 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I See What You Did There": Can Large Vision-Language Models Understand Multimodal Puns?
Apr 07, 2026Puns are a common form of rhetorical wordplay that exploits polysemy and phonetic similarity to create humor. In multimodal puns, visual and textual elements synergize to ground the literal sense and evoke the figurative meaning simultaneously. Although Vision-Language Models (VLMs) are widely used in multimodal understanding and generation, their ability to understand puns has not been systematically studied due to a scarcity of rigorous benchmarks. To address this, we first propose a multimodal pun generation pipeline. We then introduce MultiPun, a dataset comprising diverse types of puns alongside adversarial non-pun distractors. Our evaluation reveals that most models struggle to distinguish genuine puns from these distractors. Moreover, we propose both prompt-level and model-level strategies to enhance pun comprehension, with an average improvement of 16.5% in F1 scores. Our findings provide valuable insights for developing future VLMs that master the subtleties of human-like humor via cross-modal reasoning.
Interlayer Error Calibration for Stacked Intelligent Metasurfaces:Modeling, Algorithms, and Future Perspectives
Mar 09, 2026Stacked intelligent metasurfaces (SIMs) have recently emerged as a key enabler for realizing electromagnetic wave-domain signal processing in next-generation wireless networks. However, practical SIM implementations often suffer from noticeable mismatches between theoretical models and measured responses due to fabrication and assembly imperfections. This article systematically investigates the problem of interlayer error calibration in SIMs. We first classify representative modeling and hardware-induced imperfections. Then, we outline the major challenges in SIM calibration and further develop a general framework that integrates a calibration protocol with the relevant solution strategies. Moreover, we investigate the effectiveness of the multi-stage calibration approach in mitigating geometric deviations and improving the alignment between the calibrated and practical propagation coefficients. Finally, we elaborate on key research opportunities and practical challenges toward realizing physically consistent and hardware-compliant SIM implementations for future research.
The Eminence in Shadow: Exploiting Feature Boundary Ambiguity for Robust Backdoor Attacks
Dec 17, 2025Deep neural networks (DNNs) underpin critical applications yet remain vulnerable to backdoor attacks, typically reliant on heuristic brute-force methods. Despite significant empirical advancements in backdoor research, the lack of rigorous theoretical analysis limits understanding of underlying mechanisms, constraining attack predictability and adaptability. Therefore, we provide a theoretical analysis targeting backdoor attacks, focusing on how sparse decision boundaries enable disproportionate model manipulation. Based on this finding, we derive a closed-form, ambiguous boundary region, wherein negligible relabeled samples induce substantial misclassification. Influence function analysis further quantifies significant parameter shifts caused by these margin samples, with minimal impact on clean accuracy, formally grounding why such low poison rates suffice for efficacious attacks. Leveraging these insights, we propose Eminence, an explainable and robust black-box backdoor framework with provable theoretical guarantees and inherent stealth properties. Eminence optimizes a universal, visually subtle trigger that strategically exploits vulnerable decision boundaries and effectively achieves robust misclassification with exceptionally low poison rates (< 0.1%, compared to SOTA methods typically requiring > 1%). Comprehensive experiments validate our theoretical discussions and demonstrate the effectiveness of Eminence, confirming an exponential relationship between margin poisoning and adversarial boundary manipulation. Eminence maintains > 90% attack success rate, exhibits negligible clean-accuracy loss, and demonstrates high transferability across diverse models, datasets and scenarios.
Enhanced Urban Region Profiling with Adversarial Self-Supervised Learning
Feb 02, 2024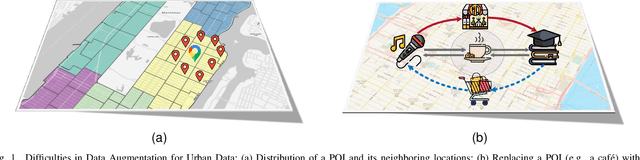
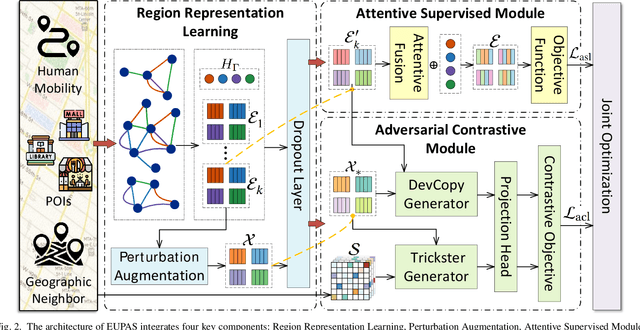
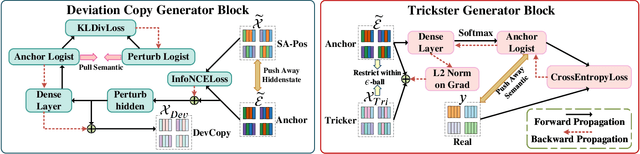
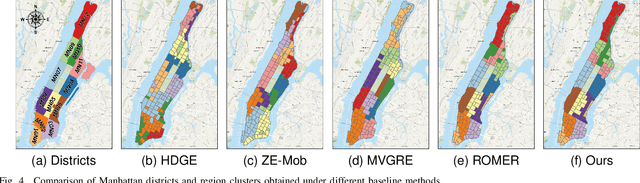
Urban region profiling is pivotal for smart cities, but mining fine-grained semantics from noisy and incomplete urban data remains challenging. In response, we propose a novel self-supervised graph collaborative filtering model for urban region embedding called EUPAS. Specifically, region heterogeneous graphs containing human mobility data, point of interests (POIs) information, and geographic neighborhood details for each region are fed into the model, which generates region embeddings that preserve intra-region and inter-region dependencies through GCNs and multi-head attention. Meanwhile, we introduce spatial perturbation augmentation to generate positive samples that are semantically similar and spatially close to the anchor, preparing for subsequent contrastive learning. Furthermore, adversarial training is employed to construct an effective pretext task by generating strong positive pairs and mining hard negative pairs for the region embeddings. Finally, we jointly optimize supervised and self-supervised learning to encourage the model to capture the high-level semantics of region embeddings while ignoring the noisy and unimportant details. Extensive experiments on real-world datasets demonstrate the superiority of our model over state-of-the-art methods.
