 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseGAM: Robust Unseen Object Pose Estimation via Geometry-Aware Multi-View Reasoning
Dec 11, 20256D object pose estimation, which predicts the transformation of an object relative to the camera, remains challenging for unseen objects. Existing approaches typically rely on explicitly constructing feature correspondences between the query image and either the object model or template images. In this work, we propose PoseGAM, a geometry-aware multi-view framework that directly predicts object pose from a query image and multiple template images, eliminating the need for explicit matching. Built upon recent multi-view-based foundation model architectures, the method integrates object geometry information through two complementary mechanisms: explicit point-based geometry and learned features from geometry representation networks. In addition, we construct a large-scale synthetic dataset containing more than 190k objects under diverse environmental conditions to enhance robustness and generalization. Extensive evaluations across multiple benchmarks demonstrate our state-of-the-art performance, yielding an average AR improvement of 5.1% over prior methods and achieving up to 17.6% gains on individual datasets, indicating strong generalization to unseen objects. Project page: https://windvchen.github.io/PoseGAM/ .
V2M4: 4D Mesh Animation Reconstruction from a Single Monocular Video
Mar 11, 2025



We present V2M4, a novel 4D reconstruction method that directly generates a usable 4D mesh animation asset from a single monocular video. Unlike existing approaches that rely on priors from multi-view image and video generation models, our method is based on native 3D mesh generation models. Naively applying 3D mesh generation models to generate a mesh for each frame in a 4D task can lead to issues such as incorrect mesh poses, misalignment of mesh appearance, and inconsistencies in mesh geometry and texture maps. To address these problems, we propose a structured workflow that includes camera search and mesh reposing, condition embedding optimization for mesh appearance refinement, pairwise mesh registration for topology consistency, and global texture map optimization for texture consistency. Our method outputs high-quality 4D animated assets that are compatible with mainstream graphics and game software. Experimental results across a variety of animation types and motion amplitudes demonstrate the generalization and effectiveness of our method. Project page:https://windvchen.github.io/V2M4/.
StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration
Nov 07, 2024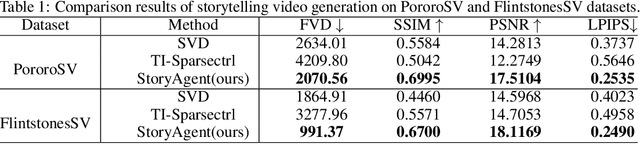
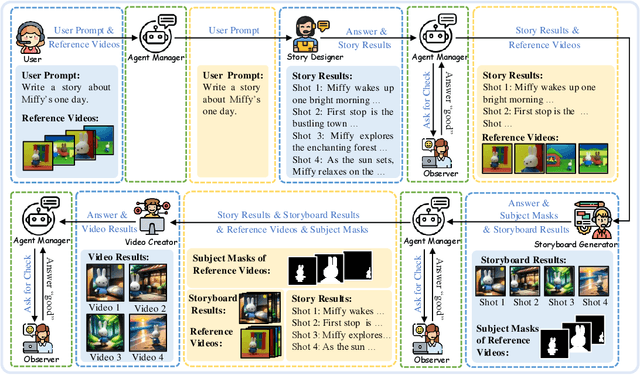


The advent of AI-Generated Content (AIGC) has spurred research into automated video generation to streamline conventional processes. However, automating storytelling video production, particularly for customized narratives, remains challenging due to the complexity of maintaining subject consistency across shots. While existing approaches like Mora and AesopAgent integrate multiple agents for Story-to-Video (S2V) generation, they fall short in preserving protagonist consistency and supporting Customized Storytelling Video Generation (CSVG). To address these limitations, we propose StoryAgent, a multi-agent framework designed for CSVG. StoryAgent decomposes CSVG into distinct subtasks assigned to specialized agents, mirroring the professional production process. Notably, our framework includes agents for story design, storyboard generation, video creation, agent coordination, and result evaluation. Leveraging the strengths of different models, StoryAgent enhances control over the generation process, significantly improving character consistency. Specifically, we introduce a customized Image-to-Video (I2V) method, LoRA-BE, to enhance intra-shot temporal consistency, while a novel storyboard generation pipeline is proposed to maintain subject consistency across shots. Extensive experiments demonstrate the effectiveness of our approach in synthesizing highly consistent storytelling videos, outperforming state-of-the-art methods. Our contributions include the introduction of StoryAgent, a versatile framework for video generation tasks, and novel techniques for preserving protagonist consistency.
