 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFF-FTNet: Multi-scale Feature Fusion across Frequency and Temporal Domains for Time Series Forecasting
Nov 26, 2024



Time series forecasting is crucial in many fields, yet current deep learning models struggle with noise, data sparsity, and capturing complex multi-scale patterns. This paper presents MFF-FTNet, a novel framework addressing these challenges by combining contrastive learning with multi-scale feature extraction across both frequency and time domains. MFF-FTNet introduces an adaptive noise augmentation strategy that adjusts scaling and shifting factors based on the statistical properties of the original time series data, enhancing model resilience to noise. The architecture is built around two complementary modules: a Frequency-Aware Contrastive Module (FACM) that refines spectral representations through frequency selection and contrastive learning, and a Complementary Time Domain Contrastive Module (CTCM) that captures both short- and long-term dependencies using multi-scale convolutions and feature fusion. A unified feature representation strategy enables robust contrastive learning across domains, creating an enriched framework for accurate forecasting. Extensive experiments on five real-world datasets demonstrate that MFF-FTNet significantly outperforms state-of-the-art models, achieving a 7.7% MSE improvement on multivariate tasks. These findings underscore MFF-FTNet's effectiveness in modeling complex temporal patterns and managing noise and sparsity, providing a comprehensive solution for both long- and short-term forecasting.
Reputation-Driven Asynchronous Federated Learning for Enhanced Trajectory Prediction with Blockchain
Jul 28, 2024Federated learning combined with blockchain empowers secure data sharing in autonomous driving applications. Nevertheless, with the increasing granularity and complexity of vehicle-generated data, the lack of data quality audits raises concerns about multi-party mistrust in trajectory prediction tasks. In response, this paper proposes an asynchronous federated learning data sharing method based on an interpretable reputation quantization mechanism utilizing graph neural network tools. Data providers share data structures under differential privacy constraints to ensure security while reducing redundant data. We implement deep reinforcement learning to categorize vehicles by reputation level, which optimizes the aggregation efficiency of federated learning. Experimental results demonstrate that the proposed data sharing scheme not only reinforces the security of the trajectory prediction task but also enhances prediction accuracy.
Rethinking Spatio-Temporal Transformer for Traffic Prediction:Multi-level Multi-view Augmented Learning Framework
Jun 17, 2024Traffic prediction is a challenging spatio-temporal forecasting problem that involves highly complex spatio-temporal correlations. This paper proposes a Multi-level Multi-view Augmented Spatio-temporal Transformer (LVSTformer) for traffic prediction. The model aims to capture spatial dependencies from three different levels: local geographic, global semantic, and pivotal nodes, along with long- and short-term temporal dependencies. Specifically, we design three spatial augmented views to delve into the spatial information from the perspectives of local, global, and pivotal nodes. By combining three spatial augmented views with three parallel spatial self-attention mechanisms, the model can comprehensively captures spatial dependencies at different levels. We design a gated temporal self-attention mechanism to effectively capture long- and short-term temporal dependencies. Furthermore, a spatio-temporal context broadcasting module is introduced between two spatio-temporal layers to ensure a well-distributed allocation of attention scores, alleviating overfitting and information loss, and enhancing the generalization ability and robustness of the model. A comprehensive set of experiments is conducted on six well-known traffic benchmarks, the experimental results demonstrate that LVSTformer achieves state-of-the-art performance compared to competing baselines, with the maximum improvement reaching up to 4.32%.
Enhanced Urban Region Profiling with Adversarial Self-Supervised Learning
Feb 02, 2024
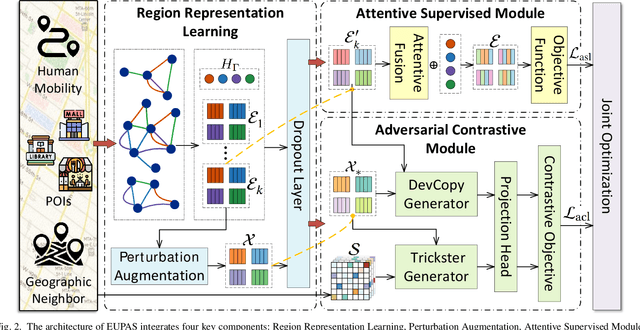
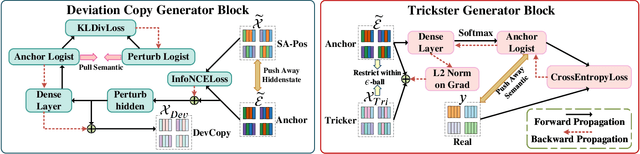
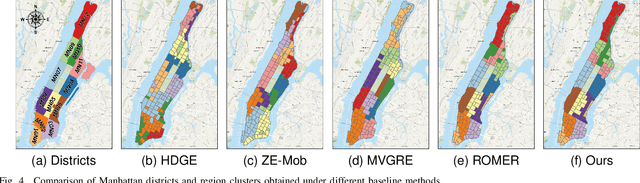
Urban region profiling is pivotal for smart cities, but mining fine-grained semantics from noisy and incomplete urban data remains challenging. In response, we propose a novel self-supervised graph collaborative filtering model for urban region embedding called EUPAS. Specifically, region heterogeneous graphs containing human mobility data, point of interests (POIs) information, and geographic neighborhood details for each region are fed into the model, which generates region embeddings that preserve intra-region and inter-region dependencies through GCNs and multi-head attention. Meanwhile, we introduce spatial perturbation augmentation to generate positive samples that are semantically similar and spatially close to the anchor, preparing for subsequent contrastive learning. Furthermore, adversarial training is employed to construct an effective pretext task by generating strong positive pairs and mining hard negative pairs for the region embeddings. Finally, we jointly optimize supervised and self-supervised learning to encourage the model to capture the high-level semantics of region embeddings while ignoring the noisy and unimportant details. Extensive experiments on real-world datasets demonstrate the superiority of our model over state-of-the-art methods.
