 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign-based conformal prediction
Mar 02, 2023Conformal prediction is an assumption-lean approach to generating distribution-free prediction intervals or sets, for nearly arbitrary predictive models, with guaranteed finite-sample coverage. Conformal methods are an active research topic in statistics and machine learning, but only recently have they been extended to non-exchangeable data. In this paper, we invite survey methodologists to begin using and contributing to conformal methods. We introduce how conformal prediction can be applied to data from several common complex sample survey designs, under a framework of design-based inference for a finite population, and we point out gaps where survey methodologists could fruitfully apply their expertise. Our simulations empirically bear out the theoretical guarantees of finite-sample coverage, and our real-data example demonstrates how conformal prediction can be applied to complex sample survey data in practice.
Recall Distortion in Neural Network Pruning and the Undecayed Pruning Algorithm
Jun 08, 2022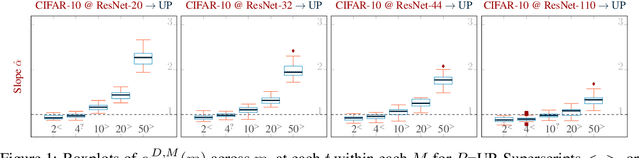
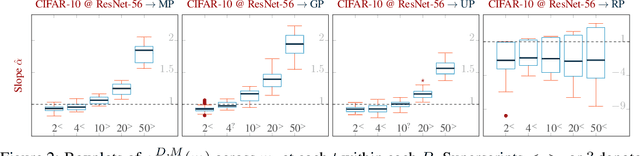
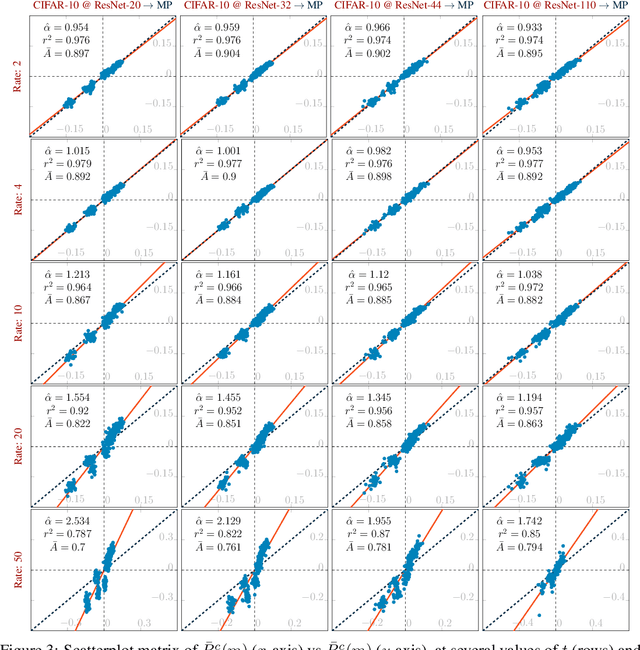
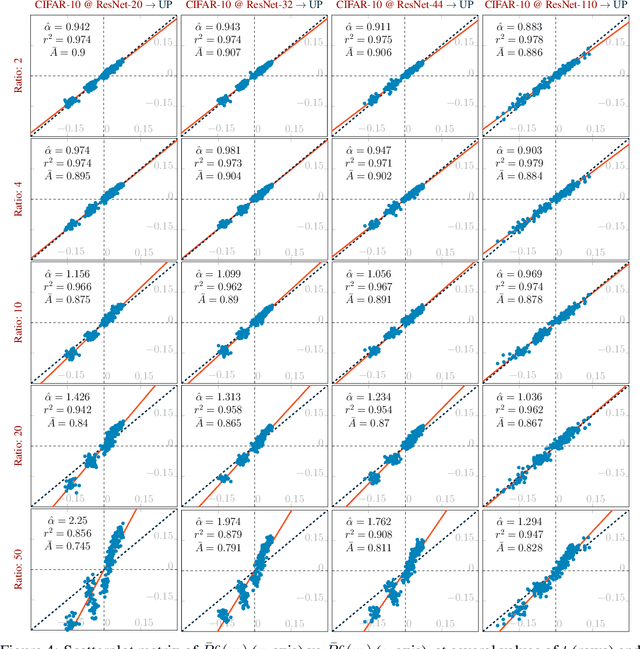
Pruning techniques have been successfully used in neural networks to trade accuracy for sparsity. However, the impact of network pruning is not uniform: prior work has shown that the recall for underrepresented classes in a dataset may be more negatively affected. In this work, we study such relative distortions in recall by hypothesizing an intensification effect that is inherent to the model. Namely, that pruning makes recall relatively worse for a class with recall below accuracy and, conversely, that it makes recall relatively better for a class with recall above accuracy. In addition, we propose a new pruning algorithm aimed at attenuating such effect. Through statistical analysis, we have observed that intensification is less severe with our algorithm but nevertheless more pronounced with relatively more difficult tasks, less complex models, and higher pruning ratios. More surprisingly, we conversely observe a de-intensification effect with lower pruning ratios.
