of Word Co-occurrence and Word Similarity Networks for Ill-formed and Well-formed Texts in Taiwan Mandarin
Aug 18, 2024The study of word co-occurrence networks has attracted the attention of researchers due to their potential significance as well as applications. Understanding the structure of word co-occurrence networks is therefore important to fully realize their significance and usages. In past studies, word co-occurrence networks built on well-formed texts have been found to possess certain characteristics, including being small-world, following a two-regime power law distribution, and being generally disassortative. On the flip side, past studies have found that word co-occurrence networks built from ill-formed texts such as microblog posts may behave differently from those built from well-formed documents. While both kinds of word co-occurrence networks are small-world and disassortative, word co-occurrence networks built from ill-formed texts are scale-free and follow the power law distribution instead of the two-regime power law distribution. However, since past studies on the behavior of word co-occurrence networks built from ill-formed texts only investigated English, the universality of such characteristics remains to be seen among different languages. In addition, it is yet to be investigated whether there could be possible similitude/differences between word co-occurrence networks and other potentially comparable networks. This study therefore investigates and compares the structure of word co-occurrence networks and word similarity networks based on Taiwan Mandarin ill-formed internet forum posts and compare them with those built with well-formed judicial judgments, and seeks to find out whether the three aforementioned properties (scale-free, small-world, and disassortative) for ill-formed and well-formed texts are universal among different languages and between word co-occurrence and word similarity networks.
Learning with Instance-Dependent Noisy Labels by Anchor Hallucination and Hard Sample Label Correction
Jul 10, 2024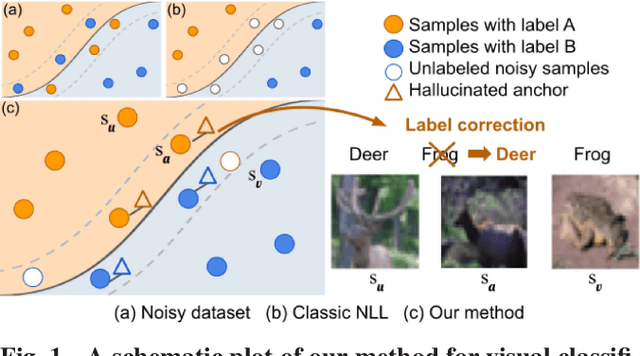



Learning from noisy-labeled data is crucial for real-world applications. Traditional Noisy-Label Learning (NLL) methods categorize training data into clean and noisy sets based on the loss distribution of training samples. However, they often neglect that clean samples, especially those with intricate visual patterns, may also yield substantial losses. This oversight is particularly significant in datasets with Instance-Dependent Noise (IDN), where mislabeling probabilities correlate with visual appearance. Our approach explicitly distinguishes between clean vs.noisy and easy vs. hard samples. We identify training samples with small losses, assuming they have simple patterns and correct labels. Utilizing these easy samples, we hallucinate multiple anchors to select hard samples for label correction. Corrected hard samples, along with the easy samples, are used as labeled data in subsequent semi-supervised training. Experiments on synthetic and real-world IDN datasets demonstrate the superior performance of our method over other state-of-the-art NLL methods.
Lightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023
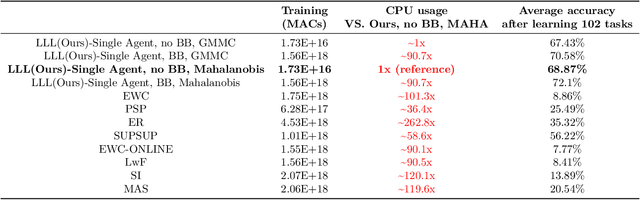

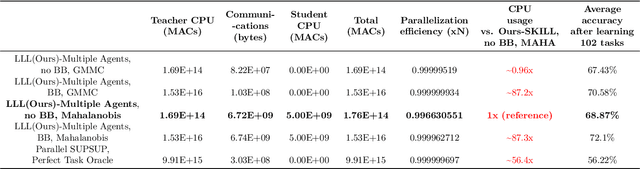
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning
Development of a deep learning-based tool to assist wound classification
Mar 29, 2023



This paper presents a deep learning-based wound classification tool that can assist medical personnel in non-wound care specialization to classify five key wound conditions, namely deep wound, infected wound, arterial wound, venous wound, and pressure wound, given color images captured using readily available cameras. The accuracy of the classification is vital for appropriate wound management. The proposed wound classification method adopts a multi-task deep learning framework that leverages the relationships among the five key wound conditions for a unified wound classification architecture. With differences in Cohen's kappa coefficients as the metrics to compare our proposed model with humans, the performance of our model was better or non-inferior to those of all human medical personnel. Our convolutional neural network-based model is the first to classify five tasks of deep, infected, arterial, venous, and pressure wounds simultaneously with good accuracy. The proposed model is compact and matches or exceeds the performance of human doctors and nurses. Medical personnel who do not specialize in wound care can potentially benefit from an app equipped with the proposed deep learning model.