 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Representation of High-frequency Components for Medical Foundation Models
Paper and Code
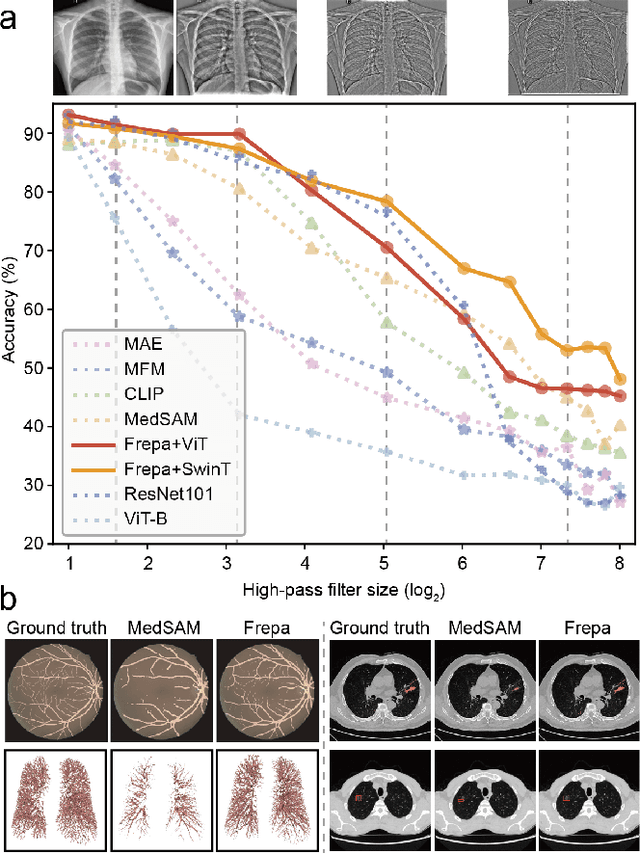

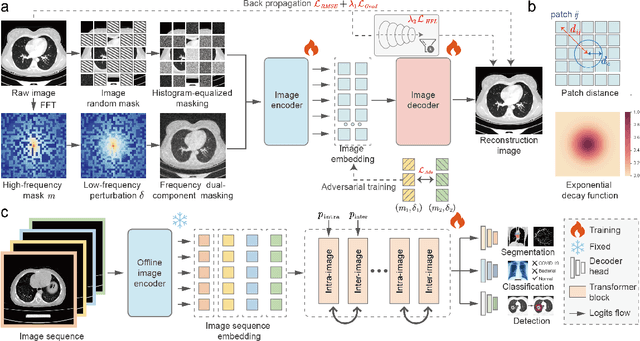

Foundation models have recently attracted significant attention for their impressive generalizability across diverse downstream tasks. However, these models are demonstrated to exhibit great limitations in representing high-frequency components and fine-grained details. In many medical imaging tasks, the precise representation of such information is crucial due to the inherently intricate anatomical structures, sub-visual features, and complex boundaries involved. Consequently, the limited representation of prevalent foundation models can result in significant performance degradation or even failure in these tasks. To address these challenges, we propose a novel pretraining strategy, named Frequency-advanced Representation Autoencoder (Frepa). Through high-frequency masking and low-frequency perturbation combined with adversarial learning, Frepa encourages the encoder to effectively represent and preserve high-frequency components in the image embeddings. Additionally, we introduce an innovative histogram-equalized image masking strategy, extending the Masked Autoencoder approach beyond ViT to other architectures such as Swin Transformer and convolutional networks. We develop Frepa across nine medical modalities and validate it on 32 downstream tasks for both 2D images and 3D volume data. Without fine-tuning, Frepa can outperform other self-supervised pretraining methods and, in some cases, even surpasses task-specific trained models. This improvement is particularly significant for tasks involving fine-grained details, such as achieving up to a +15% increase in DSC for retina vessel segmentation and a +7% increase in IoU for lung nodule detection. Further experiments quantitatively reveal that Frepa enables superior high-frequency representations and preservation in the embeddings, underscoring its potential for developing more generalized and universal medical image foundation models.