Sitcom-Crafter: A Plot-Driven Human Motion Generation System in 3D Scenes
Oct 14, 2024
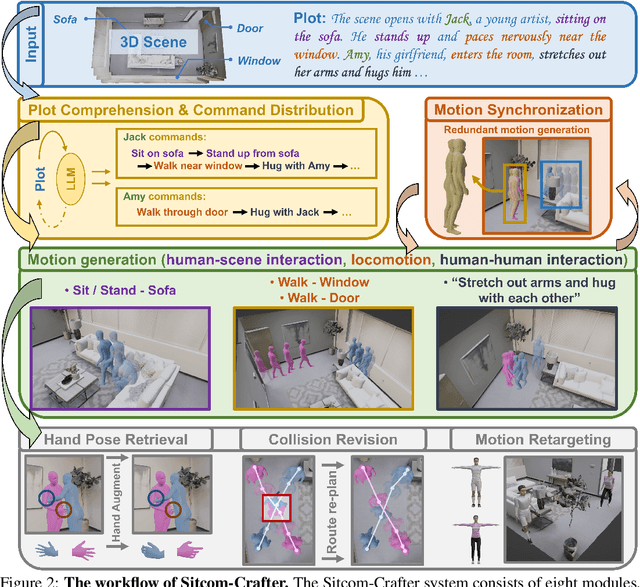
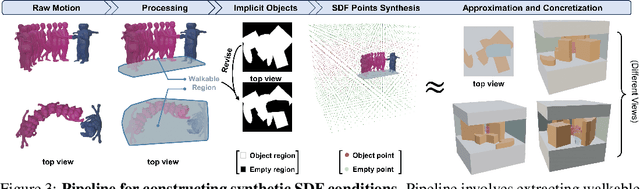
Recent advancements in human motion synthesis have focused on specific types of motions, such as human-scene interaction, locomotion or human-human interaction, however, there is a lack of a unified system capable of generating a diverse combination of motion types. In response, we introduce Sitcom-Crafter, a comprehensive and extendable system for human motion generation in 3D space, which can be guided by extensive plot contexts to enhance workflow efficiency for anime and game designers. The system is comprised of eight modules, three of which are dedicated to motion generation, while the remaining five are augmentation modules that ensure consistent fusion of motion sequences and system functionality. Central to the generation modules is our novel 3D scene-aware human-human interaction module, which addresses collision issues by synthesizing implicit 3D Signed Distance Function (SDF) points around motion spaces, thereby minimizing human-scene collisions without additional data collection costs. Complementing this, our locomotion and human-scene interaction modules leverage existing methods to enrich the system's motion generation capabilities. Augmentation modules encompass plot comprehension for command generation, motion synchronization for seamless integration of different motion types, hand pose retrieval to enhance motion realism, motion collision revision to prevent human collisions, and 3D retargeting to ensure visual fidelity. Experimental evaluations validate the system's ability to generate high-quality, diverse, and physically realistic motions, underscoring its potential for advancing creative workflows.
