 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Densification in Gaussian Splatting for Faster 3D Scene Reconstruction
Jul 27, 20253D Gaussian Splatting (GS) has emerged as a powerful representation for high-quality scene reconstruction, offering compelling rendering quality. However, the training process of GS often suffers from slow convergence due to inefficient densification and suboptimal spatial distribution of Gaussian primitives. In this work, we present a comprehensive analysis of the split and clone operations during the densification phase, revealing their distinct roles in balancing detail preservation and computational efficiency. Building upon this analysis, we propose a global-to-local densification strategy, which facilitates more efficient growth of Gaussians across the scene space, promoting both global coverage and local refinement. To cooperate with the proposed densification strategy and promote sufficient diffusion of Gaussian primitives in space, we introduce an energy-guided coarse-to-fine multi-resolution training framework, which gradually increases resolution based on energy density in 2D images. Additionally, we dynamically prune unnecessary Gaussian primitives to speed up the training. Extensive experiments on MipNeRF-360, Deep Blending, and Tanks & Temples datasets demonstrate that our approach significantly accelerates training,achieving over 2x speedup with fewer Gaussian primitives and superior reconstruction performance.
Hybrid Mesh-Gaussian Representation for Efficient Indoor Scene Reconstruction
Jun 08, 20253D Gaussian splatting (3DGS) has demonstrated exceptional performance in image-based 3D reconstruction and real-time rendering. However, regions with complex textures require numerous Gaussians to capture significant color variations accurately, leading to inefficiencies in rendering speed. To address this challenge, we introduce a hybrid representation for indoor scenes that combines 3DGS with textured meshes. Our approach uses textured meshes to handle texture-rich flat areas, while retaining Gaussians to model intricate geometries. The proposed method begins by pruning and refining the extracted mesh to eliminate geometrically complex regions. We then employ a joint optimization for 3DGS and mesh, incorporating a warm-up strategy and transmittance-aware supervision to balance their contributions seamlessly.Extensive experiments demonstrate that the hybrid representation maintains comparable rendering quality and achieves superior frames per second FPS with fewer Gaussian primitives.
DnLUT: Ultra-Efficient Color Image Denoising via Channel-Aware Lookup Tables
Mar 20, 2025While deep neural networks have revolutionized image denoising capabilities, their deployment on edge devices remains challenging due to substantial computational and memory requirements. To this end, we present DnLUT, an ultra-efficient lookup table-based framework that achieves high-quality color image denoising with minimal resource consumption. Our key innovation lies in two complementary components: a Pairwise Channel Mixer (PCM) that effectively captures inter-channel correlations and spatial dependencies in parallel, and a novel L-shaped convolution design that maximizes receptive field coverage while minimizing storage overhead. By converting these components into optimized lookup tables post-training, DnLUT achieves remarkable efficiency - requiring only 500KB storage and 0.1% energy consumption compared to its CNN contestant DnCNN, while delivering 20X faster inference. Extensive experiments demonstrate that DnLUT outperforms all existing LUT-based methods by over 1dB in PSNR, establishing a new state-of-the-art in resource-efficient color image denoising. The project is available at https://github.com/Stephen0808/DnLUT.
OccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
Mar 20, 2025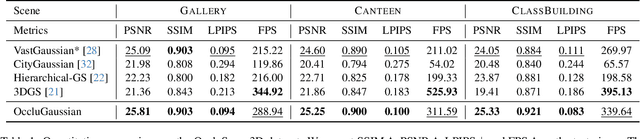
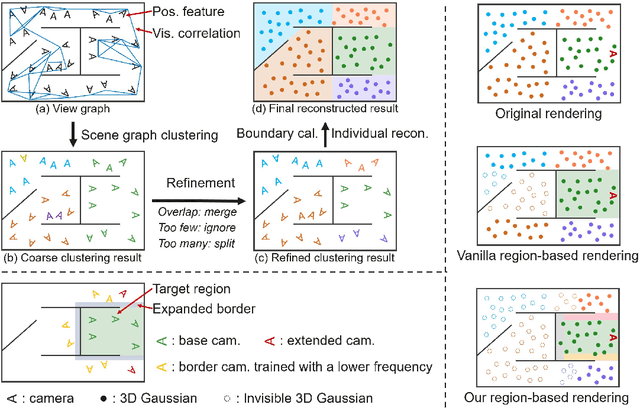
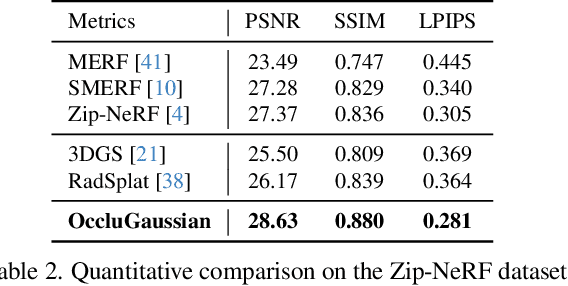
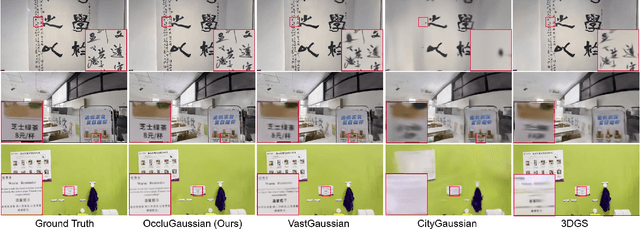
In large-scale scene reconstruction using 3D Gaussian splatting, it is common to partition the scene into multiple smaller regions and reconstruct them individually. However, existing division methods are occlusion-agnostic, meaning that each region may contain areas with severe occlusions. As a result, the cameras within those regions are less correlated, leading to a low average contribution to the overall reconstruction. In this paper, we propose an occlusion-aware scene division strategy that clusters training cameras based on their positions and co-visibilities to acquire multiple regions. Cameras in such regions exhibit stronger correlations and a higher average contribution, facilitating high-quality scene reconstruction. We further propose a region-based rendering technique to accelerate large scene rendering, which culls Gaussians invisible to the region where the viewpoint is located. Such a technique significantly speeds up the rendering without compromising quality. Extensive experiments on multiple large scenes show that our method achieves superior reconstruction results with faster rendering speed compared to existing state-of-the-art approaches. Project page: https://occlugaussian.github.io.
