 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynHAT: A Two-stage Coarse-to-Fine Diffusion Framework for Synthesizing Human Activity Traces
Apr 16, 2026Human activity traces (HATs) are critical for many applications, including human mobility modeling and point-of-interest (POI) recommendation. However, growing privacy concerns have severely limited access to authentic large-scale HAT datasets. Recent advances in generative AI provide new opportunities to synthesize realistic and privacy-preserving HATs for such applications. Yet two major challenges remain: (i) HATs are highly irregular and dynamic, with long and varying time intervals, making it difficult to capture their complex spatio-temporal dependencies and underlying distributions; and (ii) generative models are often computationally expensive, making long-term, fine-grained HAT synthesis inefficient. To address these challenges, we propose SynHAT, a computationally efficient coarse-to-fine HAT synthesis framework built on a novel spatio-temporal denoising diffusion model. In Stage 1, we develop Coarse-HADiff, which models the overall spatio-temporal dependencies of coarse-grained latent spatio-temporal traces. It incorporates a novel Latent Spatio-Temporal U-Net with dual Drift-Jitter branches to jointly model smooth spatial transitions and temporal variations during denoising. In Stage 2, we introduce a three-step pipeline consisting of Behavior Pattern Extraction, Fine-HADiff, which shares the same architecture as Coarse-HADiff, and Semantic Alignment to generate fine-grained latent spatio-temporal traces from the Stage 1 outputs. We extensively evaluate SynHAT in terms of data fidelity, utility, privacy, robustness, and scalability. Experiments on real-world HAT datasets from four cities across three countries show that SynHAT substantially outperforms state-of-the-art baselines, achieving 52% and 33% improvements on spatial and temporal metrics, respectively.
RewardFlow: Topology-Aware Reward Propagation on State Graphs for Agentic RL with Large Language Models
Mar 19, 2026Reinforcement learning (RL) holds significant promise for enhancing the agentic reasoning capabilities of large language models (LLMs) with external environments. However, the inherent sparsity of terminal rewards hinders fine-grained, state-level optimization. Although process reward modeling offers a promising alternative, training dedicated reward models often entails substantial computational costs and scaling difficulties. To address these challenges, we introduce RewardFlow, a lightweight method for estimating state-level rewards tailored to agentic reasoning tasks. RewardFlow leverages the intrinsic topological structure of states within reasoning trajectories by constructing state graphs. This enables an analysis of state-wise contributions to success, followed by topology-aware graph propagation to quantify contributions and yield objective, state-level rewards. When integrated as dense rewards for RL optimization, RewardFlow substantially outperforms prior RL baselines across four agentic reasoning benchmarks, demonstrating superior performance, robustness, and training efficiency. The implementation of RewardFlow is publicly available at https://github.com/tmlr-group/RewardFlow.
HealthMamba: An Uncertainty-aware Spatiotemporal Graph State Space Model for Effective and Reliable Healthcare Facility Visit Prediction
Feb 05, 2026Healthcare facility visit prediction is essential for optimizing healthcare resource allocation and informing public health policy. Despite advanced machine learning methods being employed for better prediction performance, existing works usually formulate this task as a time-series forecasting problem without considering the intrinsic spatial dependencies of different types of healthcare facilities, and they also fail to provide reliable predictions under abnormal situations such as public emergencies. To advance existing research, we propose HealthMamba, an uncertainty-aware spatiotemporal framework for accurate and reliable healthcare facility visit prediction. HealthMamba comprises three key components: (i) a Unified Spatiotemporal Context Encoder that fuses heterogeneous static and dynamic information, (ii) a novel Graph State Space Model called GraphMamba for hierarchical spatiotemporal modeling, and (iii) a comprehensive uncertainty quantification module integrating three uncertainty quantification mechanisms for reliable prediction. We evaluate HealthMamba on four large-scale real-world datasets from California, New York, Texas, and Florida. Results show HealthMamba achieves around 6.0% improvement in prediction accuracy and 3.5% improvement in uncertainty quantification over state-of-the-art baselines.
TVWorld: Foundations for Remote-Control TV Agents
Jan 19, 2026Recent large vision-language models (LVLMs) have demonstrated strong potential for device control. However, existing research has primarily focused on point-and-click (PnC) interaction, while remote-control (RC) interaction commonly encountered in everyday TV usage remains largely underexplored. To fill this gap, we introduce \textbf{TVWorld}, an offline graph-based abstraction of real-world TV navigation that enables reproducible and deployment-free evaluation. On this basis, we derive two complementary benchmarks that comprehensively assess TV-use capabilities: \textbf{TVWorld-N} for topology-aware navigation and \textbf{TVWorld-G} for focus-aware grounding. These benchmarks expose a key limitation of existing agents: insufficient topology awareness for focus-based, long-horizon TV navigation. Motivated by this finding, we propose a \emph{Topology-Aware Training} framework that injects topology awareness into LVLMs. Using this framework, we develop \textbf{TVTheseus}, a foundation model specialized for TV navigation. TVTheseus achieves a success rate of $68.3\%$ on TVWorld-N, surpassing strong closed-source baselines such as Gemini 3 Flash and establishing state-of-the-art (SOTA) performance. Additional analyses further provide valuable insights into the development of effective TV-use agents.
