 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturb-and-Restore: Simulation-driven Structural Augmentation Framework for Imbalance Chromosomal Anomaly Detection
Apr 01, 2026Detecting structural chromosomal abnormalities is crucial for accurate diagnosis and management of genetic disorders. However, collecting sufficient structural abnormality data is extremely challenging and costly in clinical practice, and not all abnormal types can be readily collected. As a result, deep learning approaches face significant performance degradation due to the severe imbalance and scarcity of abnormal chromosome data. To address this challenge, we propose a Perturb-and-Restore (P&R), a simulation-driven structural augmentation framework that effectively alleviates data imbalance in chromosome anomaly detection. The P&R framework comprises two key components: (1) Structure Perturbation and Restoration Simulation, which generates synthetic abnormal chromosomes by perturbing chromosomal banding patterns of normal chromosomes followed by a restoration diffusion network that reconstructs continuous chromosome content and edges, thus eliminating reliance on rare abnormal samples; and (2) Energy-guided Adaptive Sampling, an energy score-based online selection strategy that dynamically prioritizes high-quality synthetic samples by referencing the energy distribution of real samples. To evaluate our method, we construct a comprehensive structural anomaly dataset consisting of over 260,000 chromosome images, including 4,242 abnormal samples spanning 24 categories. Experimental results demonstrate that the P&R framework achieves state-of-the-art (SOTA) performance, surpassing existing methods with an average improvement of 8.92% in sensitivity, 8.89% in precision, and 13.79% in F1-score across all categories.
Good Reasoning Makes Good Demonstrations: Implicit Reasoning Quality Supervision via In-Context Reinforcement Learning
Mar 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) improves reasoning in large language models but treats all correct solutions equally, potentially reinforcing flawed traces that get correct answers by chance. We observe that better reasoning are better teachers: high-quality solutions serve as more effective demonstrations than low-quality ones. We term this teaching ability Demonstration Utility, and show that the policy model's own in-context learning ability provides an efficient way to measure it, yielding a quality signal termed Evidence Gain. To employ this signal during training, we introduce In-Context RLVR. By Bayesian analysis, we show that this objective implicitly reweights rewards by Evidence Gain, assigning higher weights to high-quality traces and lower weights to low-quality ones, without requiring costly computation or external evaluators. Experiments on mathematical benchmarks show improvements in both accuracy and reasoning quality over standard RLVR.
Harli: SLO-Aware Co-location of LLM Inference and PEFT-based Finetuning on Model-as-a-Service Platforms
Nov 19, 2025Large language models (LLMs) are increasingly deployed under the Model-as-a-Service (MaaS) paradigm. To meet stringent quality-of-service (QoS) requirements, existing LLM serving systems disaggregate the prefill and decode phases of inference. However, decode instances often experience low GPU utilization due to their memory-bound nature and insufficient batching in dynamic workloads, leaving compute resources underutilized. We introduce Harli, a serving system that improves GPU utilization by co-locating parameter-efficient finetuning (PEFT) tasks with LLM decode instances. PEFT tasks are compute-bound and memory-efficient, making them ideal candidates for safe co-location. Specifically, Harli addresses key challenges--limited memory and unpredictable interference--using three components: a unified memory allocator for runtime memory reuse, a two-stage latency predictor for decode latency modeling, and a QoS-guaranteed throughput-maximizing scheduler for throughput maximization. Experimental results show that Harli improves the finetune throughput by 46.2% on average (up to 92.0%) over state-of-the-art serving systems, while maintaining strict QoS guarantees for inference decode.
Boosting Embodied AI Agents through Perception-Generation Disaggregation and Asynchronous Pipeline Execution
Sep 11, 2025Embodied AI systems operate in dynamic environments, requiring seamless integration of perception and generation modules to process high-frequency input and output demands. Traditional sequential computation patterns, while effective in ensuring accuracy, face significant limitations in achieving the necessary "thinking" frequency for real-world applications. In this work, we present Auras, an algorithm-system co-designed inference framework to optimize the inference frequency of embodied AI agents. Auras disaggregates the perception and generation and provides controlled pipeline parallelism for them to achieve high and stable throughput. Faced with the data staleness problem that appears when the parallelism is increased, Auras establishes a public context for perception and generation to share, thereby promising the accuracy of embodied agents. Experimental results show that Auras improves throughput by 2.54x on average while achieving 102.7% of the original accuracy, demonstrating its efficacy in overcoming the constraints of sequential computation and providing high throughput.
