 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHousehold poverty classification in data-scarce environments: a machine learning approach
Paper and Code
Nov 18, 2017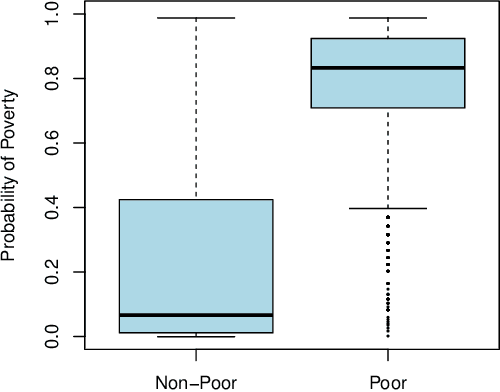
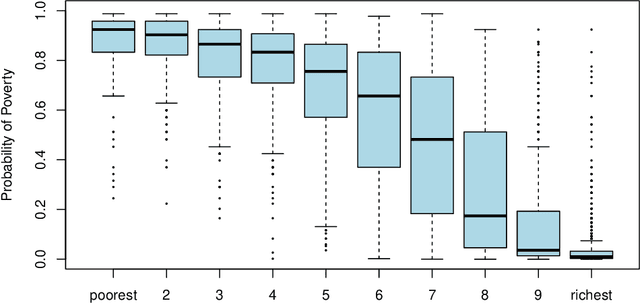
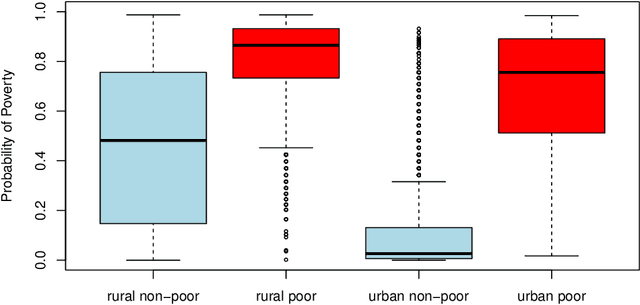
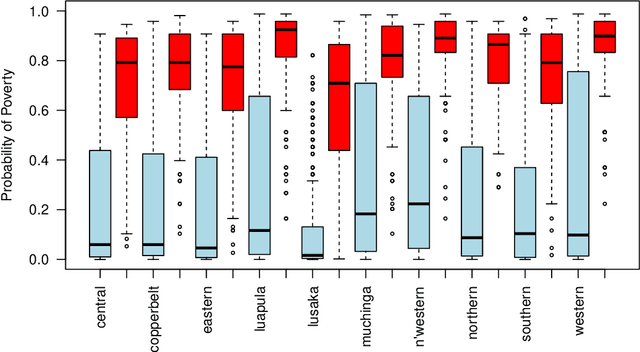
We describe a method to identify poor households in data-scarce countries by leveraging information contained in nationally representative household surveys. It employs standard statistical learning techniques---cross-validation and parameter regularization---which together reduce the extent to which the model is over-fitted to match the idiosyncracies of observed survey data. The automated framework satisfies three important constraints of this development setting: i) The prediction model uses at most ten questions, which limits the costs of data collection; ii) No computation beyond simple arithmetic is needed to calculate the probability that a given household is poor, immediately after data on the ten indicators is collected; and iii) One specification of the model (i.e. one scorecard) is used to predict poverty throughout a country that may be characterized by significant sub-national differences. Using survey data from Zambia, the model's out-of-sample predictions distinguish poor households from non-poor households using information contained in ten questions.