 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom In, Reason Out: Efficient Far-field Anomaly Detection in Expressway Surveillance Videos via Focused VLM Reasoning Guided by Bayesian Inference
Apr 28, 2026Expressway video anomaly detection is essential for safety management. However, identifying anomalies across diverse scenes remains challenging, particularly for far-field targets exhibiting subtle abnormal vehicle motions. While Vision-Language Models (VLMs) demonstrate strong semantic reasoning capabilities, processing global frames causes attention dilution for these far-field objects and incurs prohibitive computational costs. To address these issues, we propose VIBES, an asynchronous collaborative framework utilizing VLMs guided by Bayesian inference. Specifically, to overcome poor generalization across varying expressway environments, we introduce an online Bayesian inference module. This module continuously evaluates vehicle trajectories to dynamically update the probabilistic boundaries of normal driving behaviors, serving as an asynchronous trigger to precisely localize anomalies in space and time. Instead of processing the continuous video stream, the VLM processes only the localized visual regions indicated by the trigger. This targeted visual input prevents attention dilution and enables accurate semantic reasoning. Extensive evaluations demonstrate that VIBES improves detection accuracy for far-field anomalies and reduces computational overhead, achieving high real-time efficiency and explainability while demonstrating generalization across diverse expressway conditions.
Towards Instance Segmentation with Polygon Detection Transformers
Mar 10, 2026One of the bottlenecks for instance segmentation today lies in the conflicting requirements of high-resolution inputs and lightweight, real-time inference. To address this bottleneck, we present a Polygon Detection Transformer (Poly-DETR) to reformulate instance segmentation as sparse vertex regression via Polar Representation, thereby eliminating the reliance on dense pixel-wise mask prediction. Considering the box-to-polygon reference shift in Detection Transformers, we propose Polar Deformable Attention and Position-Aware Training Scheme to dynamically update supervision and focus attention on boundary cues. Compared with state-of-the-art polar-based methods, Poly-DETR achieves a 4.7 mAP improvement on MS COCO test-dev. Moreover, we construct a parallel mask-based counterpart to support a systematic comparison between polar and mask representations. Experimental results show that Poly-DETR is more lightweight in high-resolution scenarios, reducing memory consumption by almost half on Cityscapes dataset. Notably, on PanNuke (cell segmentation) and SpaceNet (building footprints) datasets, Poly-DETR surpasses its mask-based counterpart on all metrics, which validates its advantage on regular-shaped instances in domain-specific settings.
StochEP: Stochastic Equilibrium Propagation for Spiking Convergent Recurrent Neural Networks
Nov 14, 2025Spiking Neural Networks (SNNs) promise energy-efficient, sparse, biologically inspired computation. Training them with Backpropagation Through Time (BPTT) and surrogate gradients achieves strong performance but remains biologically implausible. Equilibrium Propagation (EP) provides a more local and biologically grounded alternative. However, existing EP frameworks, primarily based on deterministic neurons, either require complex mechanisms to handle discontinuities in spiking dynamics or fail to scale beyond simple visual tasks. Inspired by the stochastic nature of biological spiking mechanism and recent hardware trends, we propose a stochastic EP framework that integrates probabilistic spiking neurons into the EP paradigm. This formulation smoothens the optimization landscape, stabilizes training, and enables scalable learning in deep convolutional spiking convergent recurrent neural networks (CRNNs). We provide theoretical guarantees showing that the proposed stochastic EP dynamics approximate deterministic EP under mean-field theory, thereby inheriting its underlying theoretical guarantees. The proposed framework narrows the gap to both BPTT-trained SNNs and EP-trained non-spiking CRNNs in vision benchmarks while preserving locality, highlighting stochastic EP as a promising direction for neuromorphic and on-chip learning.
Hybrid Mesh-Gaussian Representation for Efficient Indoor Scene Reconstruction
Jun 08, 20253D Gaussian splatting (3DGS) has demonstrated exceptional performance in image-based 3D reconstruction and real-time rendering. However, regions with complex textures require numerous Gaussians to capture significant color variations accurately, leading to inefficiencies in rendering speed. To address this challenge, we introduce a hybrid representation for indoor scenes that combines 3DGS with textured meshes. Our approach uses textured meshes to handle texture-rich flat areas, while retaining Gaussians to model intricate geometries. The proposed method begins by pruning and refining the extracted mesh to eliminate geometrically complex regions. We then employ a joint optimization for 3DGS and mesh, incorporating a warm-up strategy and transmittance-aware supervision to balance their contributions seamlessly.Extensive experiments demonstrate that the hybrid representation maintains comparable rendering quality and achieves superior frames per second FPS with fewer Gaussian primitives.
