 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturb-and-Restore: Simulation-driven Structural Augmentation Framework for Imbalance Chromosomal Anomaly Detection
Apr 01, 2026Detecting structural chromosomal abnormalities is crucial for accurate diagnosis and management of genetic disorders. However, collecting sufficient structural abnormality data is extremely challenging and costly in clinical practice, and not all abnormal types can be readily collected. As a result, deep learning approaches face significant performance degradation due to the severe imbalance and scarcity of abnormal chromosome data. To address this challenge, we propose a Perturb-and-Restore (P&R), a simulation-driven structural augmentation framework that effectively alleviates data imbalance in chromosome anomaly detection. The P&R framework comprises two key components: (1) Structure Perturbation and Restoration Simulation, which generates synthetic abnormal chromosomes by perturbing chromosomal banding patterns of normal chromosomes followed by a restoration diffusion network that reconstructs continuous chromosome content and edges, thus eliminating reliance on rare abnormal samples; and (2) Energy-guided Adaptive Sampling, an energy score-based online selection strategy that dynamically prioritizes high-quality synthetic samples by referencing the energy distribution of real samples. To evaluate our method, we construct a comprehensive structural anomaly dataset consisting of over 260,000 chromosome images, including 4,242 abnormal samples spanning 24 categories. Experimental results demonstrate that the P&R framework achieves state-of-the-art (SOTA) performance, surpassing existing methods with an average improvement of 8.92% in sensitivity, 8.89% in precision, and 13.79% in F1-score across all categories.
A data-physics hybrid generative model for patient-specific post-stroke motor rehabilitation using wearable sensor data
Dec 16, 2025Dynamic prediction of locomotor capacity after stroke is crucial for tailoring rehabilitation, yet current assessments provide only static impairment scores and do not indicate whether patients can safely perform specific tasks such as slope walking or stair climbing. Here, we develop a data-physics hybrid generative framework that reconstructs an individual stroke survivor's neuromuscular control from a single 20 m level-ground walking trial and predicts task-conditioned locomotion across rehabilitation scenarios. The system combines wearable-sensor kinematics, a proportional-derivative physics controller, a population Healthy Motion Atlas, and goal-conditioned deep reinforcement learning with behaviour cloning and generative adversarial imitation learning to generate physically plausible, patient-specific gait simulations for slopes and stairs. In 11 stroke survivors, the personalized controllers preserved idiosyncratic gait patterns while improving joint-angle and endpoint fidelity by 4.73% and 12.10%, respectively, and reducing training time to 25.56% relative to a physics-only baseline. In a multicentre pilot involving 21 inpatients, clinicians who used our locomotion predictions to guide task selection and difficulty obtained larger gains in Fugl-Meyer lower-extremity scores over 28 days of standard rehabilitation than control clinicians (mean change 6.0 versus 3.7 points). These findings indicate that our generative, task-predictive framework can augment clinical decision-making in post-stroke gait rehabilitation and provide a template for dynamically personalized motor recovery strategies.
PAST: A multimodal single-cell foundation model for histopathology and spatial transcriptomics in cancer
Jul 08, 2025While pathology foundation models have transformed cancer image analysis, they often lack integration with molecular data at single-cell resolution, limiting their utility for precision oncology. Here, we present PAST, a pan-cancer single-cell foundation model trained on 20 million paired histopathology images and single-cell transcriptomes spanning multiple tumor types and tissue contexts. By jointly encoding cellular morphology and gene expression, PAST learns unified cross-modal representations that capture both spatial and molecular heterogeneity at the cellular level. This approach enables accurate prediction of single-cell gene expression, virtual molecular staining, and multimodal survival analysis directly from routine pathology slides. Across diverse cancers and downstream tasks, PAST consistently exceeds the performance of existing approaches, demonstrating robust generalizability and scalability. Our work establishes a new paradigm for pathology foundation models, providing a versatile tool for high-resolution spatial omics, mechanistic discovery, and precision cancer research.
NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification
May 22, 2025
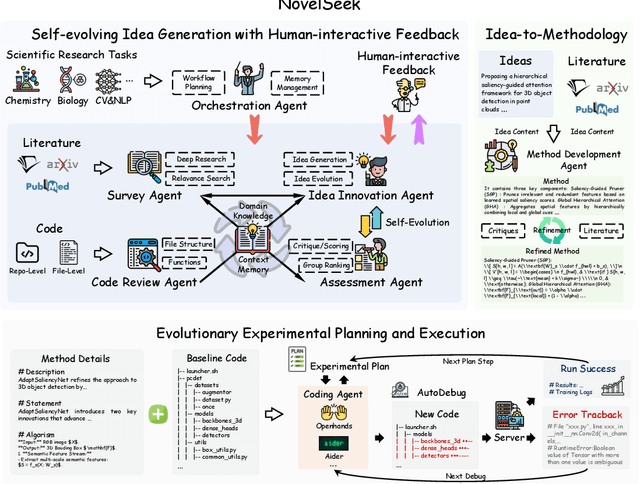

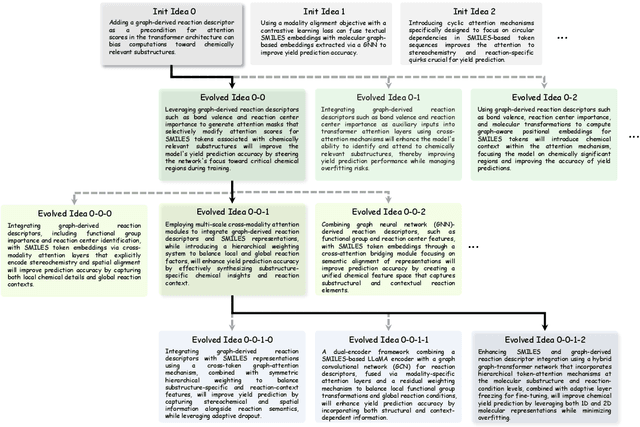
Artificial Intelligence (AI) is accelerating the transformation of scientific research paradigms, not only enhancing research efficiency but also driving innovation. We introduce NovelSeek, a unified closed-loop multi-agent framework to conduct Autonomous Scientific Research (ASR) across various scientific research fields, enabling researchers to tackle complicated problems in these fields with unprecedented speed and precision. NovelSeek highlights three key advantages: 1) Scalability: NovelSeek has demonstrated its versatility across 12 scientific research tasks, capable of generating innovative ideas to enhance the performance of baseline code. 2) Interactivity: NovelSeek provides an interface for human expert feedback and multi-agent interaction in automated end-to-end processes, allowing for the seamless integration of domain expert knowledge. 3) Efficiency: NovelSeek has achieved promising performance gains in several scientific fields with significantly less time cost compared to human efforts. For instance, in reaction yield prediction, it increased from 27.6% to 35.4% in just 12 hours; in enhancer activity prediction, accuracy rose from 0.52 to 0.79 with only 4 hours of processing; and in 2D semantic segmentation, precision advanced from 78.8% to 81.0% in a mere 30 hours.
An Inclusive Foundation Model for Generalizable Cytogenetics in Precision Oncology
May 21, 2025Chromosome analysis is vital for diagnosing genetic disorders and guiding cancer therapy decisions through the identification of somatic clonal aberrations. However, developing an AI model are hindered by the overwhelming complexity and diversity of chromosomal abnormalities, requiring extensive annotation efforts, while automated methods remain task-specific and lack generalizability due to the scarcity of comprehensive datasets spanning diverse resource conditions. Here, we introduce CHROMA, a foundation model for cytogenomics, designed to overcome these challenges by learning generalizable representations of chromosomal abnormalities. Pre-trained on over 84,000 specimens (~4 million chromosomal images) via self-supervised learning, CHROMA outperforms other methods across all types of abnormalities, even when trained on fewer labelled data and more imbalanced datasets. By facilitating comprehensive mapping of instability and clonal leisons across various aberration types, CHROMA offers a scalable and generalizable solution for reliable and automated clinical analysis, reducing the annotation workload for experts and advancing precision oncology through the early detection of rare genomic abnormalities, enabling broad clinical AI applications and making advanced genomic analysis more accessible.
