 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Contact for Fine-Grained Motion Style Transfer
Sep 09, 2024Motion style transfer changes the style of a motion while retaining its content and is useful in computer animations and games. Contact is an essential component of motion style transfer that should be controlled explicitly in order to express the style vividly while enhancing motion naturalness and quality. However, it is unknown how to decouple and control contact to achieve fine-grained control in motion style transfer. In this paper, we present a novel style transfer method for fine-grained control over contacts while achieving both motion naturalness and spatial-temporal variations of style. Based on our empirical evidence, we propose controlling contact indirectly through the hip velocity, which can be further decomposed into the trajectory and contact timing, respectively. To this end, we propose a new model that explicitly models the correlations between motions and trajectory/contact timing/style, allowing us to decouple and control each separately. Our approach is built around a motion manifold, where hip controls can be easily integrated into a Transformer-based decoder. It is versatile in that it can generate motions directly as well as be used as post-processing for existing methods to improve quality and contact controllability. In addition, we propose a new metric that measures a correlation pattern of motions based on our empirical evidence, aligning well with human perception in terms of motion naturalness. Based on extensive evaluation, our method outperforms existing methods in terms of style expressivity and motion quality.
RSMT: Real-time Stylized Motion Transition for Characters
Jun 21, 2023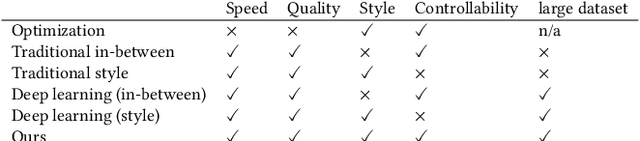
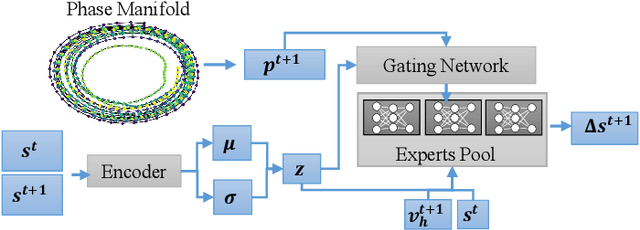
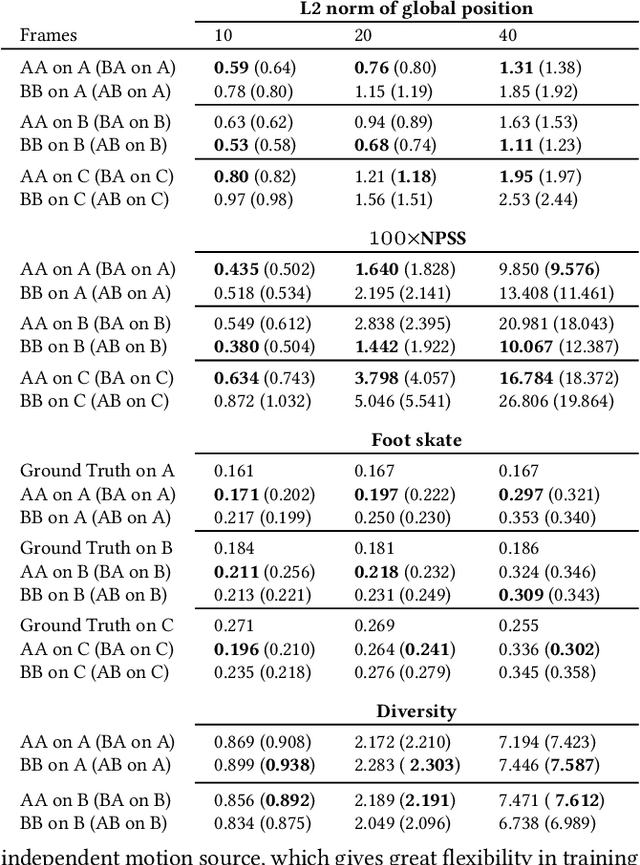
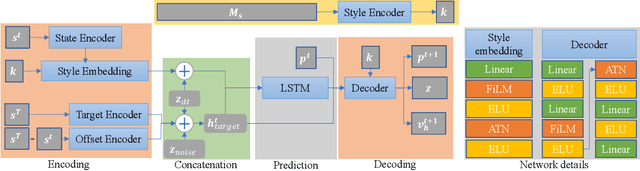