Household poverty classification in data-scarce environments: a machine learning approach
Nov 18, 2017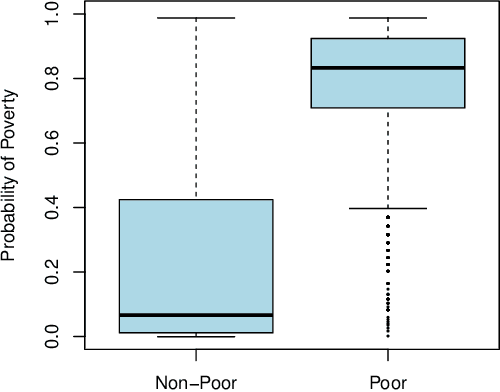
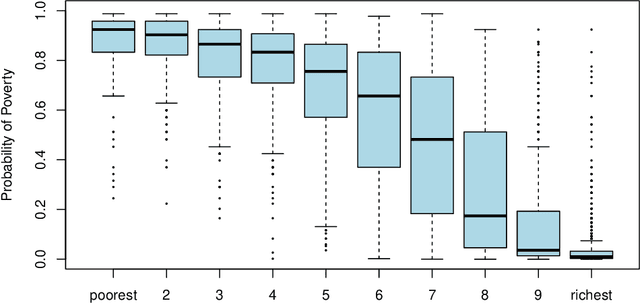
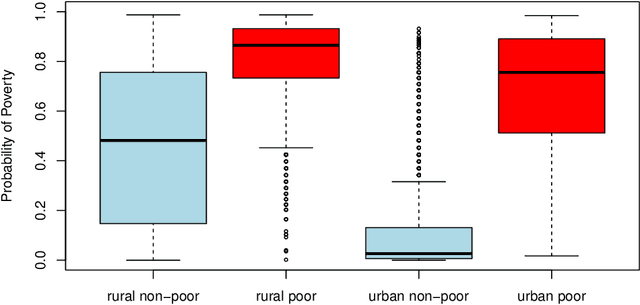
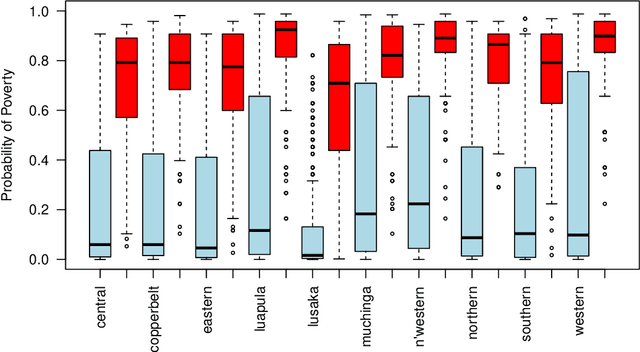
We describe a method to identify poor households in data-scarce countries by leveraging information contained in nationally representative household surveys. It employs standard statistical learning techniques---cross-validation and parameter regularization---which together reduce the extent to which the model is over-fitted to match the idiosyncracies of observed survey data. The automated framework satisfies three important constraints of this development setting: i) The prediction model uses at most ten questions, which limits the costs of data collection; ii) No computation beyond simple arithmetic is needed to calculate the probability that a given household is poor, immediately after data on the ten indicators is collected; and iii) One specification of the model (i.e. one scorecard) is used to predict poverty throughout a country that may be characterized by significant sub-national differences. Using survey data from Zambia, the model's out-of-sample predictions distinguish poor households from non-poor households using information contained in ten questions.