Decoupling Appearance Variations with 3D Consistent Features in Gaussian Splatting
Jan 18, 2025



Gaussian Splatting has emerged as a prominent 3D representation in novel view synthesis, but it still suffers from appearance variations, which are caused by various factors, such as modern camera ISPs, different time of day, weather conditions, and local light changes. These variations can lead to floaters and color distortions in the rendered images/videos. Recent appearance modeling approaches in Gaussian Splatting are either tightly coupled with the rendering process, hindering real-time rendering, or they only account for mild global variations, performing poorly in scenes with local light changes. In this paper, we propose DAVIGS, a method that decouples appearance variations in a plug-and-play and efficient manner. By transforming the rendering results at the image level instead of the Gaussian level, our approach can model appearance variations with minimal optimization time and memory overhead. Furthermore, our method gathers appearance-related information in 3D space to transform the rendered images, thus building 3D consistency across views implicitly. We validate our method on several appearance-variant scenes, and demonstrate that it achieves state-of-the-art rendering quality with minimal training time and memory usage, without compromising rendering speeds. Additionally, it provides performance improvements for different Gaussian Splatting baselines in a plug-and-play manner.
Poisoning-based Backdoor Attacks for Arbitrary Target Label with Positive Triggers
May 09, 2024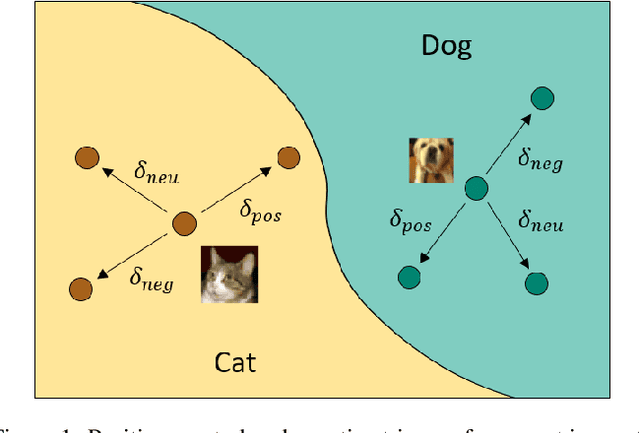



Poisoning-based backdoor attacks expose vulnerabilities in the data preparation stage of deep neural network (DNN) training. The DNNs trained on the poisoned dataset will be embedded with a backdoor, making them behave well on clean data while outputting malicious predictions whenever a trigger is applied. To exploit the abundant information contained in the input data to output label mapping, our scheme utilizes the network trained from the clean dataset as a trigger generator to produce poisons that significantly raise the success rate of backdoor attacks versus conventional approaches. Specifically, we provide a new categorization of triggers inspired by the adversarial technique and develop a multi-label and multi-payload Poisoning-based backdoor attack with Positive Triggers (PPT), which effectively moves the input closer to the target label on benign classifiers. After the classifier is trained on the poisoned dataset, we can generate an input-label-aware trigger to make the infected classifier predict any given input to any target label with a high possibility. Under both dirty- and clean-label settings, we show empirically that the proposed attack achieves a high attack success rate without sacrificing accuracy across various datasets, including SVHN, CIFAR10, GTSRB, and Tiny ImageNet. Furthermore, the PPT attack can elude a variety of classical backdoor defenses, proving its effectiveness.
