 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative-First Neural Audio Autoencoder
Feb 17, 2026Neural autoencoders underpin generative models. Practical, large-scale use of neural autoencoders for generative modeling necessitates fast encoding, low latent rates, and a single model across representations. Existing approaches are reconstruction-first: they incur high latent rates, slow encoding, and separate architectures for discrete vs. continuous latents and for different audio channel formats, hindering workflows from preprocessing to inference conditioning. We introduce a generative-first architecture for audio autoencoding that increases temporal downsampling from 2048x to 3360x and supports continuous and discrete representations and common audio channel formats in one model. By balancing compression, quality, and speed, it delivers 10x faster encoding, 1.6x lower rates, and eliminates channel-format-specific variants while maintaining competitive reconstruction quality. This enables applications previously constrained by processing costs: a 60-second mono signal compresses to 788 tokens, making generative modeling more tractable.
Stemphonic: All-at-once Flexible Multi-stem Music Generation
Feb 10, 2026Music stem generation, the task of producing musically-synchronized and isolated instrument audio clips, offers the potential of greater user control and better alignment with musician workflows compared to conventional text-to-music models. Existing stem generation approaches, however, either rely on fixed architectures that output a predefined set of stems in parallel, or generate only one stem at a time, resulting in slow inference despite flexibility in stem combination. We propose Stemphonic, a diffusion-/flow-based framework that overcomes this trade-off and generates a variable set of synchronized stems in one inference pass. During training, we treat each stem as a batch element, group synchronized stems in a batch, and apply a shared noise latent to each group. At inference-time, we use a shared initial noise latent and stem-specific text inputs to generate synchronized multi-stem outputs in one pass. We further expand our approach to enable one-pass conditional multi-stem generation and stem-wise activity controls to empower users to iteratively generate and orchestrate the temporal layering of a mix. We benchmark our results on multiple open-source stem evaluation sets and show that Stemphonic produces higher-quality outputs while accelerating the full mix generation process by 25 to 50%. Demos at: https://stemphonic-demo.vercel.app.
A Review on Score-based Generative Models for Audio Applications
Jun 10, 2025Diffusion models have emerged as powerful deep generative techniques, producing high-quality and diverse samples in applications in various domains including audio. These models have many different design choices suitable for different applications, however, existing reviews lack in-depth discussions of these design choices. The audio diffusion model literature also lacks principled guidance for the implementation of these design choices and their comparisons for different applications. This survey provides a comprehensive review of diffusion model design with an emphasis on design principles for quality improvement and conditioning for audio applications. We adopt the score modeling perspective as a unifying framework that accommodates various interpretations, including recent approaches like flow matching. We systematically examine the training and sampling procedures of diffusion models, and audio applications through different conditioning mechanisms. To address the lack of audio diffusion model codebases and to promote reproducible research and rapid prototyping, we introduce an open-source codebase at https://github.com/gzhu06/AudioDiffuser that implements our reviewed framework for various audio applications. We demonstrate its capabilities through three case studies: audio generation, speech enhancement, and text-to-speech synthesis, with benchmark evaluations on standard datasets.
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025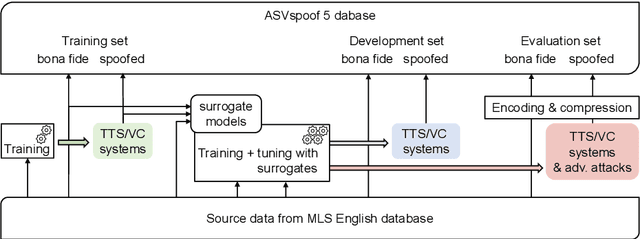