UniSino: Physics-Driven Foundational Model for Universal CT Sinogram Standardization
Aug 25, 2025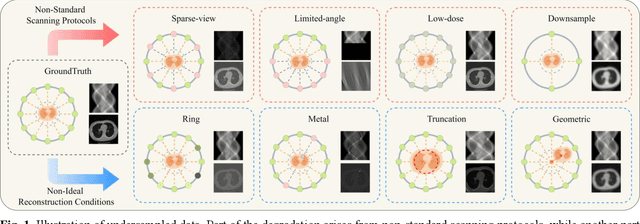
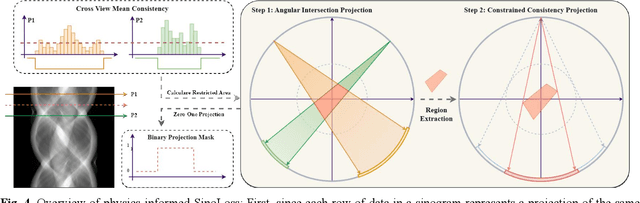
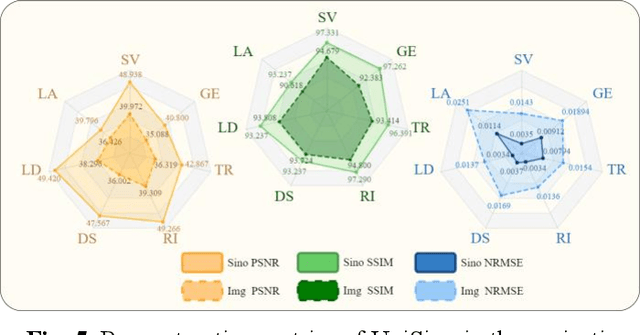
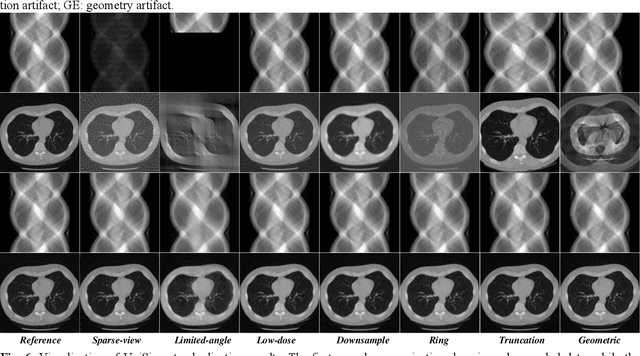
During raw-data acquisition in CT imaging, diverse factors can degrade the collected sinograms, with undersampling and noise leading to severe artifacts and noise in reconstructed images and compromising diagnostic accuracy. Conventional correction methods rely on manually designed algorithms or fixed empirical parameters, but these approaches often lack generalizability across heterogeneous artifact types. To address these limitations, we propose UniSino, a foundation model for universal CT sinogram standardization. Unlike existing foundational models that operate in image domain, UniSino directly standardizes data in the projection domain, which enables stronger generalization across diverse undersampling scenarios. Its training framework incorporates the physical characteristics of sinograms, enhancing generalization and enabling robust performance across multiple subtasks spanning four benchmark datasets. Experimental results demonstrate thatUniSino achieves superior reconstruction quality both single and mixed undersampling case, demonstrating exceptional robustness and generalization in sinogram enhancement for CT imaging. The code is available at: https://github.com/yqx7150/UniSino.
An Inclusive Foundation Model for Generalizable Cytogenetics in Precision Oncology
May 21, 2025Chromosome analysis is vital for diagnosing genetic disorders and guiding cancer therapy decisions through the identification of somatic clonal aberrations. However, developing an AI model are hindered by the overwhelming complexity and diversity of chromosomal abnormalities, requiring extensive annotation efforts, while automated methods remain task-specific and lack generalizability due to the scarcity of comprehensive datasets spanning diverse resource conditions. Here, we introduce CHROMA, a foundation model for cytogenomics, designed to overcome these challenges by learning generalizable representations of chromosomal abnormalities. Pre-trained on over 84,000 specimens (~4 million chromosomal images) via self-supervised learning, CHROMA outperforms other methods across all types of abnormalities, even when trained on fewer labelled data and more imbalanced datasets. By facilitating comprehensive mapping of instability and clonal leisons across various aberration types, CHROMA offers a scalable and generalizable solution for reliable and automated clinical analysis, reducing the annotation workload for experts and advancing precision oncology through the early detection of rare genomic abnormalities, enabling broad clinical AI applications and making advanced genomic analysis more accessible.