Taming Lookup Tables for Efficient Image Retouching
Mar 28, 2024The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
Learning Spatially Collaged Fourier Bases for Implicit Neural Representation
Dec 28, 2023
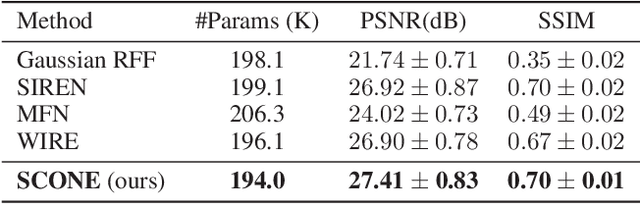
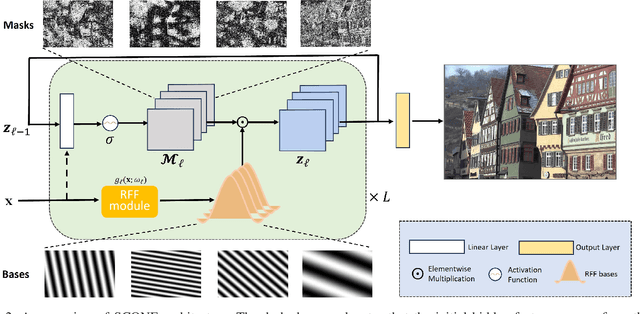
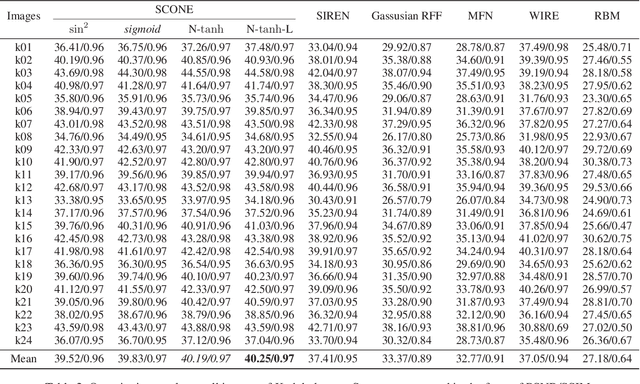
Existing approaches to Implicit Neural Representation (INR) can be interpreted as a global scene representation via a linear combination of Fourier bases of different frequencies. However, such universal basis functions can limit the representation capability in local regions where a specific component is unnecessary, resulting in unpleasant artifacts. To this end, we introduce a learnable spatial mask that effectively dispatches distinct Fourier bases into respective regions. This translates into collaging Fourier patches, thus enabling an accurate representation of complex signals. Comprehensive experiments demonstrate the superior reconstruction quality of the proposed approach over existing baselines across various INR tasks, including image fitting, video representation, and 3D shape representation. Our method outperforms all other baselines, improving the image fitting PSNR by over 3dB and 3D reconstruction to 98.81 IoU and 0.0011 Chamfer Distance.
Hundred-Kilobyte Lookup Tables for Efficient Single-Image Super-Resolution
Dec 11, 2023Conventional super-resolution (SR) schemes make heavy use of convolutional neural networks (CNNs), which involve intensive multiply-accumulate (MAC) operations, and require specialized hardware such as graphics processing units. This contradicts the regime of edge AI that often runs on devices strained by power, computing, and storage resources. Such a challenge has motivated a series of lookup table (LUT)-based SR schemes that employ simple LUT readout and largely elude CNN computation. Nonetheless, the multi-megabyte LUTs in existing methods still prohibit on-chip storage and necessitate off-chip memory transport. This work tackles this storage hurdle and innovates hundred-kilobyte LUT (HKLUT) models amenable to on-chip cache. Utilizing an asymmetric two-branch multistage network coupled with a suite of specialized kernel patterns, HKLUT demonstrates an uncompromising performance and superior hardware efficiency over existing LUT schemes.
Lite it fly: An All-Deformable-Butterfly Network
Nov 14, 2023

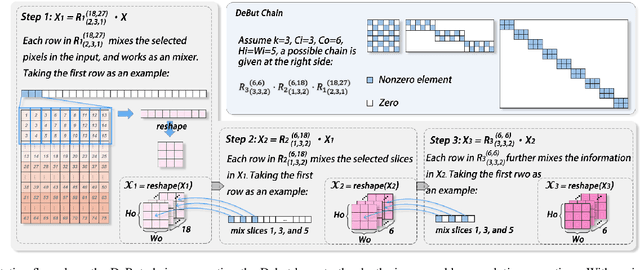

Most deep neural networks (DNNs) consist fundamentally of convolutional and/or fully connected layers, wherein the linear transform can be cast as the product between a filter matrix and a data matrix obtained by arranging feature tensors into columns. The lately proposed deformable butterfly (DeBut) decomposes the filter matrix into generalized, butterflylike factors, thus achieving network compression orthogonal to the traditional ways of pruning or low-rank decomposition. This work reveals an intimate link between DeBut and a systematic hierarchy of depthwise and pointwise convolutions, which explains the empirically good performance of DeBut layers. By developing an automated DeBut chain generator, we show for the first time the viability of homogenizing a DNN into all DeBut layers, thus achieving an extreme sparsity and compression. Various examples and hardware benchmarks verify the advantages of All-DeBut networks. In particular, we show it is possible to compress a PointNet to < 5% parameters with < 5% accuracy drop, a record not achievable by other compression schemes.