Styled online in-between motion generation has important application scenarios in computer animation and games. Its core challenge lies in the need to satisfy four critical requirements simultaneously: generation speed, motion quality, style diversity, and synthesis controllability. While the first two challenges demand a delicate balance between simple fast models and learning capacity for generation quality, the latter two are rarely investigated together in existing methods, which largely focus on either control without style or uncontrolled stylized motions. To this end, we propose a Real-time Stylized Motion Transition method (RSMT) to achieve all aforementioned goals. Our method consists of two critical, independent components: a general motion manifold model and a style motion sampler. The former acts as a high-quality motion source and the latter synthesizes styled motions on the fly under control signals. Since both components can be trained separately on different datasets, our method provides great flexibility, requires less data, and generalizes well when no/few samples are available for unseen styles. Through exhaustive evaluation, our method proves to be fast, high-quality, versatile, and controllable. The code and data are available at {https://github.com/yuyujunjun/RSMT-Realtime-Stylized-Motion-Transition.}
FAIVConf: Face enhancement for AI-based Video Conference with Low Bit-rate
Jul 08, 2022
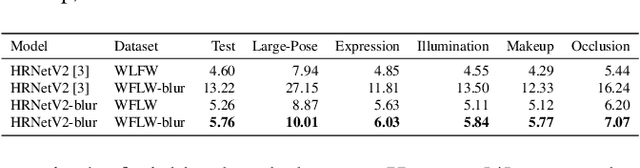
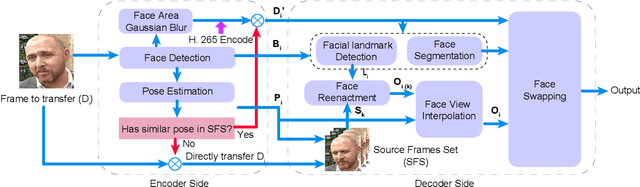
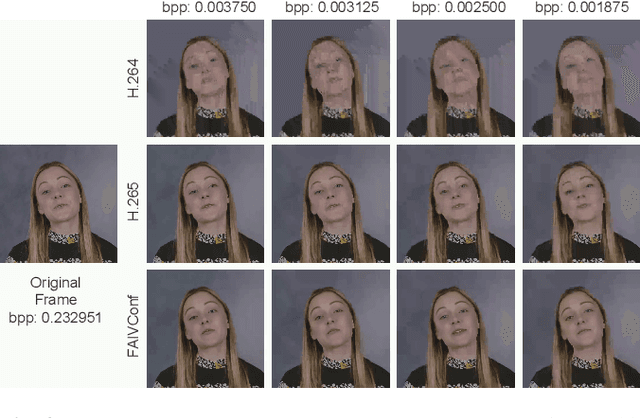
Recently, high-quality video conferencing with fewer transmission bits has become a very hot and challenging problem. We propose FAIVConf, a specially designed video compression framework for video conferencing, based on the effective neural human face generation techniques. FAIVConf brings together several designs to improve the system robustness in real video conference scenarios: face-swapping to avoid artifacts in background animation; facial blurring to decrease transmission bit-rate and maintain the quality of extracted facial landmarks; and dynamic source update for face view interpolation to accommodate a large range of head poses. Our method achieves a significant bit-rate reduction in the video conference and gives much better visual quality under the same bit-rate compared with H.264 and H.265 coding schemes.