Improving Representation of High-frequency Components for Medical Foundation Models
Jul 26, 2024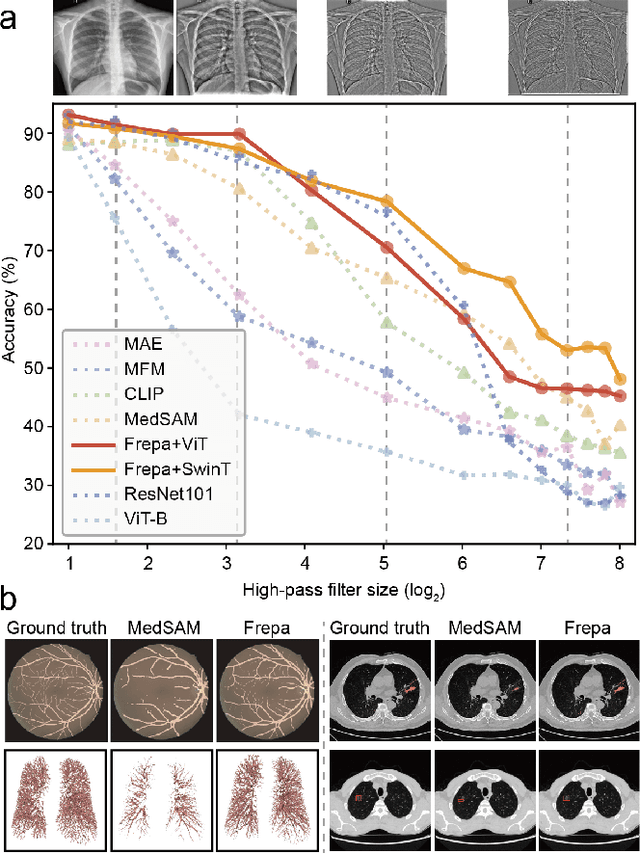

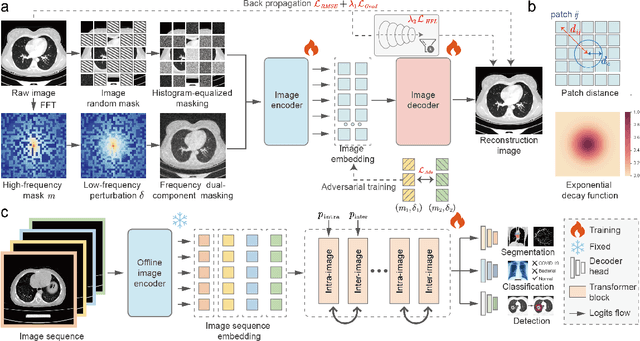

Foundation models have recently attracted significant attention for their impressive generalizability across diverse downstream tasks. However, these models are demonstrated to exhibit great limitations in representing high-frequency components and fine-grained details. In many medical imaging tasks, the precise representation of such information is crucial due to the inherently intricate anatomical structures, sub-visual features, and complex boundaries involved. Consequently, the limited representation of prevalent foundation models can result in significant performance degradation or even failure in these tasks. To address these challenges, we propose a novel pretraining strategy, named Frequency-advanced Representation Autoencoder (Frepa). Through high-frequency masking and low-frequency perturbation combined with adversarial learning, Frepa encourages the encoder to effectively represent and preserve high-frequency components in the image embeddings. Additionally, we introduce an innovative histogram-equalized image masking strategy, extending the Masked Autoencoder approach beyond ViT to other architectures such as Swin Transformer and convolutional networks. We develop Frepa across nine medical modalities and validate it on 32 downstream tasks for both 2D images and 3D volume data. Without fine-tuning, Frepa can outperform other self-supervised pretraining methods and, in some cases, even surpasses task-specific trained models. This improvement is particularly significant for tasks involving fine-grained details, such as achieving up to a +15% increase in DSC for retina vessel segmentation and a +7% increase in IoU for lung nodule detection. Further experiments quantitatively reveal that Frepa enables superior high-frequency representations and preservation in the embeddings, underscoring its potential for developing more generalized and universal medical image foundation models.