Prototypical Information Bottlenecking and Disentangling for Multimodal Cancer Survival Prediction
Jan 03, 2024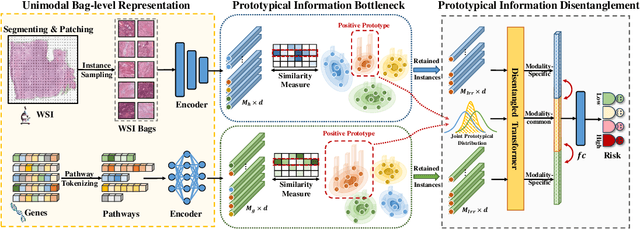
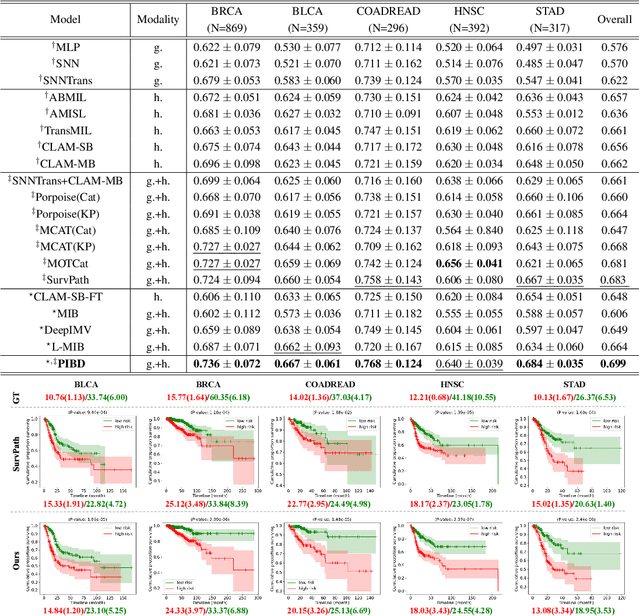
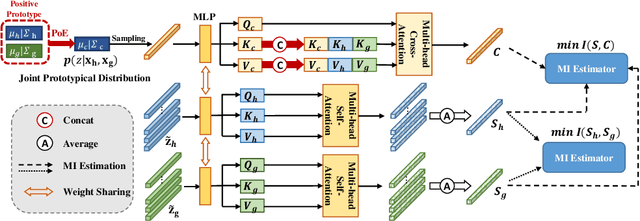
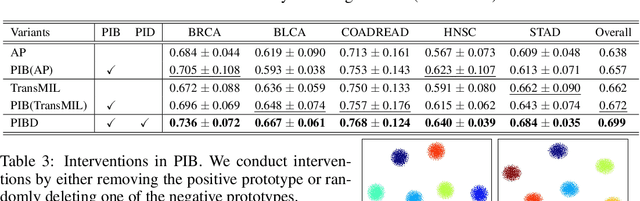
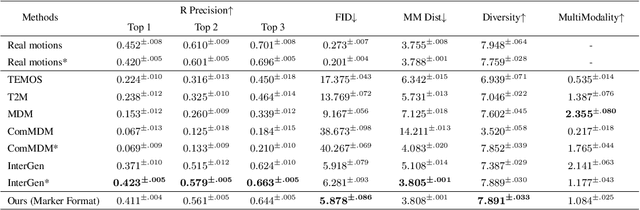
Multimodal learning significantly benefits cancer survival prediction, especially the integration of pathological images and genomic data. Despite advantages of multimodal learning for cancer survival prediction, massive redundancy in multimodal data prevents it from extracting discriminative and compact information: (1) An extensive amount of intra-modal task-unrelated information blurs discriminability, especially for gigapixel whole slide images (WSIs) with many patches in pathology and thousands of pathways in genomic data, leading to an ``intra-modal redundancy" issue. (2) Duplicated information among modalities dominates the representation of multimodal data, which makes modality-specific information prone to being ignored, resulting in an ``inter-modal redundancy" issue. To address these, we propose a new framework, Prototypical Information Bottlenecking and Disentangling (PIBD), consisting of Prototypical Information Bottleneck (PIB) module for intra-modal redundancy and Prototypical Information Disentanglement (PID) module for inter-modal redundancy. Specifically, a variant of information bottleneck, PIB, is proposed to model prototypes approximating a bunch of instances for different risk levels, which can be used for selection of discriminative instances within modality. PID module decouples entangled multimodal data into compact distinct components: modality-common and modality-specific knowledge, under the guidance of the joint prototypical distribution. Extensive experiments on five cancer benchmark datasets demonstrated our superiority over other methods.
Zero-Shot Image Harmonization with Generative Model Prior
Jul 17, 2023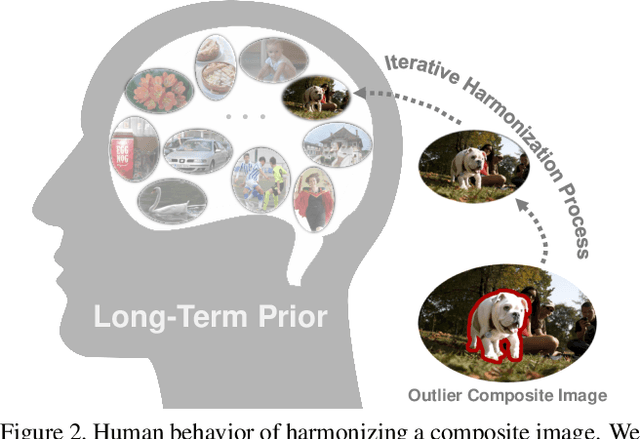
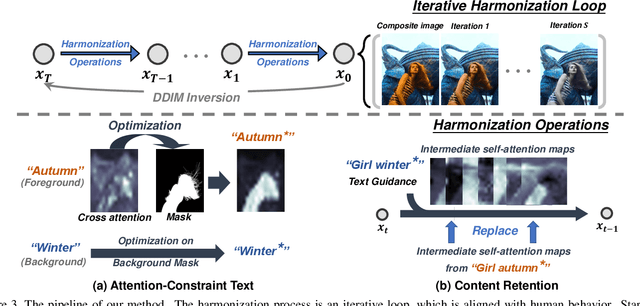


Recent image harmonization methods have demonstrated promising results. However, due to their heavy reliance on a large number of composite images, these works are expensive in the training phase and often fail to generalize to unseen images. In this paper, we draw lessons from human behavior and come up with a zero-shot image harmonization method. Specifically, in the harmonization process, a human mainly utilizes his long-term prior on harmonious images and makes a composite image close to that prior. To imitate that, we resort to pretrained generative models for the prior of natural images. For the guidance of the harmonization direction, we propose an Attention-Constraint Text which is optimized to well illustrate the image environments. Some further designs are introduced for preserving the foreground content structure. The resulting framework, highly consistent with human behavior, can achieve harmonious results without burdensome training. Extensive experiments have demonstrated the effectiveness of our approach, and we have also explored some interesting applications.
ECL: Class-Enhancement Contrastive Learning for Long-tailed Skin Lesion Classification
Jul 09, 2023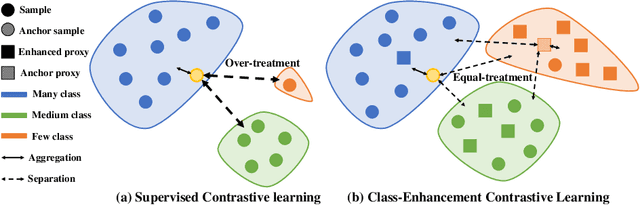
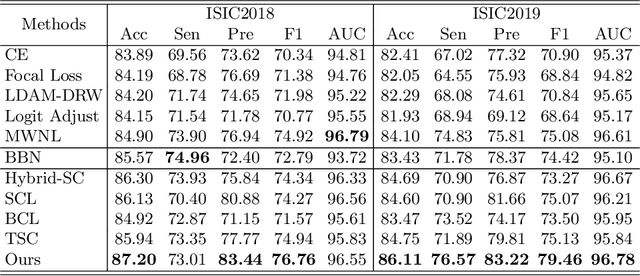
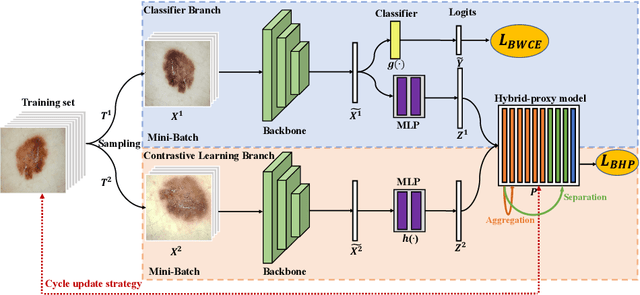
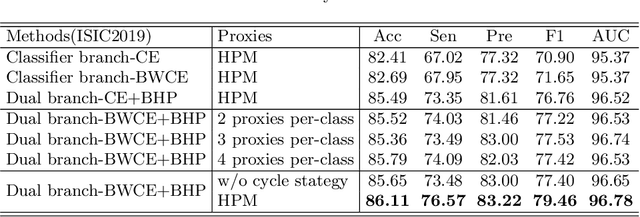
Skin image datasets often suffer from imbalanced data distribution, exacerbating the difficulty of computer-aided skin disease diagnosis. Some recent works exploit supervised contrastive learning (SCL) for this long-tailed challenge. Despite achieving significant performance, these SCL-based methods focus more on head classes, yet ignoring the utilization of information in tail classes. In this paper, we propose class-Enhancement Contrastive Learning (ECL), which enriches the information of minority classes and treats different classes equally. For information enhancement, we design a hybrid-proxy model to generate class-dependent proxies and propose a cycle update strategy for parameters optimization. A balanced-hybrid-proxy loss is designed to exploit relations between samples and proxies with different classes treated equally. Taking both "imbalanced data" and "imbalanced diagnosis difficulty" into account, we further present a balanced-weighted cross-entropy loss following curriculum learning schedule. Experimental results on the classification of imbalanced skin lesion data have demonstrated the superiority and effectiveness of our method.
Diffusion Models for Imperceptible and Transferable Adversarial Attack
May 14, 2023
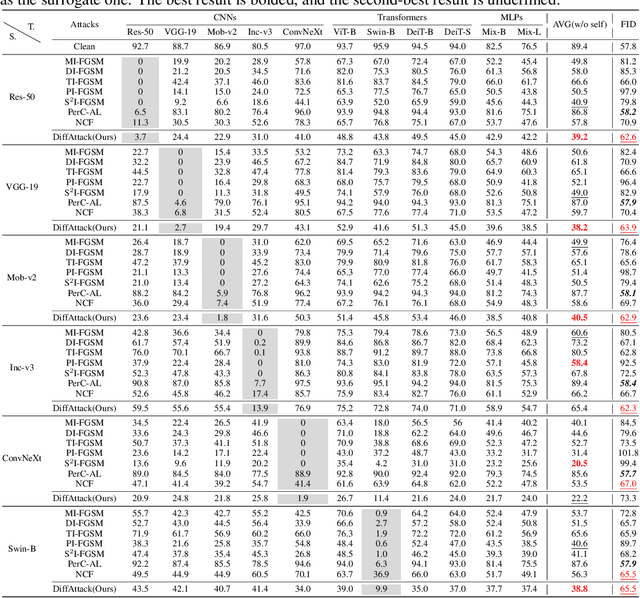
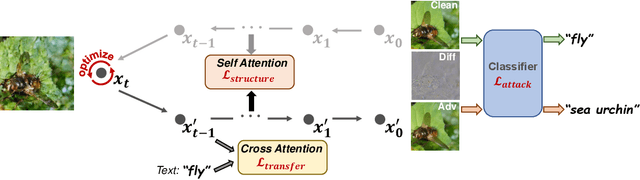
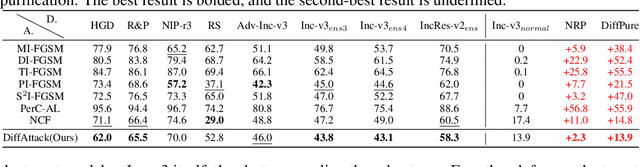
Many existing adversarial attacks generate $L_p$-norm perturbations on image RGB space. Despite some achievements in transferability and attack success rate, the crafted adversarial examples are easily perceived by human eyes. Towards visual imperceptibility, some recent works explore unrestricted attacks without $L_p$-norm constraints, yet lacking transferability of attacking black-box models. In this work, we propose a novel imperceptible and transferable attack by leveraging both the generative and discriminative power of diffusion models. Specifically, instead of direct manipulation in pixel space, we craft perturbations in latent space of diffusion models. Combined with well-designed content-preserving structures, we can generate human-insensitive perturbations embedded with semantic clues. For better transferability, we further "deceive" the diffusion model which can be viewed as an additional recognition surrogate, by distracting its attention away from the target regions. To our knowledge, our proposed method, DiffAttack, is the first that introduces diffusion models into adversarial attack field. Extensive experiments on various model structures (including CNNs, Transformers, MLPs) and defense methods have demonstrated our superiority over other attack methods.