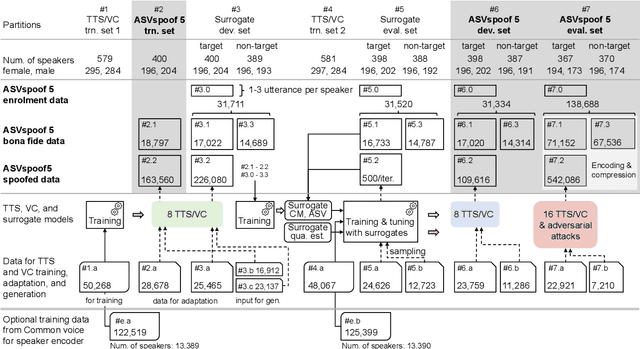
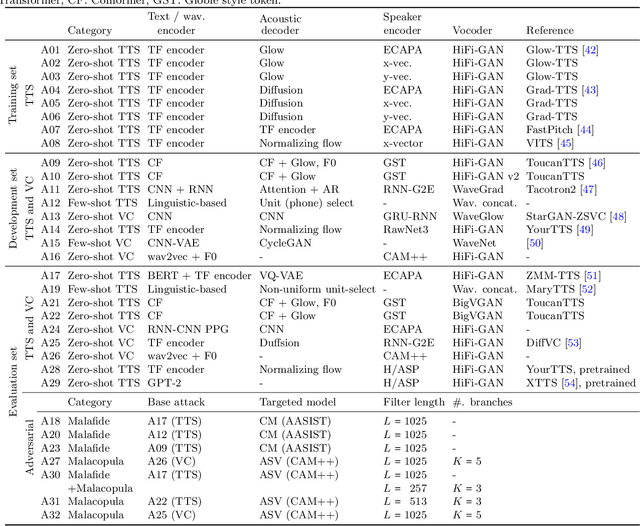
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
Bridging the Gap: Aligning Text-to-Image Diffusion Models with Specific Feedback
Nov 28, 2024Learning from feedback has been shown to enhance the alignment between text prompts and images in text-to-image diffusion models. However, due to the lack of focus in feedback content, especially regarding the object type and quantity, these techniques struggle to accurately match text and images when faced with specified prompts. To address this issue, we propose an efficient fine-turning method with specific reward objectives, including three stages. First, generated images from diffusion model are detected to obtain the object categories and quantities. Meanwhile, the confidence of category and quantity can be derived from the detection results and given prompts. Next, we define a novel matching score, based on above confidence, to measure text-image alignment. It can guide the model for feedback learning in the form of a reward function. Finally, we fine-tune the diffusion model by backpropagation the reward function gradients to generate semantically related images. Different from previous feedbacks that focus more on overall matching, we place more emphasis on the accuracy of entity categories and quantities. Besides, we construct a text-to-image dataset for studying the compositional generation, including 1.7 K pairs of text-image with diverse combinations of entities and quantities. Experimental results on this benchmark show that our model outperforms other SOTA methods in both alignment and fidelity. In addition, our model can also serve as a metric for evaluating text-image alignment in other models. All code and dataset are available at https://github.com/kingniu0329/Visions.
Presto! Distilling Steps and Layers for Accelerating Music Generation
Oct 07, 2024



Despite advances in diffusion-based text-to-music (TTM) methods, efficient, high-quality generation remains a challenge. We introduce Presto!, an approach to inference acceleration for score-based diffusion transformers via reducing both sampling steps and cost per step. To reduce steps, we develop a new score-based distribution matching distillation (DMD) method for the EDM-family of diffusion models, the first GAN-based distillation method for TTM. To reduce the cost per step, we develop a simple, but powerful improvement to a recent layer distillation method that improves learning via better preserving hidden state variance. Finally, we combine our step and layer distillation methods together for a dual-faceted approach. We evaluate our step and layer distillation methods independently and show each yield best-in-class performance. Our combined distillation method can generate high-quality outputs with improved diversity, accelerating our base model by 10-18x (230/435ms latency for 32 second mono/stereo 44.1kHz, 15x faster than comparable SOTA) -- the fastest high-quality TTM to our knowledge. Sound examples can be found at https://presto-music.github.io/web/.
Style-Talker: Finetuning Audio Language Model and Style-Based Text-to-Speech Model for Fast Spoken Dialogue Generation
Aug 13, 2024



The rapid advancement of large language models (LLMs) has significantly propelled the development of text-based chatbots, demonstrating their capability to engage in coherent and contextually relevant dialogues. However, extending these advancements to enable end-to-end speech-to-speech conversation bots remains a formidable challenge, primarily due to the extensive dataset and computational resources required. The conventional approach of cascading automatic speech recognition (ASR), LLM, and text-to-speech (TTS) models in a pipeline, while effective, suffers from unnatural prosody because it lacks direct interactions between the input audio and its transcribed text and the output audio. These systems are also limited by their inherent latency from the ASR process for real-time applications. This paper introduces Style-Talker, an innovative framework that fine-tunes an audio LLM alongside a style-based TTS model for fast spoken dialog generation. Style-Talker takes user input audio and uses transcribed chat history and speech styles to generate both the speaking style and text for the response. Subsequently, the TTS model synthesizes the speech, which is then played back to the user. While the response speech is being played, the input speech undergoes ASR processing to extract the transcription and speaking style, serving as the context for the ensuing dialogue turn. This novel pipeline accelerates the traditional cascade ASR-LLM-TTS systems while integrating rich paralinguistic information from input speech. Our experimental results show that Style-Talker significantly outperforms the conventional cascade and speech-to-speech baselines in terms of both dialogue naturalness and coherence while being more than 50% faster.
MusicHiFi: Fast High-Fidelity Stereo Vocoding
Mar 20, 2024