Online Meta Adaptation for Variable-Rate Learned Image Compression
Nov 16, 2021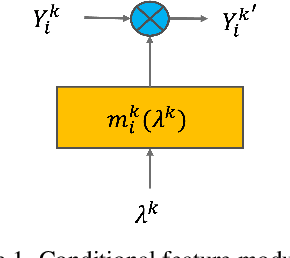
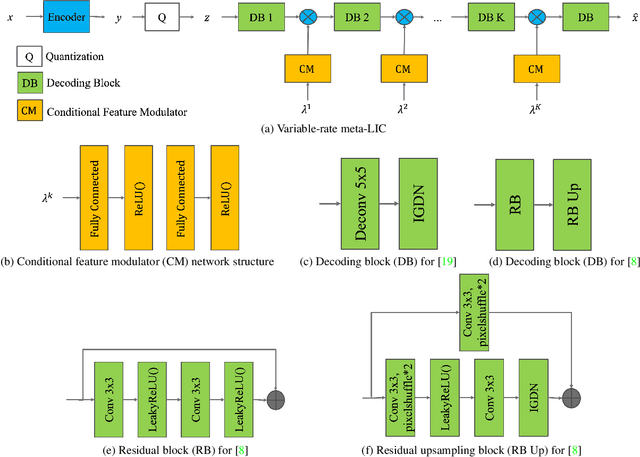
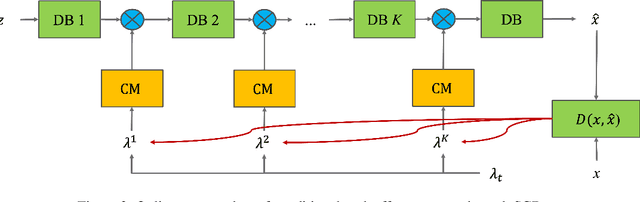
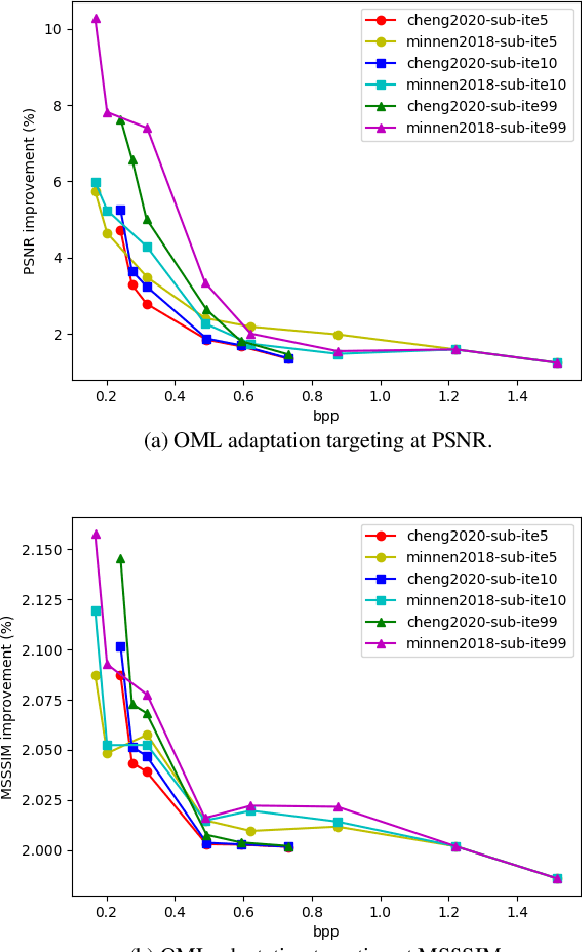
This work addresses two major issues of end-to-end learned image compression (LIC) based on deep neural networks: variable-rate learning where separate networks are required to generate compressed images with varying qualities, and the train-test mismatch between differentiable approximate quantization and true hard quantization. We introduce an online meta-learning (OML) setting for LIC, which combines ideas from meta learning and online learning in the conditional variational auto-encoder (CVAE) framework. By treating the conditional variables as meta parameters and treating the generated conditional features as meta priors, the desired reconstruction can be controlled by the meta parameters to accommodate compression with variable qualities. The online learning framework is used to update the meta parameters so that the conditional reconstruction is adaptively tuned for the current image. Through the OML mechanism, the meta parameters can be effectively updated through SGD. The conditional reconstruction is directly based on the quantized latent representation in the decoder network, and therefore helps to bridge the gap between the training estimation and true quantized latent distribution. Experiments demonstrate that our OML approach can be flexibly applied to different state-of-the-art LIC methods to achieve additional performance improvements with little computation and transmission overhead.