TrustEnergy: A Unified Framework for Accurate and Reliable User-level Energy Usage Prediction
Jan 19, 2026Energy usage prediction is important for various real-world applications, including grid management, infrastructure planning, and disaster response. Although a plethora of deep learning approaches have been proposed to perform this task, most of them either overlook the essential spatial correlations across households or fail to scale to individualized prediction, making them less effective for accurate fine-grained user-level prediction. In addition, due to the dynamic and uncertain nature of energy usage caused by various factors such as extreme weather events, quantifying uncertainty for reliable prediction is also significant, but it has not been fully explored in existing work. In this paper, we propose a unified framework called TrustEnergy for accurate and reliable user-level energy usage prediction. There are two key technical components in TrustEnergy, (i) a Hierarchical Spatiotemporal Representation module to efficiently capture both macro and micro energy usage patterns with a novel memory-augmented spatiotemporal graph neural network, and (ii) an innovative Sequential Conformalized Quantile Regression module to dynamically adjust uncertainty bounds to ensure valid prediction intervals over time, without making strong assumptions about the underlying data distribution. We implement and evaluate our TrustEnergy framework by working with an electricity provider in Florida, and the results show our TrustEnergy can achieve a 5.4% increase in prediction accuracy and 5.7% improvement in uncertainty quantification compared to state-of-the-art baselines.
XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
Jan 03, 2026Learning-based 3D visual geometry models have benefited substantially from large-scale transformers. Among these, StreamVGGT leverages frame-wise causal attention for strong streaming reconstruction, but suffers from unbounded KV cache growth, leading to escalating memory consumption and inference latency as input frames accumulate. We propose XStreamVGGT, a tuning-free approach that systematically compresses the KV cache through joint pruning and quantization, enabling extremely memory-efficient streaming inference. Specifically, redundant KVs originating from multi-view inputs are pruned through efficient token importance identification, enabling a fixed memory budget. Leveraging the unique distribution of KV tensors, we incorporate KV quantization to further reduce memory consumption. Extensive evaluations show that XStreamVGGT achieves mostly negligible performance degradation while substantially reducing memory usage by 4.42$\times$ and accelerating inference by 5.48$\times$, enabling scalable and practical streaming 3D applications. The code is available at https://github.com/ywh187/XStreamVGGT/.
GeoGen: A Two-stage Coarse-to-Fine Framework for Fine-grained Synthetic Location-based Social Network Trajectory Generation
Oct 09, 2025



Location-Based Social Network (LBSN) check-in trajectory data are important for many practical applications, like POI recommendation, advertising, and pandemic intervention. However, the high collection costs and ever-increasing privacy concerns prevent us from accessing large-scale LBSN trajectory data. The recent advances in synthetic data generation provide us with a new opportunity to achieve this, which utilizes generative AI to generate synthetic data that preserves the characteristics of real data while ensuring privacy protection. However, generating synthetic LBSN check-in trajectories remains challenging due to their spatially discrete, temporally irregular nature and the complex spatio-temporal patterns caused by sparse activities and uncertain human mobility. To address this challenge, we propose GeoGen, a two-stage coarse-to-fine framework for large-scale LBSN check-in trajectory generation. In the first stage, we reconstruct spatially continuous, temporally regular latent movement sequences from the original LBSN check-in trajectories and then design a Sparsity-aware Spatio-temporal Diffusion model (S$^2$TDiff) with an efficient denosing network to learn their underlying behavioral patterns. In the second stage, we design Coarse2FineNet, a Transformer-based Seq2Seq architecture equipped with a dynamic context fusion mechanism in the encoder and a multi-task hybrid-head decoder, which generates fine-grained LBSN trajectories based on coarse-grained latent movement sequences by modeling semantic relevance and behavioral uncertainty. Extensive experiments on four real-world datasets show that GeoGen excels state-of-the-art models for both fidelity and utility evaluation, e.g., it increases over 69% and 55% in distance and radius metrics on the FS-TKY dataset.