Toward Spiking Neural Network Local Learning Modules Resistant to Adversarial Attacks
Apr 11, 2025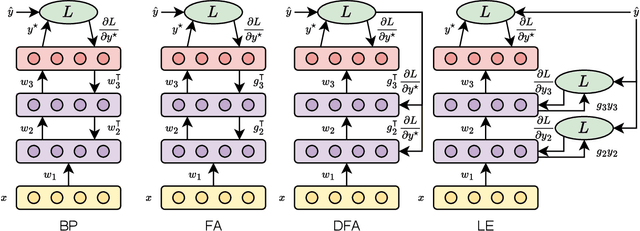
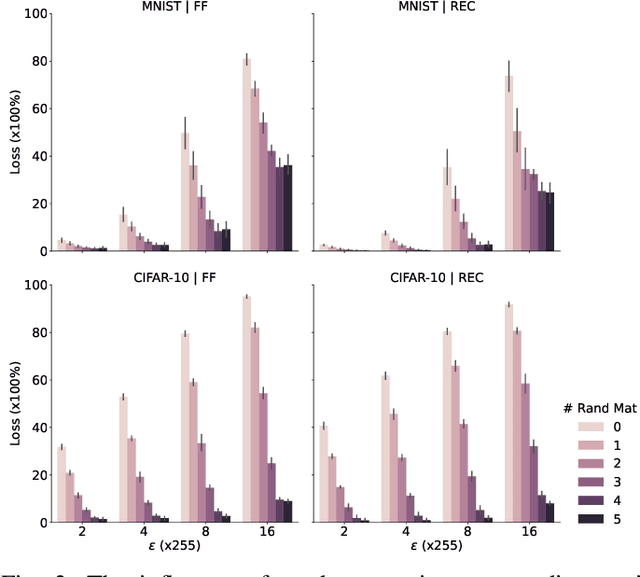
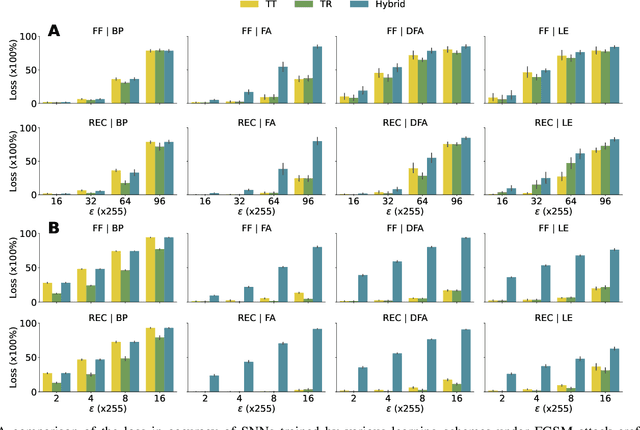
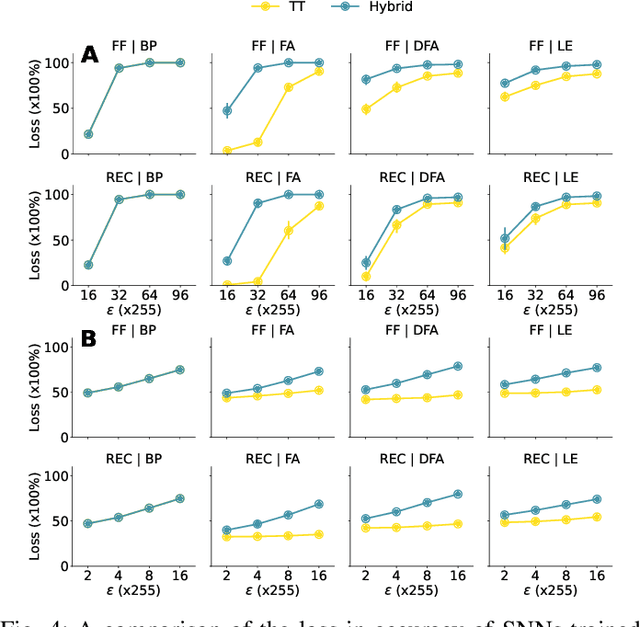
Recent research has shown the vulnerability of Spiking Neural Networks (SNNs) under adversarial examples that are nearly indistinguishable from clean data in the context of frame-based and event-based information. The majority of these studies are constrained in generating adversarial examples using Backpropagation Through Time (BPTT), a gradient-based method which lacks biological plausibility. In contrast, local learning methods, which relax many of BPTT's constraints, remain under-explored in the context of adversarial attacks. To address this problem, we examine adversarial robustness in SNNs through the framework of four types of training algorithms. We provide an in-depth analysis of the ineffectiveness of gradient-based adversarial attacks to generate adversarial instances in this scenario. To overcome these limitations, we introduce a hybrid adversarial attack paradigm that leverages the transferability of adversarial instances. The proposed hybrid approach demonstrates superior performance, outperforming existing adversarial attack methods. Furthermore, the generalizability of the method is assessed under multi-step adversarial attacks, adversarial attacks in black-box FGSM scenarios, and within the non-spiking domain.