Diffusion-based audio and music generation models commonly generate music by constructing an image representation of audio (e.g., a mel-spectrogram) and then converting it to audio using a phase reconstruction model or vocoder. Typical vocoders, however, produce monophonic audio at lower resolutions (e.g., 16-24 kHz), which limits their effectiveness. We propose MusicHiFi -- an efficient high-fidelity stereophonic vocoder. Our method employs a cascade of three generative adversarial networks (GANs) that convert low-resolution mel-spectrograms to audio, upsamples to high-resolution audio via bandwidth expansion, and upmixes to stereophonic audio. Compared to previous work, we propose 1) a unified GAN-based generator and discriminator architecture and training procedure for each stage of our cascade, 2) a new fast, near downsampling-compatible bandwidth extension module, and 3) a new fast downmix-compatible mono-to-stereo upmixer that ensures the preservation of monophonic content in the output. We evaluate our approach using both objective and subjective listening tests and find our approach yields comparable or better audio quality, better spatialization control, and significantly faster inference speed compared to past work. Sound examples are at https://MusicHiFi.github.io/web/.
Cacophony: An Improved Contrastive Audio-Text Model
Feb 10, 2024
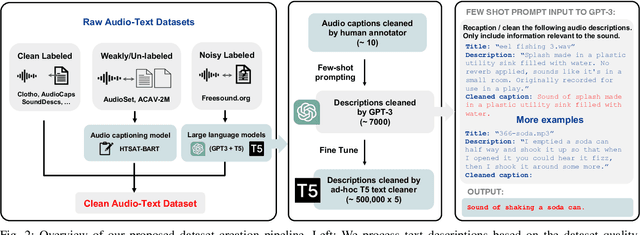
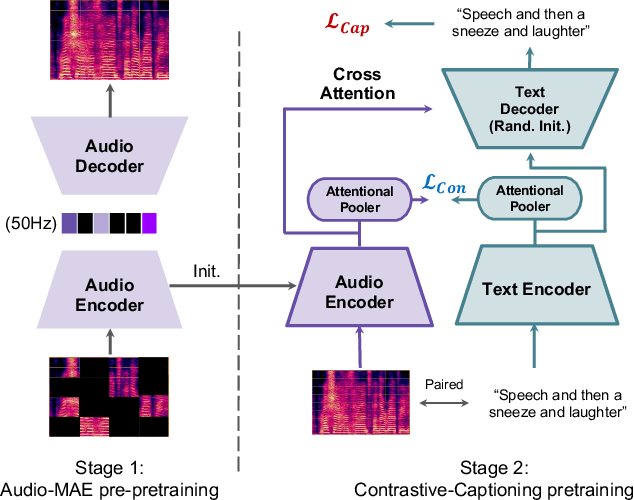
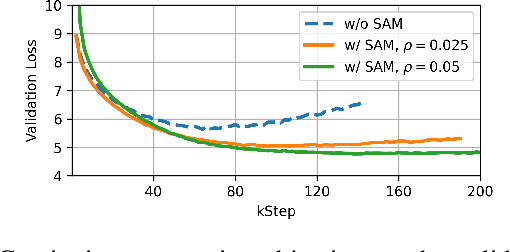
Despite recent improvements in audio-text modeling, audio-text contrastive models still lag behind their image-text counterparts in scale and performance. We propose a method to improve both the scale and the training of audio-text contrastive models. Specifically, we craft a large-scale audio-text dataset consisting of over 13,000 hours of text-labeled audio, aided by large language model (LLM) processing and audio captioning. Further, we employ an masked autoencoder (MAE) pre-pretraining phase with random patch dropout, which allows us to both scale unlabeled audio datasets and train efficiently with variable length audio. After MAE pre-pretraining of our audio encoder, we train a contrastive model with an auxiliary captioning objective. Our final model, which we name Cacophony, achieves state-of-the-art performance on audio-text retrieval tasks, and exhibits competitive results on other downstream tasks such as zero-shot classification.
EDMSound: Spectrogram Based Diffusion Models for Efficient and High-Quality Audio Synthesis
Nov 18, 2023



Audio diffusion models can synthesize a wide variety of sounds. Existing models often operate on the latent domain with cascaded phase recovery modules to reconstruct waveform. This poses challenges when generating high-fidelity audio. In this paper, we propose EDMSound, a diffusion-based generative model in spectrogram domain under the framework of elucidated diffusion models (EDM). Combining with efficient deterministic sampler, we achieved similar Fr\'echet audio distance (FAD) score as top-ranked baseline with only 10 steps and reached state-of-the-art performance with 50 steps on the DCASE2023 foley sound generation benchmark. We also revealed a potential concern regarding diffusion based audio generation models that they tend to generate samples with high perceptual similarity to the data from training data. Project page: https://agentcooper2002.github.io/EDMSound/