SWIRL: A Staged Workflow for Interleaved Reinforcement Learning in Mobile GUI Control
Aug 27, 2025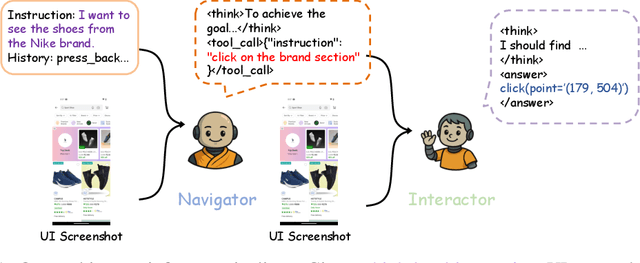
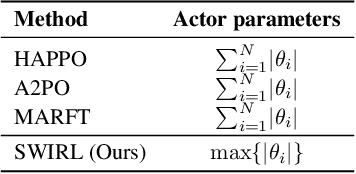
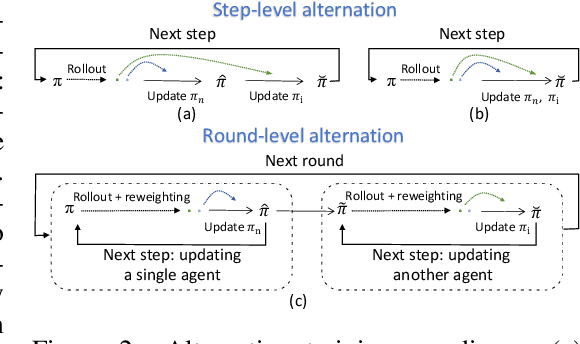

The rapid advancement of large vision language models (LVLMs) and agent systems has heightened interest in mobile GUI agents that can reliably translate natural language into interface operations. Existing single-agent approaches, however, remain limited by structural constraints. Although multi-agent systems naturally decouple different competencies, recent progress in multi-agent reinforcement learning (MARL) has often been hindered by inefficiency and remains incompatible with current LVLM architectures. To address these challenges, we introduce SWIRL, a staged workflow for interleaved reinforcement learning designed for multi-agent systems. SWIRL reformulates MARL into a sequence of single-agent reinforcement learning tasks, updating one agent at a time while keeping the others fixed. This formulation enables stable training and promotes efficient coordination across agents. Theoretically, we provide a stepwise safety bound, a cross-round monotonic improvement theorem, and convergence guarantees on return, ensuring robust and principled optimization. In application to mobile GUI control, SWIRL instantiates a Navigator that converts language and screen context into structured plans, and an Interactor that grounds these plans into executable atomic actions. Extensive experiments demonstrate superior performance on both high-level and low-level GUI benchmarks. Beyond GUI tasks, SWIRL also demonstrates strong capability in multi-agent mathematical reasoning, underscoring its potential as a general framework for developing efficient and robust multi-agent systems.
UQGNN: Uncertainty Quantification of Graph Neural Networks for Multivariate Spatiotemporal Prediction
Aug 12, 2025



Spatiotemporal prediction plays a critical role in numerous real-world applications such as urban planning, transportation optimization, disaster response, and pandemic control. In recent years, researchers have made significant progress by developing advanced deep learning models for spatiotemporal prediction. However, most existing models are deterministic, i.e., predicting only the expected mean values without quantifying uncertainty, leading to potentially unreliable and inaccurate outcomes. While recent studies have introduced probabilistic models to quantify uncertainty, they typically focus on a single phenomenon (e.g., taxi, bike, crime, or traffic crashes), thereby neglecting the inherent correlations among heterogeneous urban phenomena. To address the research gap, we propose a novel Graph Neural Network with Uncertainty Quantification, termed UQGNN for multivariate spatiotemporal prediction. UQGNN introduces two key innovations: (i) an Interaction-aware Spatiotemporal Embedding Module that integrates a multivariate diffusion graph convolutional network and an interaction-aware temporal convolutional network to effectively capture complex spatial and temporal interaction patterns, and (ii) a multivariate probabilistic prediction module designed to estimate both expected mean values and associated uncertainties. Extensive experiments on four real-world multivariate spatiotemporal datasets from Shenzhen, New York City, and Chicago demonstrate that UQGNN consistently outperforms state-of-the-art baselines in both prediction accuracy and uncertainty quantification. For example, on the Shenzhen dataset, UQGNN achieves a 5% improvement in both prediction accuracy and uncertainty quantification.
Uncertainty-aware Predict-Then-Optimize Framework for Equitable Post-Disaster Power Restoration
Aug 06, 2025The increasing frequency of extreme weather events, such as hurricanes, highlights the urgent need for efficient and equitable power system restoration. Many electricity providers make restoration decisions primarily based on the volume of power restoration requests from each region. However, our data-driven analysis reveals significant disparities in request submission volume, as disadvantaged communities tend to submit fewer restoration requests. This disparity makes the current restoration solution inequitable, leaving these communities vulnerable to extended power outages. To address this, we aim to propose an equity-aware power restoration strategy that balances both restoration efficiency and equity across communities. However, achieving this goal is challenging for two reasons: the difficulty of predicting repair durations under dataset heteroscedasticity, and the tendency of reinforcement learning agents to favor low-uncertainty actions, which potentially undermine equity. To overcome these challenges, we design a predict-then-optimize framework called EPOPR with two key components: (1) Equity-Conformalized Quantile Regression for uncertainty-aware repair duration prediction, and (2) Spatial-Temporal Attentional RL that adapts to varying uncertainty levels across regions for equitable decision-making. Experimental results show that our EPOPR effectively reduces the average power outage duration by 3.60% and decreases inequity between different communities by 14.19% compared to state-of-the-art baselines.