 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Image Harmonization with Generative Model Prior
Paper and Code
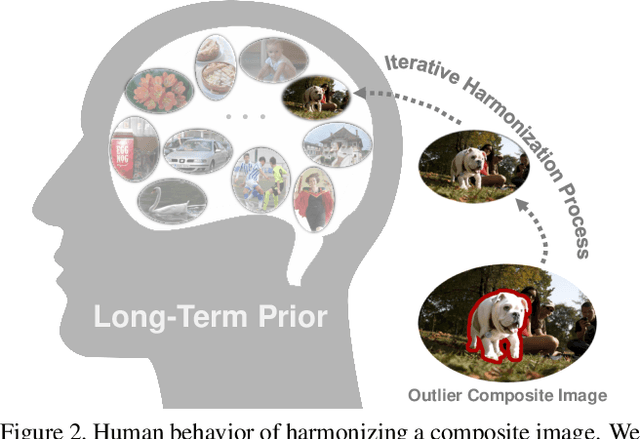
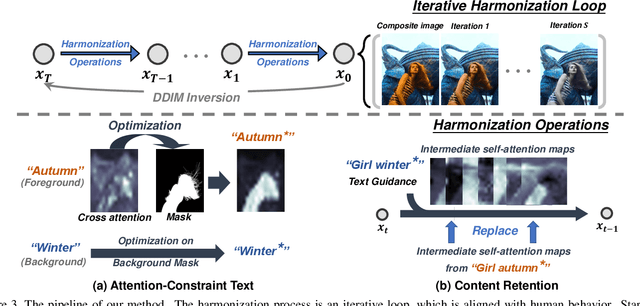


Recent image harmonization methods have demonstrated promising results. However, due to their heavy reliance on a large number of composite images, these works are expensive in the training phase and often fail to generalize to unseen images. In this paper, we draw lessons from human behavior and come up with a zero-shot image harmonization method. Specifically, in the harmonization process, a human mainly utilizes his long-term prior on harmonious images and makes a composite image close to that prior. To imitate that, we resort to pretrained generative models for the prior of natural images. For the guidance of the harmonization direction, we propose an Attention-Constraint Text which is optimized to well illustrate the image environments. Some further designs are introduced for preserving the foreground content structure. The resulting framework, highly consistent with human behavior, can achieve harmonious results without burdensome training. Extensive experiments have demonstrated the effectiveness of our approach, and we have also explored some interesting applications.