Generally-Occurring Model Change for Robust Counterfactual Explanations
Jul 16, 2024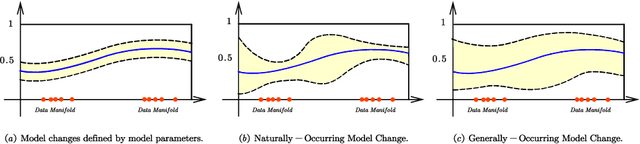
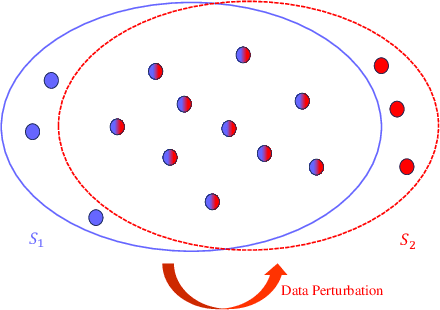
With the increasing impact of algorithmic decision-making on human lives, the interpretability of models has become a critical issue in machine learning. Counterfactual explanation is an important method in the field of interpretable machine learning, which can not only help users understand why machine learning models make specific decisions, but also help users understand how to change these decisions. Naturally, it is an important task to study the robustness of counterfactual explanation generation algorithms to model changes. Previous literature has proposed the concept of Naturally-Occurring Model Change, which has given us a deeper understanding of robustness to model change. In this paper, we first further generalize the concept of Naturally-Occurring Model Change, proposing a more general concept of model parameter changes, Generally-Occurring Model Change, which has a wider range of applicability. We also prove the corresponding probabilistic guarantees. In addition, we consider a more specific problem, data set perturbation, and give relevant theoretical results by combining optimization theory.
Weak Robust Compatibility Between Learning Algorithms and Counterfactual Explanation Generation Algorithms
May 31, 2024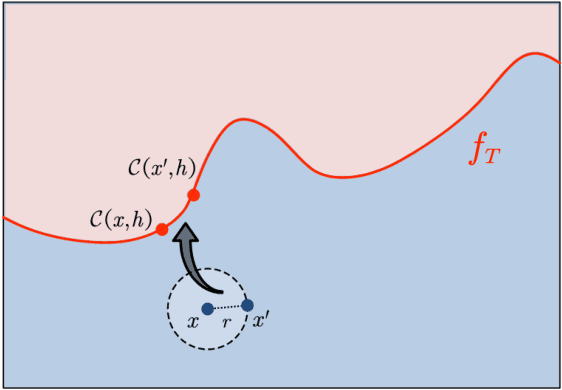
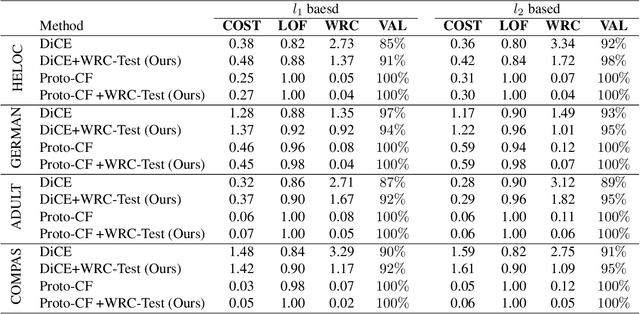
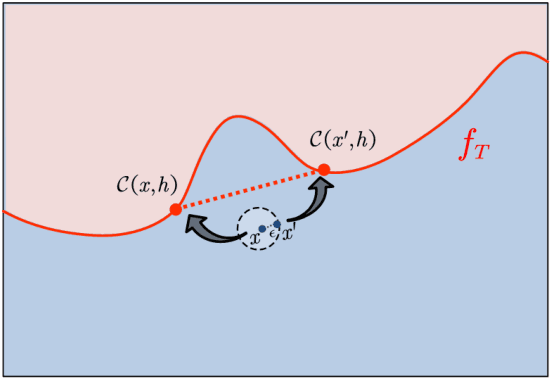
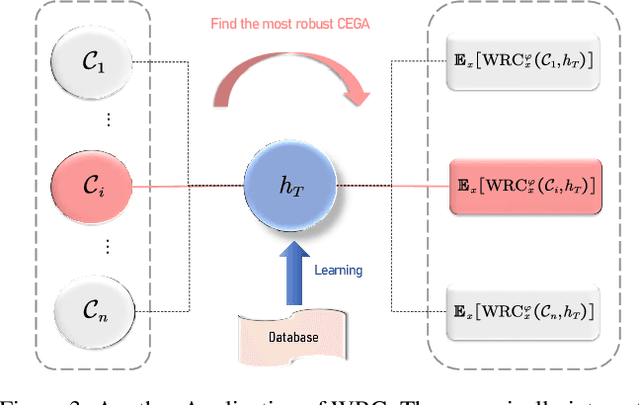
Counterfactual explanation generation is a powerful method for Explainable Artificial Intelligence. It can help users understand why machine learning models make specific decisions, and how to change those decisions. Evaluating the robustness of counterfactual explanation algorithms is therefore crucial. Previous literature has widely studied the robustness based on the perturbation of input instances. However, the robustness defined from the perspective of perturbed instances is sometimes biased, because this definition ignores the impact of learning algorithms on robustness. In this paper, we propose a more reasonable definition, Weak Robust Compatibility, based on the perspective of explanation strength. In practice, we propose WRC-Test to help us generate more robust counterfactuals. Meanwhile, we designed experiments to verify the effectiveness of WRC-Test. Theoretically, we introduce the concepts of PAC learning theory and define the concept of PAC WRC-Approximability. Based on reasonable assumptions, we establish oracle inequalities about weak robustness, which gives a sufficient condition for PAC WRC-Approximability.