Prototypical Information Bottlenecking and Disentangling for Multimodal Cancer Survival Prediction
Jan 03, 2024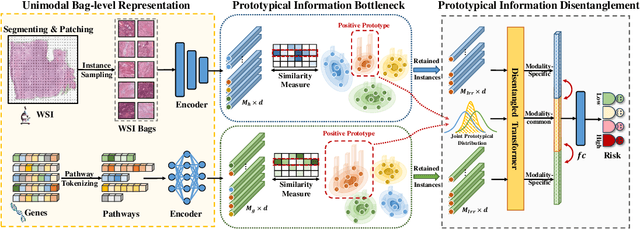
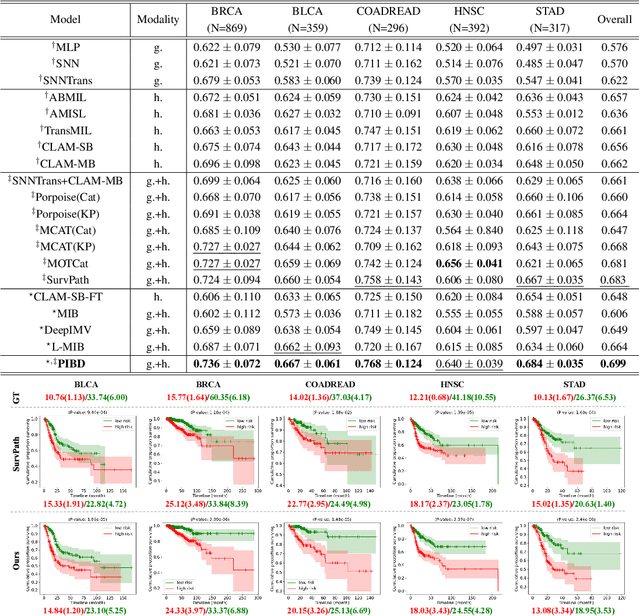
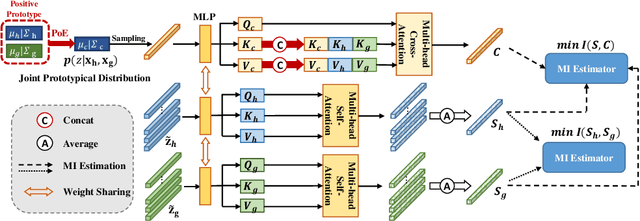
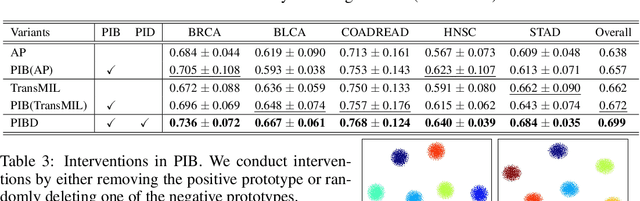
Multimodal learning significantly benefits cancer survival prediction, especially the integration of pathological images and genomic data. Despite advantages of multimodal learning for cancer survival prediction, massive redundancy in multimodal data prevents it from extracting discriminative and compact information: (1) An extensive amount of intra-modal task-unrelated information blurs discriminability, especially for gigapixel whole slide images (WSIs) with many patches in pathology and thousands of pathways in genomic data, leading to an ``intra-modal redundancy" issue. (2) Duplicated information among modalities dominates the representation of multimodal data, which makes modality-specific information prone to being ignored, resulting in an ``inter-modal redundancy" issue. To address these, we propose a new framework, Prototypical Information Bottlenecking and Disentangling (PIBD), consisting of Prototypical Information Bottleneck (PIB) module for intra-modal redundancy and Prototypical Information Disentanglement (PID) module for inter-modal redundancy. Specifically, a variant of information bottleneck, PIB, is proposed to model prototypes approximating a bunch of instances for different risk levels, which can be used for selection of discriminative instances within modality. PID module decouples entangled multimodal data into compact distinct components: modality-common and modality-specific knowledge, under the guidance of the joint prototypical distribution. Extensive experiments on five cancer benchmark datasets demonstrated our superiority over other methods.