Decoupling Appearance Variations with 3D Consistent Features in Gaussian Splatting
Jan 18, 2025



Gaussian Splatting has emerged as a prominent 3D representation in novel view synthesis, but it still suffers from appearance variations, which are caused by various factors, such as modern camera ISPs, different time of day, weather conditions, and local light changes. These variations can lead to floaters and color distortions in the rendered images/videos. Recent appearance modeling approaches in Gaussian Splatting are either tightly coupled with the rendering process, hindering real-time rendering, or they only account for mild global variations, performing poorly in scenes with local light changes. In this paper, we propose DAVIGS, a method that decouples appearance variations in a plug-and-play and efficient manner. By transforming the rendering results at the image level instead of the Gaussian level, our approach can model appearance variations with minimal optimization time and memory overhead. Furthermore, our method gathers appearance-related information in 3D space to transform the rendered images, thus building 3D consistency across views implicitly. We validate our method on several appearance-variant scenes, and demonstrate that it achieves state-of-the-art rendering quality with minimal training time and memory usage, without compromising rendering speeds. Additionally, it provides performance improvements for different Gaussian Splatting baselines in a plug-and-play manner.
Rethinking Spatio-Temporal Transformer for Traffic Prediction:Multi-level Multi-view Augmented Learning Framework
Jun 17, 2024Traffic prediction is a challenging spatio-temporal forecasting problem that involves highly complex spatio-temporal correlations. This paper proposes a Multi-level Multi-view Augmented Spatio-temporal Transformer (LVSTformer) for traffic prediction. The model aims to capture spatial dependencies from three different levels: local geographic, global semantic, and pivotal nodes, along with long- and short-term temporal dependencies. Specifically, we design three spatial augmented views to delve into the spatial information from the perspectives of local, global, and pivotal nodes. By combining three spatial augmented views with three parallel spatial self-attention mechanisms, the model can comprehensively captures spatial dependencies at different levels. We design a gated temporal self-attention mechanism to effectively capture long- and short-term temporal dependencies. Furthermore, a spatio-temporal context broadcasting module is introduced between two spatio-temporal layers to ensure a well-distributed allocation of attention scores, alleviating overfitting and information loss, and enhancing the generalization ability and robustness of the model. A comprehensive set of experiments is conducted on six well-known traffic benchmarks, the experimental results demonstrate that LVSTformer achieves state-of-the-art performance compared to competing baselines, with the maximum improvement reaching up to 4.32%.
MirrorGaussian: Reflecting 3D Gaussians for Reconstructing Mirror Reflections
May 20, 2024



3D Gaussian Splatting showcases notable advancements in photo-realistic and real-time novel view synthesis. However, it faces challenges in modeling mirror reflections, which exhibit substantial appearance variations from different viewpoints. To tackle this problem, we present MirrorGaussian, the first method for mirror scene reconstruction with real-time rendering based on 3D Gaussian Splatting. The key insight is grounded on the mirror symmetry between the real-world space and the virtual mirror space. We introduce an intuitive dual-rendering strategy that enables differentiable rasterization of both the real-world 3D Gaussians and the mirrored counterpart obtained by reflecting the former about the mirror plane. All 3D Gaussians are jointly optimized with the mirror plane in an end-to-end framework. MirrorGaussian achieves high-quality and real-time rendering in scenes with mirrors, empowering scene editing like adding new mirrors and objects. Comprehensive experiments on multiple datasets demonstrate that our approach significantly outperforms existing methods, achieving state-of-the-art results. Project page: https://mirror-gaussian.github.io/.
Scaling SNNs Trained Using Equilibrium Propagation to Convolutional Architectures
May 04, 2024Equilibrium Propagation (EP) is a biologically plausible local learning algorithm initially developed for convergent recurrent neural networks (RNNs), where weight updates rely solely on the connecting neuron states across two phases. The gradient calculations in EP have been shown to approximate the gradients computed by Backpropagation Through Time (BPTT) when an infinitesimally small nudge factor is used. This property makes EP a powerful candidate for training Spiking Neural Networks (SNNs), which are commonly trained by BPTT. However, in the spiking domain, previous studies on EP have been limited to architectures involving few linear layers. In this work, for the first time we provide a formulation for training convolutional spiking convergent RNNs using EP, bridging the gap between spiking and non-spiking convergent RNNs. We demonstrate that for spiking convergent RNNs, there is a mismatch in the maximum pooling and its inverse operation, leading to inaccurate gradient estimation in EP. Substituting this with average pooling resolves this issue and enables accurate gradient estimation for spiking convergent RNNs. We also highlight the memory efficiency of EP compared to BPTT. In the regime of SNNs trained by EP, our experimental results indicate state-of-the-art performance on the MNIST and FashionMNIST datasets, with test errors of 0.97% and 8.89%, respectively. These results are comparable to those of convergent RNNs and SNNs trained by BPTT. These findings underscore EP as an optimal choice for on-chip training and a biologically-plausible method for computing error gradients.
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Feb 27, 2024



Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.