Enhancing Counterfactual Image Generation Using Mahalanobis Distance with Distribution Preferences in Feature Space
May 31, 2024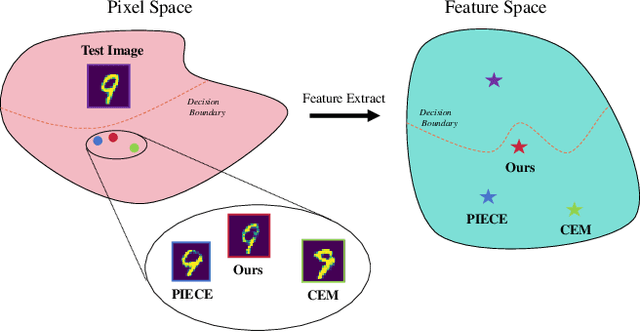
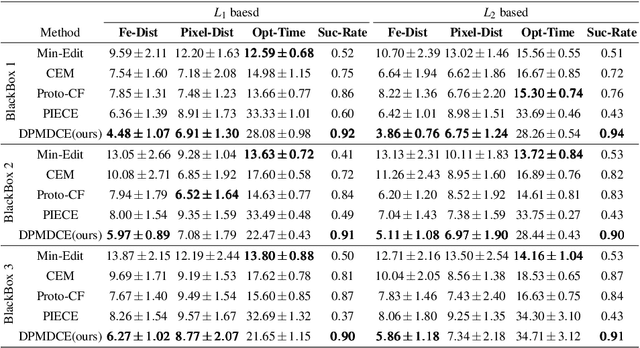

In the realm of Artificial Intelligence (AI), the importance of Explainable Artificial Intelligence (XAI) is increasingly recognized, particularly as AI models become more integral to our lives. One notable single-instance XAI approach is counterfactual explanation, which aids users in comprehending a model's decisions and offers guidance on altering these decisions. Specifically in the context of image classification models, effective image counterfactual explanations can significantly enhance user understanding. This paper introduces a novel method for computing feature importance within the feature space of a black-box model. By employing information fusion techniques, our method maximizes the use of data to address feature counterfactual explanations in the feature space. Subsequently, we utilize an image generation model to transform these feature counterfactual explanations into image counterfactual explanations. Our experiments demonstrate that the counterfactual explanations generated by our method closely resemble the original images in both pixel and feature spaces. Additionally, our method outperforms established baselines, achieving impressive experimental results.
Lightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023
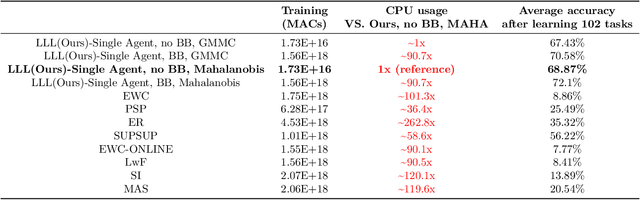

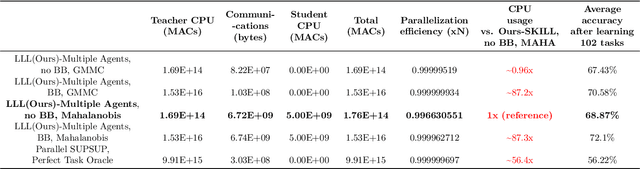
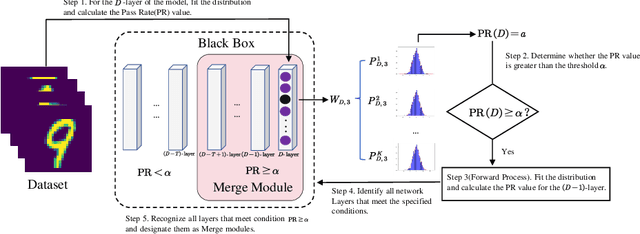
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning