 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHOY! Animatable Humans under Occlusion from YouTube Videos with Gaussian Splatting and Video Diffusion Priors
Mar 18, 2026We present AHOY, a method for reconstructing complete, animatable 3D Gaussian avatars from in-the-wild monocular video despite heavy occlusion. Existing methods assume unoccluded input-a fully visible subject, often in a canonical pose-excluding the vast majority of real-world footage where people are routinely occluded by furniture, objects, or other people. Reconstructing from such footage poses fundamental challenges: large body regions may never be observed, and multi-view supervision per pose is unavailable. We address these challenges with four contributions: (i) a hallucination-as-supervision pipeline that uses identity-finetuned diffusion models to generate dense supervision for previously unobserved body regions; (ii) a two-stage canonical-to-pose-dependent architecture that bootstraps from sparse observations to full pose-dependent Gaussian maps; (iii) a map-pose/LBS-pose decoupling that absorbs multi-view inconsistencies from the generated data; (iv) a head/body split supervision strategy that preserves facial identity. We evaluate on YouTube videos and on multi-view capture data with significant occlusion and demonstrate state-of-the-art reconstruction quality. We also demonstrate that the resulting avatars are robust enough to be animated with novel poses and composited into 3DGS scenes captured using cell-phone video. Our project page is available at https://miraymen.github.io/ahoy/
Any Resolution Any Geometry: From Multi-View To Multi-Patch
Mar 03, 2026Joint estimation of surface normals and depth is essential for holistic 3D scene understanding, yet high-resolution prediction remains difficult due to the trade-off between preserving fine local detail and maintaining global consistency. To address this challenge, we propose the Ultra Resolution Geometry Transformer (URGT), which adapts the Visual Geometry Grounded Transformer (VGGT) into a unified multi-patch transformer for monocular high-resolution depth--normal estimation. A single high-resolution image is partitioned into patches that are augmented with coarse depth and normal priors from pre-trained models, and jointly processed in a single forward pass to predict refined geometric outputs. Global coherence is enforced through cross-patch attention, which enables long-range geometric reasoning and seamless propagation of information across patches within a shared backbone. To further enhance spatial robustness, we introduce a GridMix patch sampling strategy that probabilistically samples grid configurations during training, improving inter-patch consistency and generalization. Our method achieves state-of-the-art results on UnrealStereo4K, jointly improving depth and normal estimation, reducing AbsRel from 0.0582 to 0.0291, RMSE from 2.17 to 1.31, and lowering mean angular error from 23.36 degrees to 18.51 degrees, while producing sharper and more stable geometry. The proposed multi-patch framework also demonstrates strong zero-shot and cross-domain generalization and scales effectively to very high resolutions, offering an efficient and extensible solution for high-quality geometry refinement.
PoseGAM: Robust Unseen Object Pose Estimation via Geometry-Aware Multi-View Reasoning
Dec 11, 20256D object pose estimation, which predicts the transformation of an object relative to the camera, remains challenging for unseen objects. Existing approaches typically rely on explicitly constructing feature correspondences between the query image and either the object model or template images. In this work, we propose PoseGAM, a geometry-aware multi-view framework that directly predicts object pose from a query image and multiple template images, eliminating the need for explicit matching. Built upon recent multi-view-based foundation model architectures, the method integrates object geometry information through two complementary mechanisms: explicit point-based geometry and learned features from geometry representation networks. In addition, we construct a large-scale synthetic dataset containing more than 190k objects under diverse environmental conditions to enhance robustness and generalization. Extensive evaluations across multiple benchmarks demonstrate our state-of-the-art performance, yielding an average AR improvement of 5.1% over prior methods and achieving up to 17.6% gains on individual datasets, indicating strong generalization to unseen objects. Project page: https://windvchen.github.io/PoseGAM/ .
Human Geometry Distribution for 3D Animation Generation
Dec 08, 2025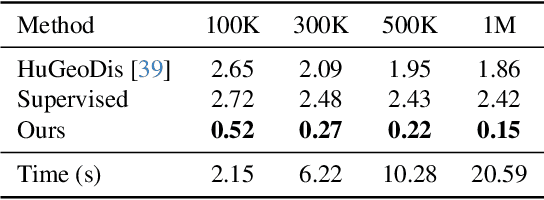
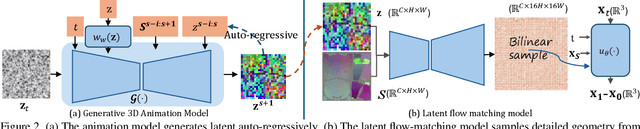
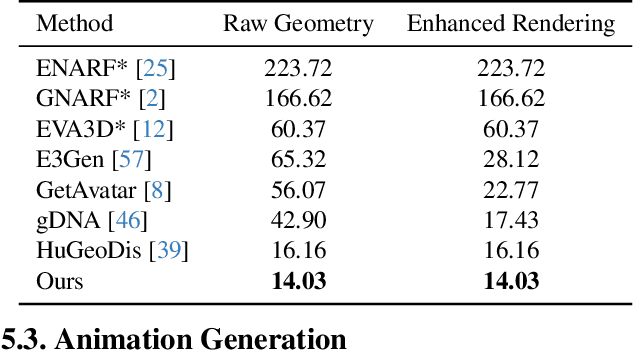
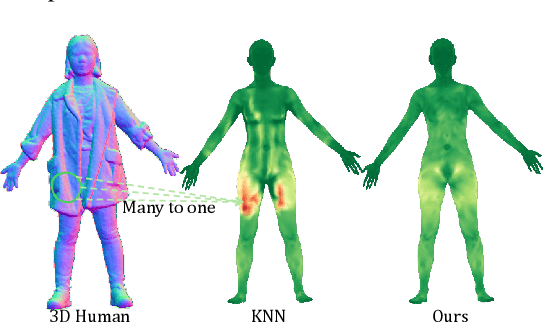
Generating realistic human geometry animations remains a challenging task, as it requires modeling natural clothing dynamics with fine-grained geometric details under limited data. To address these challenges, we propose two novel designs. First, we propose a compact distribution-based latent representation that enables efficient and high-quality geometry generation. We improve upon previous work by establishing a more uniform mapping between SMPL and avatar geometries. Second, we introduce a generative animation model that fully exploits the diversity of limited motion data. We focus on short-term transitions while maintaining long-term consistency through an identity-conditioned design. These two designs formulate our method as a two-stage framework: the first stage learns a latent space, while the second learns to generate animations within this latent space. We conducted experiments on both our latent space and animation model. We demonstrate that our latent space produces high-fidelity human geometry surpassing previous methods ($90\%$ lower Chamfer Dist.). The animation model synthesizes diverse animations with detailed and natural dynamics ($2.2 \times$ higher user study score), achieving the best results across all evaluation metrics.
V2M4: 4D Mesh Animation Reconstruction from a Single Monocular Video
Mar 11, 2025



We present V2M4, a novel 4D reconstruction method that directly generates a usable 4D mesh animation asset from a single monocular video. Unlike existing approaches that rely on priors from multi-view image and video generation models, our method is based on native 3D mesh generation models. Naively applying 3D mesh generation models to generate a mesh for each frame in a 4D task can lead to issues such as incorrect mesh poses, misalignment of mesh appearance, and inconsistencies in mesh geometry and texture maps. To address these problems, we propose a structured workflow that includes camera search and mesh reposing, condition embedding optimization for mesh appearance refinement, pairwise mesh registration for topology consistency, and global texture map optimization for texture consistency. Our method outputs high-quality 4D animated assets that are compatible with mainstream graphics and game software. Experimental results across a variety of animation types and motion amplitudes demonstrate the generalization and effectiveness of our method. Project page:https://windvchen.github.io/V2M4/.
Generative Human Geometry Distribution
Mar 03, 2025Realistic human geometry generation is an important yet challenging task, requiring both the preservation of fine clothing details and the accurate modeling of clothing-pose interactions. Geometry distributions, which can model the geometry of a single human as a distribution, provide a promising representation for high-fidelity synthesis. However, applying geometry distributions for human generation requires learning a dataset-level distribution over numerous individual geometry distributions. To address the resulting challenges, we propose a novel 3D human generative framework that, for the first time, models the distribution of human geometry distributions. Our framework operates in two stages: first, generating the human geometry distribution, and second, synthesizing high-fidelity humans by sampling from this distribution. We validate our method on two tasks: pose-conditioned 3D human generation and single-view-based novel pose generation. Experimental results demonstrate that our approach achieves the best quantitative results in terms of realism and geometric fidelity, outperforming state-of-the-art generative methods.
StyleTex: Style Image-Guided Texture Generation for 3D Models
Nov 01, 2024
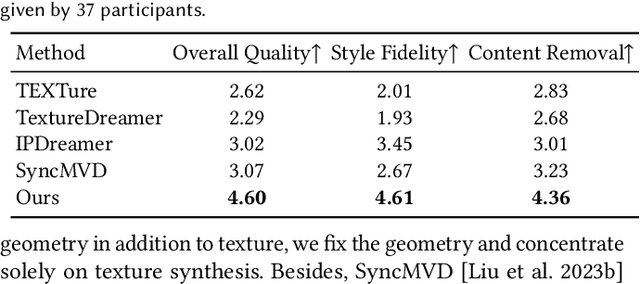
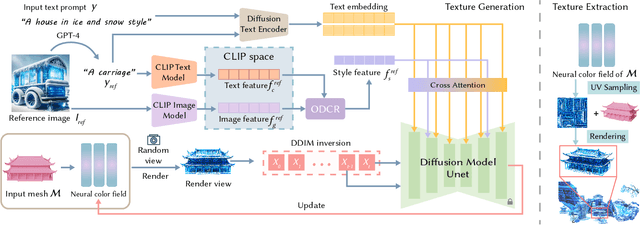
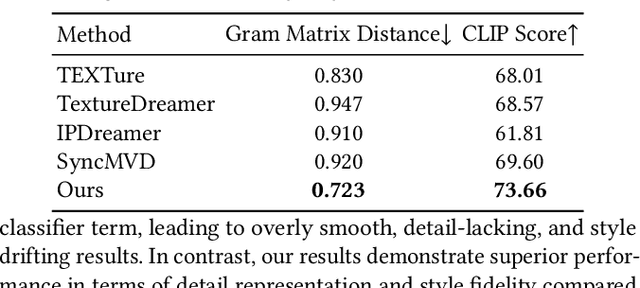
Style-guided texture generation aims to generate a texture that is harmonious with both the style of the reference image and the geometry of the input mesh, given a reference style image and a 3D mesh with its text description. Although diffusion-based 3D texture generation methods, such as distillation sampling, have numerous promising applications in stylized games and films, it requires addressing two challenges: 1) decouple style and content completely from the reference image for 3D models, and 2) align the generated texture with the color tone, style of the reference image, and the given text prompt. To this end, we introduce StyleTex, an innovative diffusion-model-based framework for creating stylized textures for 3D models. Our key insight is to decouple style information from the reference image while disregarding content in diffusion-based distillation sampling. Specifically, given a reference image, we first decompose its style feature from the image CLIP embedding by subtracting the embedding's orthogonal projection in the direction of the content feature, which is represented by a text CLIP embedding. Our novel approach to disentangling the reference image's style and content information allows us to generate distinct style and content features. We then inject the style feature into the cross-attention mechanism to incorporate it into the generation process, while utilizing the content feature as a negative prompt to further dissociate content information. Finally, we incorporate these strategies into StyleTex to obtain stylized textures. The resulting textures generated by StyleTex retain the style of the reference image, while also aligning with the text prompts and intrinsic details of the given 3D mesh. Quantitative and qualitative experiments show that our method outperforms existing baseline methods by a significant margin.
Decoupling Contact for Fine-Grained Motion Style Transfer
Sep 09, 2024Motion style transfer changes the style of a motion while retaining its content and is useful in computer animations and games. Contact is an essential component of motion style transfer that should be controlled explicitly in order to express the style vividly while enhancing motion naturalness and quality. However, it is unknown how to decouple and control contact to achieve fine-grained control in motion style transfer. In this paper, we present a novel style transfer method for fine-grained control over contacts while achieving both motion naturalness and spatial-temporal variations of style. Based on our empirical evidence, we propose controlling contact indirectly through the hip velocity, which can be further decomposed into the trajectory and contact timing, respectively. To this end, we propose a new model that explicitly models the correlations between motions and trajectory/contact timing/style, allowing us to decouple and control each separately. Our approach is built around a motion manifold, where hip controls can be easily integrated into a Transformer-based decoder. It is versatile in that it can generate motions directly as well as be used as post-processing for existing methods to improve quality and contact controllability. In addition, we propose a new metric that measures a correlation pattern of motions based on our empirical evidence, aligning well with human perception in terms of motion naturalness. Based on extensive evaluation, our method outperforms existing methods in terms of style expressivity and motion quality.
Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
Apr 16, 2024
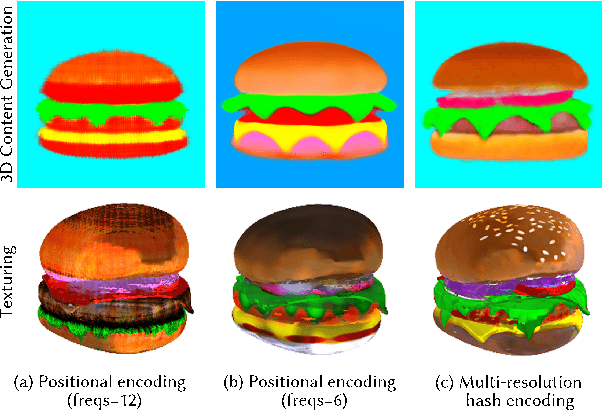
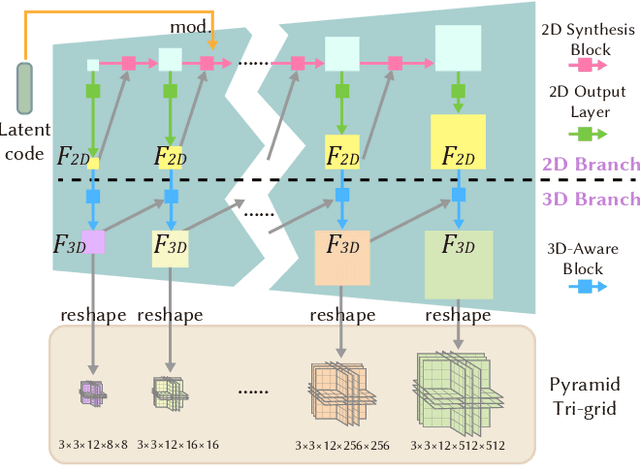
Existing neural rendering-based text-to-3D-portrait generation methods typically make use of human geometry prior and diffusion models to obtain guidance. However, relying solely on geometry information introduces issues such as the Janus problem, over-saturation, and over-smoothing. We present Portrait3D, a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation that overcomes the aforementioned issues. To accomplish this, we train a 3D portrait generator, 3DPortraitGAN-Pyramid, as a robust prior. This generator is capable of producing 360{\deg} canonical 3D portraits, serving as a starting point for the subsequent diffusion-based generation process. To mitigate the "grid-like" artifact caused by the high-frequency information in the feature-map-based 3D representation commonly used by most 3D-aware GANs, we integrate a novel pyramid tri-grid 3D representation into 3DPortraitGAN-Pyramid. To generate 3D portraits from text, we first project a randomly generated image aligned with the given prompt into the pre-trained 3DPortraitGAN-Pyramid's latent space. The resulting latent code is then used to synthesize a pyramid tri-grid. Beginning with the obtained pyramid tri-grid, we use score distillation sampling to distill the diffusion model's knowledge into the pyramid tri-grid. Following that, we utilize the diffusion model to refine the rendered images of the 3D portrait and then use these refined images as training data to further optimize the pyramid tri-grid, effectively eliminating issues with unrealistic color and unnatural artifacts. Our experimental results show that Portrait3D can produce realistic, high-quality, and canonical 3D portraits that align with the prompt.
Learning Full-Head 3D GANs from a Single-View Portrait Dataset
Jul 27, 2023



33D-aware face generators are commonly trained on 2D real-life face image datasets. Nevertheless, existing facial recognition methods often struggle to extract face data captured from various camera angles. Furthermore, in-the-wild images with diverse body poses introduce a high-dimensional challenge for 3D-aware generators, making it difficult to utilize data that contains complete neck and shoulder regions. Consequently, these face image datasets often contain only near-frontal face data, which poses challenges for 3D-aware face generators to construct \textit{full-head} 3D portraits. To this end, we first create the dataset {$\it{360}^{\circ}$}-\textit{Portrait}-\textit{HQ} (\textit{$\it{360}^{\circ}$PHQ}), which consists of high-quality single-view real portraits annotated with a variety of camera parameters {(the yaw angles span the entire $360^{\circ}$ range)} and body poses. We then propose \textit{3DPortraitGAN}, the first 3D-aware full-head portrait generator that learns a canonical 3D avatar distribution from the body-pose-various \textit{$\it{360}^{\circ}$PHQ} dataset with body pose self-learning. Our model can generate view-consistent portrait images from all camera angles (${360}^{\circ}$) with a full-head 3D representation. We incorporate a mesh-guided deformation field into volumetric rendering to produce deformed results to generate portrait images that conform to the body pose distribution of the dataset using our canonical generator. We integrate two pose predictors into our framework to predict more accurate body poses to address the issue of inaccurately estimated body poses in our dataset. Our experiments show that the proposed framework can generate view-consistent, realistic portrait images with complete geometry from all camera angles and accurately predict portrait body pose.