Distillation Enhanced Time Series Forecasting Network with Momentum Contrastive Learning
Jan 31, 2024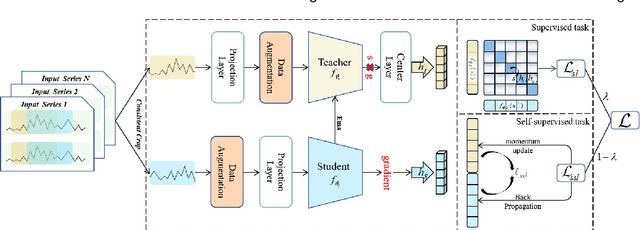

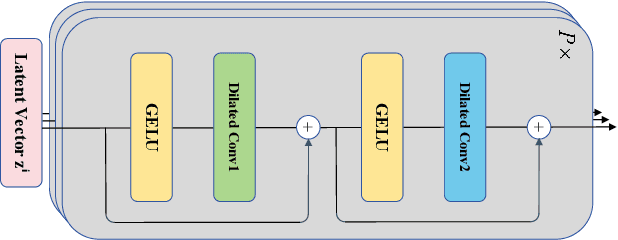
Contrastive representation learning is crucial in time series analysis as it alleviates the issue of data noise and incompleteness as well as sparsity of supervision signal. However, existing constrastive learning frameworks usually focus on intral-temporal features, which fails to fully exploit the intricate nature of time series data. To address this issue, we propose DE-TSMCL, an innovative distillation enhanced framework for long sequence time series forecasting. Specifically, we design a learnable data augmentation mechanism which adaptively learns whether to mask a timestamp to obtain optimized sub-sequences. Then, we propose a contrastive learning task with momentum update to explore inter-sample and intra-temporal correlations of time series to learn the underlying structure feature on the unlabeled time series. Meanwhile, we design a supervised task to learn more robust representations and facilitate the contrastive learning process. Finally, we jointly optimize the above two tasks. By developing model loss from multiple tasks, we can learn effective representations for downstream forecasting task. Extensive experiments, in comparison with state-of-the-arts, well demonstrate the effectiveness of DE-TSMCL, where the maximum improvement can reach to 27.3%.
Multi-behavior Recommendation with SVD Graph Neural Networks
Sep 13, 2023Graph Neural Networks (GNNs) has been extensively employed in the field of recommender systems, offering users personalized recommendations and yielding remarkable outcomes. Recently, GNNs incorporating contrastive learning have demonstrated promising performance in handling sparse data problem of recommendation system. However, existing contrastive learning methods still have limitations in addressing the cold-start problem and resisting noise interference especially for multi-behavior recommendation. To mitigate the aforementioned issues, the present research posits a GNNs based multi-behavior recommendation model MB-SVD that utilizes Singular Value Decomposition (SVD) graphs to enhance model performance. In particular, MB-SVD considers user preferences under different behaviors, improving recommendation effectiveness while better addressing the cold-start problem. Our model introduces an innovative methodology, which subsume multi-behavior contrastive learning paradigm to proficiently discern the intricate interconnections among heterogeneous manifestations of user behavior and generates SVD graphs to automate the distillation of crucial multi-behavior self-supervised information for robust graph augmentation. Furthermore, the SVD based framework reduces the embedding dimensions and computational load. Thorough experimentation showcases the remarkable performance of our proposed MB-SVD approach in multi-behavior recommendation endeavors across diverse real-world datasets.
Region-Wise Attentive Multi-View Representation Learning for Urban Region Embeddings
Jul 06, 2023Urban region embedding is an important and yet highly challenging issue due to the complexity and constantly changing nature of urban data. To address the challenges, we propose a Region-Wise Multi-View Representation Learning (ROMER) to capture multi-view dependencies and learn expressive representations of urban regions without the constraints of rigid neighbourhood region conditions. Our model focus on learn urban region representation from multi-source urban data. First, we capture the multi-view correlations from mobility flow patterns, POI semantics and check-in dynamics. Then, we adopt global graph attention networks to learn similarity of any two vertices in graphs. To comprehensively consider and share features of multiple views, a two-stage fusion module is further proposed to learn weights with external attention to fuse multi-view embeddings. Extensive experiments for two downstream tasks on real-world datasets demonstrate that our model outperforms state-of-the-art methods by up to 17\% improvement.
Hybrid Augmented Automated Graph Contrastive Learning
Mar 24, 2023Graph augmentations are essential for graph contrastive learning. Most existing works use pre-defined random augmentations, which are usually unable to adapt to different input graphs and fail to consider the impact of different nodes and edges on graph semantics. To address this issue, we propose a framework called Hybrid Augmented Automated Graph Contrastive Learning (HAGCL). HAGCL consists of a feature-level learnable view generator and an edge-level learnable view generator. The view generators are end-to-end differentiable to learn the probability distribution of views conditioned on the input graph. It insures to learn the most semantically meaningful structure in terms of features and topology, respectively. Furthermore, we propose an improved joint training strategy, which can achieve better results than previous works without resorting to any weak label information in the downstream tasks and extensive evaluation of additional work.