Zero-Shot Image Harmonization with Generative Model Prior
Jul 17, 2023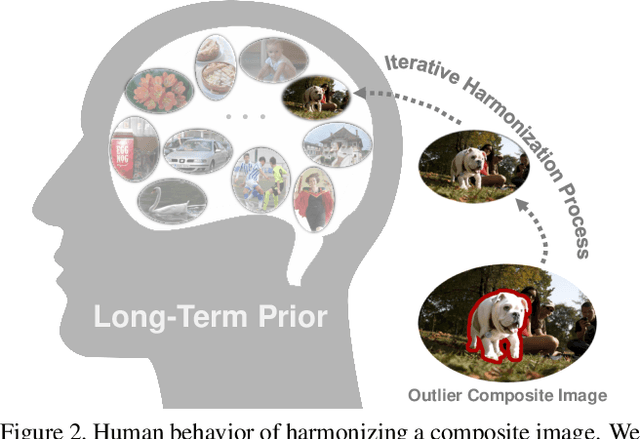
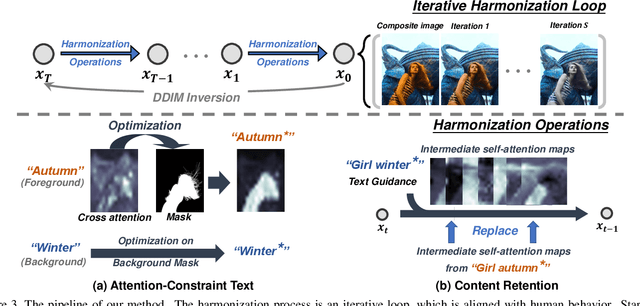


Recent image harmonization methods have demonstrated promising results. However, due to their heavy reliance on a large number of composite images, these works are expensive in the training phase and often fail to generalize to unseen images. In this paper, we draw lessons from human behavior and come up with a zero-shot image harmonization method. Specifically, in the harmonization process, a human mainly utilizes his long-term prior on harmonious images and makes a composite image close to that prior. To imitate that, we resort to pretrained generative models for the prior of natural images. For the guidance of the harmonization direction, we propose an Attention-Constraint Text which is optimized to well illustrate the image environments. Some further designs are introduced for preserving the foreground content structure. The resulting framework, highly consistent with human behavior, can achieve harmonious results without burdensome training. Extensive experiments have demonstrated the effectiveness of our approach, and we have also explored some interesting applications.
ECL: Class-Enhancement Contrastive Learning for Long-tailed Skin Lesion Classification
Jul 09, 2023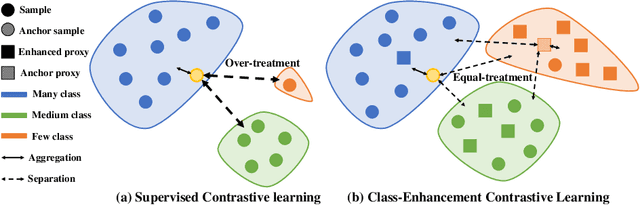
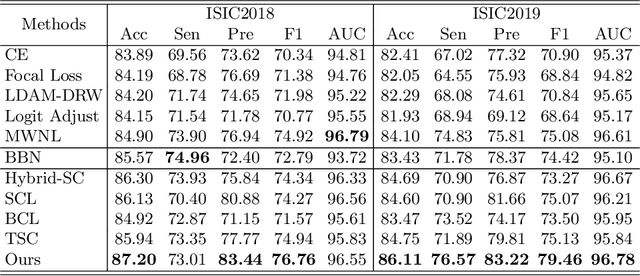
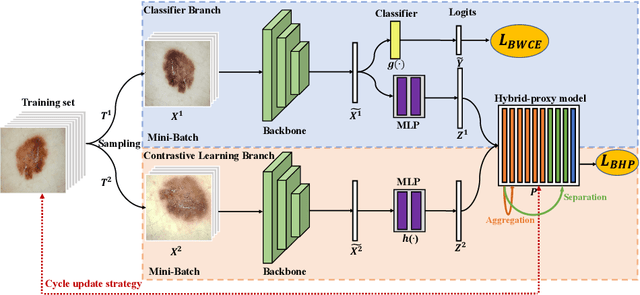
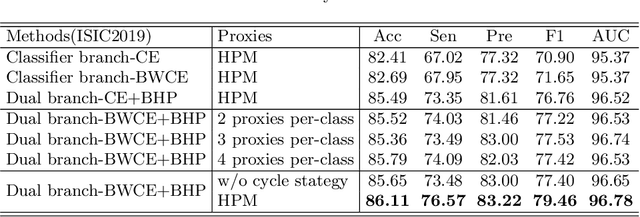
Skin image datasets often suffer from imbalanced data distribution, exacerbating the difficulty of computer-aided skin disease diagnosis. Some recent works exploit supervised contrastive learning (SCL) for this long-tailed challenge. Despite achieving significant performance, these SCL-based methods focus more on head classes, yet ignoring the utilization of information in tail classes. In this paper, we propose class-Enhancement Contrastive Learning (ECL), which enriches the information of minority classes and treats different classes equally. For information enhancement, we design a hybrid-proxy model to generate class-dependent proxies and propose a cycle update strategy for parameters optimization. A balanced-hybrid-proxy loss is designed to exploit relations between samples and proxies with different classes treated equally. Taking both "imbalanced data" and "imbalanced diagnosis difficulty" into account, we further present a balanced-weighted cross-entropy loss following curriculum learning schedule. Experimental results on the classification of imbalanced skin lesion data have demonstrated the superiority and effectiveness of our method.