Distillation Enhanced Time Series Forecasting Network with Momentum Contrastive Learning
Jan 31, 2024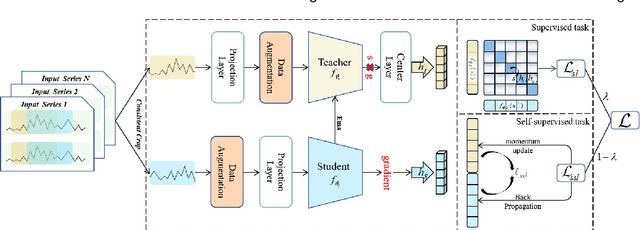

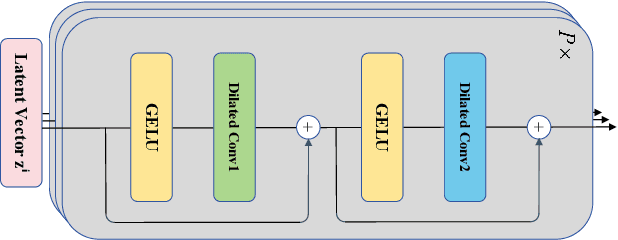
Contrastive representation learning is crucial in time series analysis as it alleviates the issue of data noise and incompleteness as well as sparsity of supervision signal. However, existing constrastive learning frameworks usually focus on intral-temporal features, which fails to fully exploit the intricate nature of time series data. To address this issue, we propose DE-TSMCL, an innovative distillation enhanced framework for long sequence time series forecasting. Specifically, we design a learnable data augmentation mechanism which adaptively learns whether to mask a timestamp to obtain optimized sub-sequences. Then, we propose a contrastive learning task with momentum update to explore inter-sample and intra-temporal correlations of time series to learn the underlying structure feature on the unlabeled time series. Meanwhile, we design a supervised task to learn more robust representations and facilitate the contrastive learning process. Finally, we jointly optimize the above two tasks. By developing model loss from multiple tasks, we can learn effective representations for downstream forecasting task. Extensive experiments, in comparison with state-of-the-arts, well demonstrate the effectiveness of DE-TSMCL, where the maximum improvement can reach to 27.3%.
MEAOD: Model Extraction Attack against Object Detectors
Dec 22, 2023The widespread use of deep learning technology across various industries has made deep neural network models highly valuable and, as a result, attractive targets for potential attackers. Model extraction attacks, particularly query-based model extraction attacks, allow attackers to replicate a substitute model with comparable functionality to the victim model and present a significant threat to the confidentiality and security of MLaaS platforms. While many studies have explored threats of model extraction attacks against classification models in recent years, object detection models, which are more frequently used in real-world scenarios, have received less attention. In this paper, we investigate the challenges and feasibility of query-based model extraction attacks against object detection models and propose an effective attack method called MEAOD. It selects samples from the attacker-possessed dataset to construct an efficient query dataset using active learning and enhances the categories with insufficient objects. We additionally improve the extraction effectiveness by updating the annotations of the query dataset. According to our gray-box and black-box scenarios experiments, we achieve an extraction performance of over 70% under the given condition of a 10k query budget.
Sharp Eyes: A Salient Object Detector Working The Same Way as Human Visual Characteristics
Jan 18, 2023



Current methods aggregate multi-level features or introduce edge and skeleton to get more refined saliency maps. However, little attention is paid to how to obtain the complete salient object in cluttered background, where the targets are usually similar in color and texture to the background. To handle this complex scene, we propose a sharp eyes network (SENet) that first seperates the object from scene, and then finely segments it, which is in line with human visual characteristics, i.e., to look first and then focus. Different from previous methods which directly integrate edge or skeleton to supplement the defects of objects, the proposed method aims to utilize the expanded objects to guide the network obtain complete prediction. Specifically, SENet mainly consists of target separation (TS) brach and object segmentation (OS) branch trained by minimizing a new hierarchical difference aware (HDA) loss. In the TS branch, we construct a fractal structure to produce saliency features with expanded boundary via the supervision of expanded ground truth, which can enlarge the detail difference between foreground and background. In the OS branch, we first aggregate multi-level features to adaptively select complementary components, and then feed the saliency features with expanded boundary into aggregated features to guide the network obtain complete prediction. Moreover, we propose the HDA loss to further improve the structural integrity and local details of the salient objects, which assigns weight to each pixel according to its distance from the boundary hierarchically. Hard pixels with similar appearance in border region will be given more attention hierarchically to emphasize their importance in completeness prediction. Comprehensive experimental results on five datasets demonstrate that the proposed approach outperforms the state-of-the-art methods both quantitatively and qualitatively.