Efficient Micro-Structured Weight Unification and Pruning for Neural Network Compression
Jun 16, 2021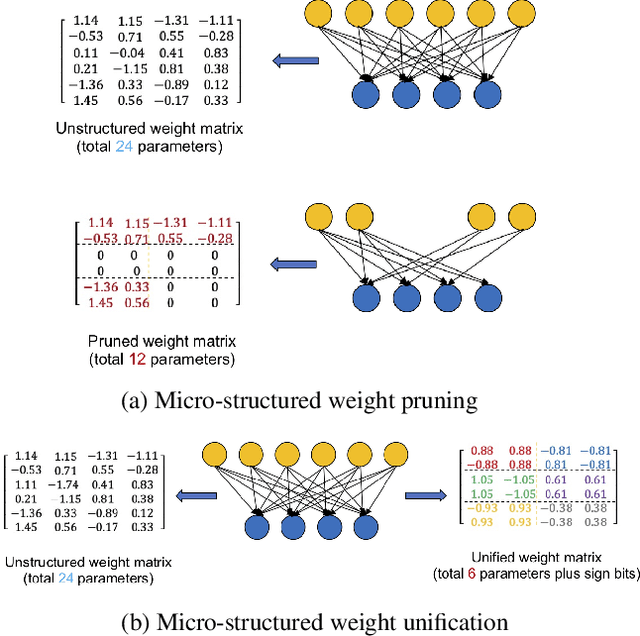

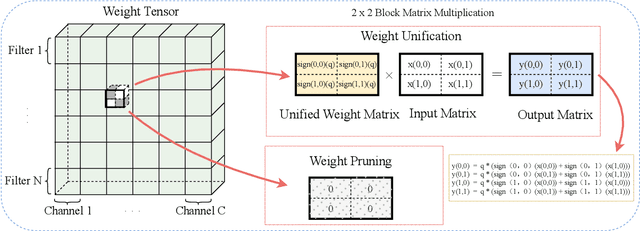
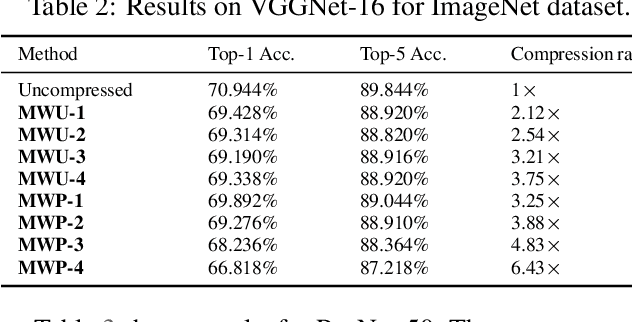
Compressing Deep Neural Network (DNN) models to alleviate the storage and computation requirements is essential for practical applications, especially for resource limited devices. Although capable of reducing a reasonable amount of model parameters, previous unstructured or structured weight pruning methods can hardly truly accelerate inference, either due to the poor hardware compatibility of the unstructured sparsity or due to the low sparse rate of the structurally pruned network. Aiming at reducing both storage and computation, as well as preserving the original task performance, we propose a generalized weight unification framework at a hardware compatible micro-structured level to achieve high amount of compression and acceleration. Weight coefficients of a selected micro-structured block are unified to reduce the storage and computation of the block without changing the neuron connections, which turns to a micro-structured pruning special case when all unified coefficients are set to zero, where neuron connections (hence storage and computation) are completely removed. In addition, we developed an effective training framework based on the alternating direction method of multipliers (ADMM), which converts our complex constrained optimization into separately solvable subproblems. Through iteratively optimizing the subproblems, the desired micro-structure can be ensured with high compression ratio and low performance degradation. We extensively evaluated our method using a variety of benchmark models and datasets for different applications. Experimental results demonstrate state-of-the-art performance.
End-to-End Denoising of Dark Burst Images Using Recurrent Fully Convolutional Networks
Apr 16, 2019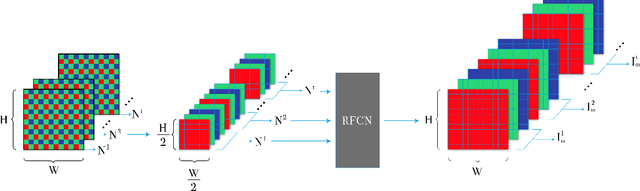
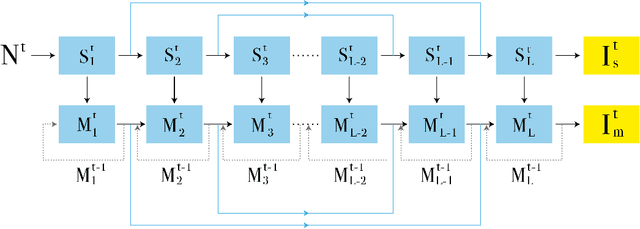


When taking photos in dim-light environments, due to the small amount of light entering, the shot images are usually extremely dark, with a great deal of noise, and the color cannot reflect real-world color. Under this condition, the traditional methods used for single image denoising have always failed to be effective. One common idea is to take multiple frames of the same scene to enhance the signal-to-noise ratio. This paper proposes a recurrent fully convolutional network (RFCN) to process burst photos taken under extremely low-light conditions, and to obtain denoised images with improved brightness. Our model maps raw burst images directly to sRGB outputs, either to produce a best image or to generate a multi-frame denoised image sequence. This process has proven to be capable of accomplishing the low-level task of denoising, as well as the high-level task of color correction and enhancement, all of which is end-to-end processing through our network. Our method has achieved better results than state-of-the-art methods. In addition, we have applied the model trained by one type of camera without fine-tuning on photos captured by different cameras and have obtained similar end-to-end enhancements.