Dense Pixel-to-Pixel Harmonization via Continuous Image Representation
Mar 03, 2023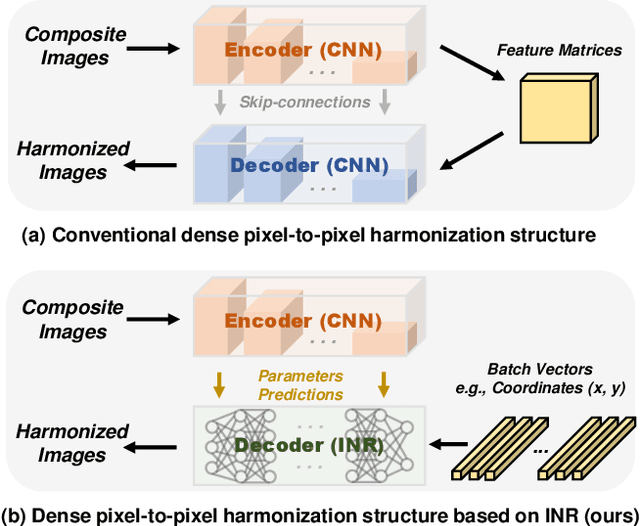
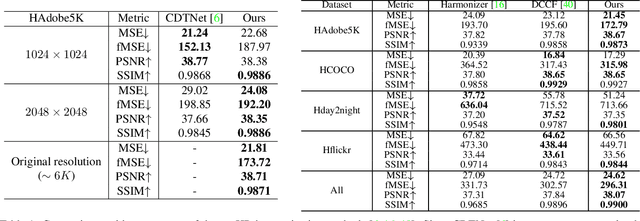
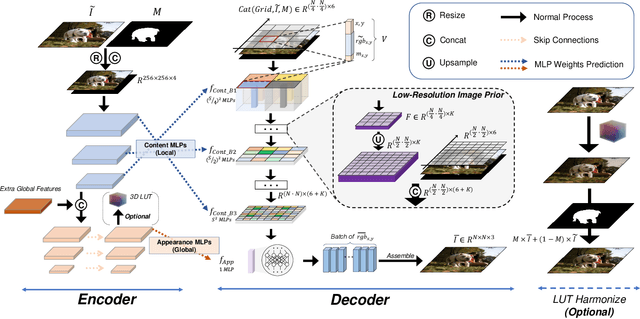
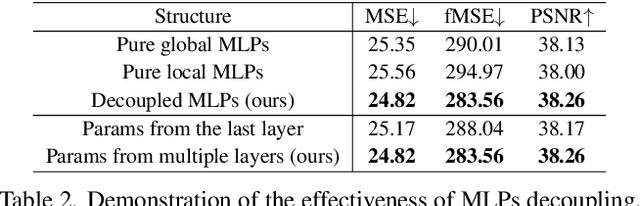
High-resolution (HR) image harmonization is of great significance in real-world applications such as image synthesis and image editing. However, due to the high memory costs, existing dense pixel-to-pixel harmonization methods are mainly focusing on processing low-resolution (LR) images. Some recent works resort to combining with color-to-color transformations but are either limited to certain resolutions or heavily depend on hand-crafted image filters. In this work, we explore leveraging the implicit neural representation (INR) and propose a novel image Harmonization method based on Implicit neural Networks (HINet), which to the best of our knowledge, is the first dense pixel-to-pixel method applicable to HR images without any hand-crafted filter design. Inspired by the Retinex theory, we decouple the MLPs into two parts to respectively capture the content and environment of composite images. A Low-Resolution Image Prior (LRIP) network is designed to alleviate the Boundary Inconsistency problem, and we also propose new designs for the training and inference process. Extensive experiments have demonstrated the effectiveness of our method compared with state-of-the-art methods. Furthermore, some interesting and practical applications of the proposed method are explored. Our code will be available at https://github.com/WindVChen/INR-Harmonization.