Diffusion Models for Imperceptible and Transferable Adversarial Attack
May 14, 2023
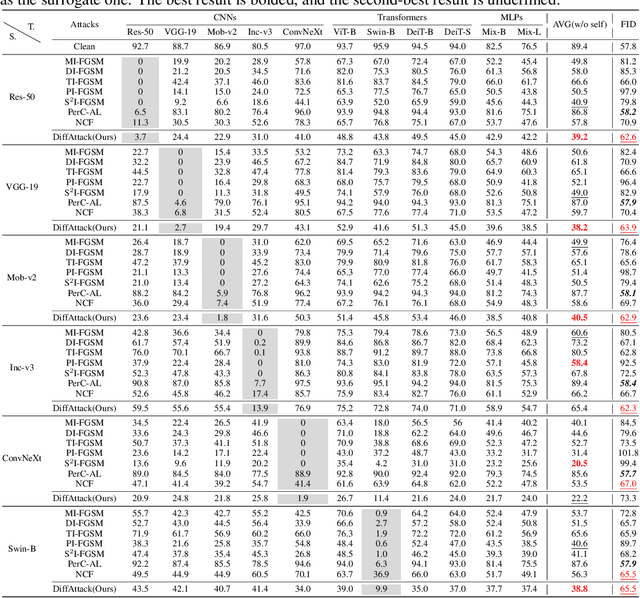
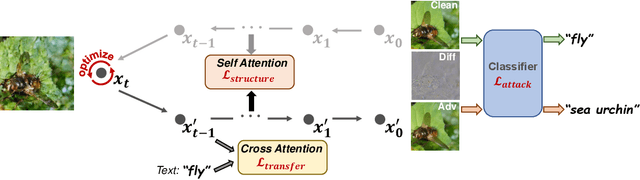
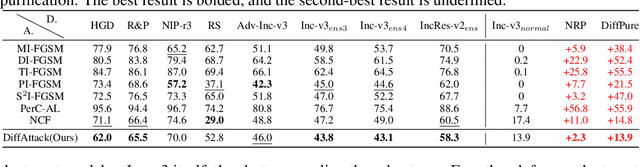
Many existing adversarial attacks generate $L_p$-norm perturbations on image RGB space. Despite some achievements in transferability and attack success rate, the crafted adversarial examples are easily perceived by human eyes. Towards visual imperceptibility, some recent works explore unrestricted attacks without $L_p$-norm constraints, yet lacking transferability of attacking black-box models. In this work, we propose a novel imperceptible and transferable attack by leveraging both the generative and discriminative power of diffusion models. Specifically, instead of direct manipulation in pixel space, we craft perturbations in latent space of diffusion models. Combined with well-designed content-preserving structures, we can generate human-insensitive perturbations embedded with semantic clues. For better transferability, we further "deceive" the diffusion model which can be viewed as an additional recognition surrogate, by distracting its attention away from the target regions. To our knowledge, our proposed method, DiffAttack, is the first that introduces diffusion models into adversarial attack field. Extensive experiments on various model structures (including CNNs, Transformers, MLPs) and defense methods have demonstrated our superiority over other attack methods.