MVF-Net: Multi-View 3D Face Morphable Model Regression
Apr 09, 2019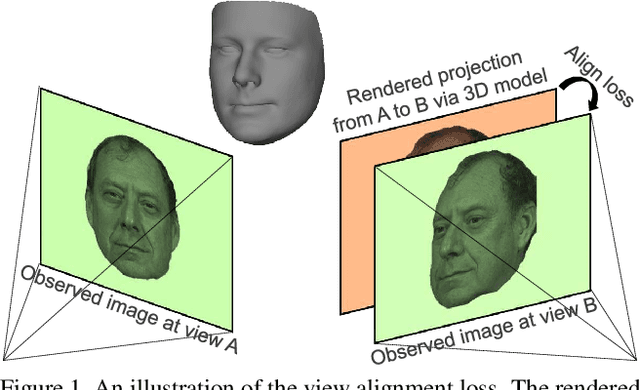
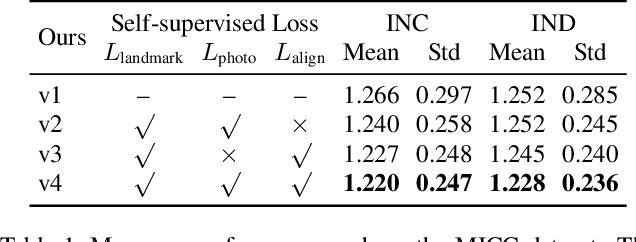
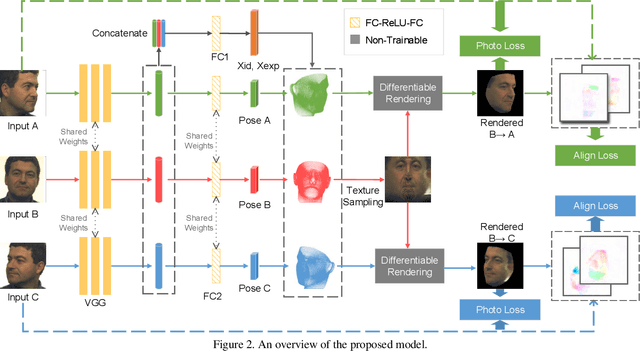
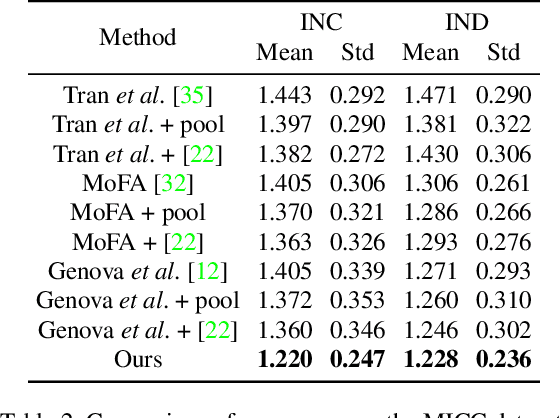
We address the problem of recovering the 3D geometry of a human face from a set of facial images in multiple views. While recent studies have shown impressive progress in 3D Morphable Model (3DMM) based facial reconstruction, the settings are mostly restricted to a single view. There is an inherent drawback in the single-view setting: the lack of reliable 3D constraints can cause unresolvable ambiguities. We in this paper explore 3DMM-based shape recovery in a different setting, where a set of multi-view facial images are given as input. A novel approach is proposed to regress 3DMM parameters from multi-view inputs with an end-to-end trainable Convolutional Neural Network (CNN). Multiview geometric constraints are incorporated into the network by establishing dense correspondences between different views leveraging a novel self-supervised view alignment loss. The main ingredient of the view alignment loss is a differentiable dense optical flow estimator that can backpropagate the alignment errors between an input view and a synthetic rendering from another input view, which is projected to the target view through the 3D shape to be inferred. Through minimizing the view alignment loss, better 3D shapes can be recovered such that the synthetic projections from one view to another can better align with the observed image. Extensive experiments demonstrate the superiority of the proposed method over other 3DMM methods.