Continuous Remote Sensing Image Super-Resolution based on Context Interaction in Implicit Function Space
Feb 16, 2023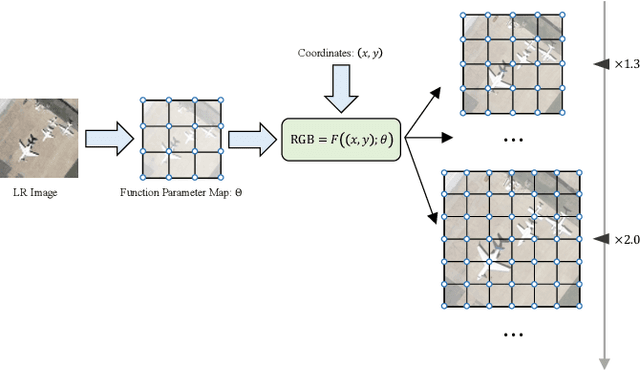
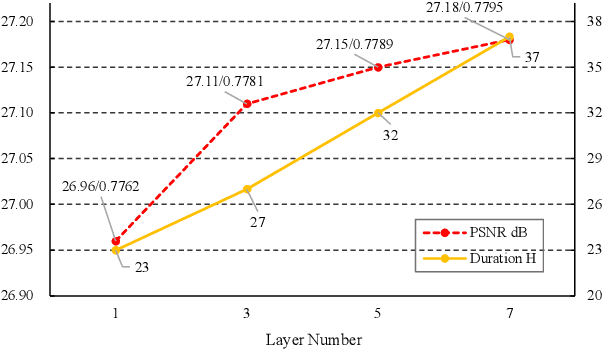
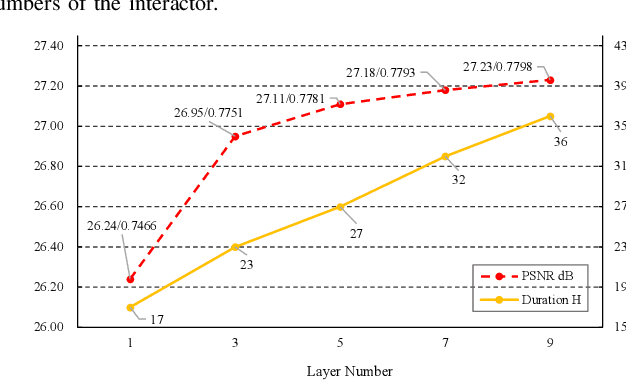
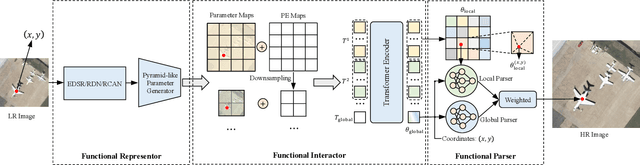
Despite its fruitful applications in remote sensing, image super-resolution is troublesome to train and deploy as it handles different resolution magnifications with separate models. Accordingly, we propose a highly-applicable super-resolution framework called FunSR, which settles different magnifications with a unified model by exploiting context interaction within implicit function space. FunSR composes a functional representor, a functional interactor, and a functional parser. Specifically, the representor transforms the low-resolution image from Euclidean space to multi-scale pixel-wise function maps; the interactor enables pixel-wise function expression with global dependencies; and the parser, which is parameterized by the interactor's output, converts the discrete coordinates with additional attributes to RGB values. Extensive experimental results demonstrate that FunSR reports state-of-the-art performance on both fixed-magnification and continuous-magnification settings, meanwhile, it provides many friendly applications thanks to its unified nature.