3D Facial Expression Reconstruction using Cascaded Regression
Aug 17, 2018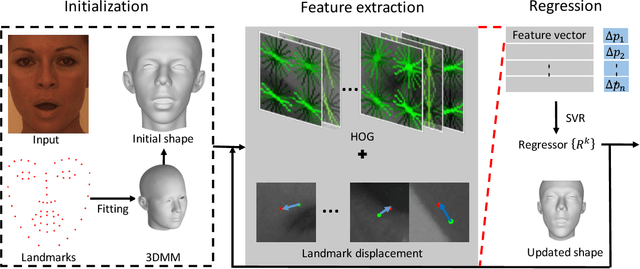
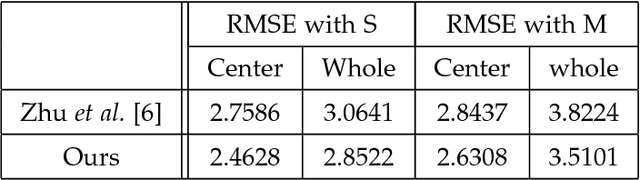
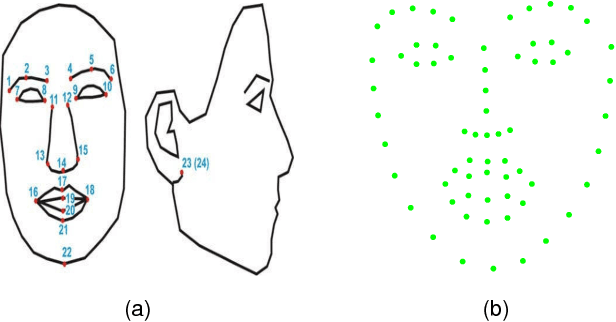
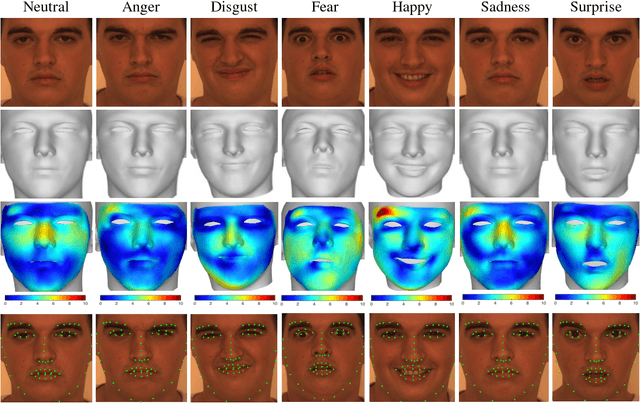
This paper proposes a novel model fitting algorithm for 3D facial expression reconstruction from a single image. Face expression reconstruction from a single image is a challenging task in computer vision. Most state-of-the-art methods fit the input image to a 3D Morphable Model (3DMM). These methods need to solve a stochastic problem and cannot deal with expression and pose variations. To solve this problem, we adopt a 3D face expression model and use a combined feature which is robust to scale, rotation and different lighting conditions. The proposed method applies a cascaded regression framework to estimate parameters for the 3DMM. 2D landmarks are detected and used to initialize the 3D shape and mapping matrices. In each iteration, residues between the current 3DMM parameters and the ground truth are estimated and then used to update the 3D shapes. The mapping matrices are also calculated based on the updated shapes and 2D landmarks. HOG features of the local patches and displacements between 3D landmark projections and 2D landmarks are exploited. Compared with existing methods, the proposed method is robust to expression and pose changes and can reconstruct higher fidelity 3D face shape.