 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation
Mar 11, 2026Generating music that temporally aligns with video events is challenging for existing text-to-music models, which lack fine-grained temporal control. We introduce V2M-Zero, a zero-pair video-to-music generation approach that outputs time-aligned music for video. Our method is motivated by a key observation: temporal synchronization requires matching when and how much change occurs, not what changes. While musical and visual events differ semantically, they exhibit shared temporal structure that can be captured independently within each modality. We capture this structure through event curves computed from intra-modal similarity using pretrained music and video encoders. By measuring temporal change within each modality independently, these curves provide comparable representations across modalities. This enables a simple training strategy: fine-tune a text-to-music model on music-event curves, then substitute video-event curves at inference without cross-modal training or paired data. Across OES-Pub, MovieGenBench-Music, and AIST++, V2M-Zero achieves substantial gains over paired-data baselines: 5-21% higher audio quality, 13-15% better semantic alignment, 21-52% improved temporal synchronization, and 28% higher beat alignment on dance videos. We find similar results via a large crowd-source subjective listening test. Overall, our results validate that temporal alignment through within-modality features, rather than paired cross-modal supervision, is effective for video-to-music generation. Results are available at https://genjib.github.io/v2m_zero/
A Generative-First Neural Audio Autoencoder
Feb 17, 2026Neural autoencoders underpin generative models. Practical, large-scale use of neural autoencoders for generative modeling necessitates fast encoding, low latent rates, and a single model across representations. Existing approaches are reconstruction-first: they incur high latent rates, slow encoding, and separate architectures for discrete vs. continuous latents and for different audio channel formats, hindering workflows from preprocessing to inference conditioning. We introduce a generative-first architecture for audio autoencoding that increases temporal downsampling from 2048x to 3360x and supports continuous and discrete representations and common audio channel formats in one model. By balancing compression, quality, and speed, it delivers 10x faster encoding, 1.6x lower rates, and eliminates channel-format-specific variants while maintaining competitive reconstruction quality. This enables applications previously constrained by processing costs: a 60-second mono signal compresses to 788 tokens, making generative modeling more tractable.
Re-Bottleneck: Latent Re-Structuring for Neural Audio Autoencoders
Jul 10, 2025Neural audio codecs and autoencoders have emerged as versatile models for audio compression, transmission, feature-extraction, and latent-space generation. However, a key limitation is that most are trained to maximize reconstruction fidelity, often neglecting the specific latent structure necessary for optimal performance in diverse downstream applications. We propose a simple, post-hoc framework to address this by modifying the bottleneck of a pre-trained autoencoder. Our method introduces a "Re-Bottleneck", an inner bottleneck trained exclusively through latent space losses to instill user-defined structure. We demonstrate the framework's effectiveness in three experiments. First, we enforce an ordering on latent channels without sacrificing reconstruction quality. Second, we align latents with semantic embeddings, analyzing the impact on downstream diffusion modeling. Third, we introduce equivariance, ensuring that a filtering operation on the input waveform directly corresponds to a specific transformation in the latent space. Ultimately, our Re-Bottleneck framework offers a flexible and efficient way to tailor representations of neural audio models, enabling them to seamlessly meet the varied demands of different applications with minimal additional training.
DRAGON: Distributional Rewards Optimize Diffusion Generative Models
Apr 21, 2025We present Distributional RewArds for Generative OptimizatioN (DRAGON), a versatile framework for fine-tuning media generation models towards a desired outcome. Compared with traditional reinforcement learning with human feedback (RLHF) or pairwise preference approaches such as direct preference optimization (DPO), DRAGON is more flexible. It can optimize reward functions that evaluate either individual examples or distributions of them, making it compatible with a broad spectrum of instance-wise, instance-to-distribution, and distribution-to-distribution rewards. Leveraging this versatility, we construct novel reward functions by selecting an encoder and a set of reference examples to create an exemplar distribution. When cross-modality encoders such as CLAP are used, the reference examples may be of a different modality (e.g., text versus audio). Then, DRAGON gathers online and on-policy generations, scores them to construct a positive demonstration set and a negative set, and leverages the contrast between the two sets to maximize the reward. For evaluation, we fine-tune an audio-domain text-to-music diffusion model with 20 different reward functions, including a custom music aesthetics model, CLAP score, Vendi diversity, and Frechet audio distance (FAD). We further compare instance-wise (per-song) and full-dataset FAD settings while ablating multiple FAD encoders and reference sets. Over all 20 target rewards, DRAGON achieves an 81.45% average win rate. Moreover, reward functions based on exemplar sets indeed enhance generations and are comparable to model-based rewards. With an appropriate exemplar set, DRAGON achieves a 60.95% human-voted music quality win rate without training on human preference annotations. As such, DRAGON exhibits a new approach to designing and optimizing reward functions for improving human-perceived quality. Sound examples at https://ml-dragon.github.io/web.
REGEN: Learning Compact Video Embedding with (Re-)Generative Decoder
Mar 11, 2025
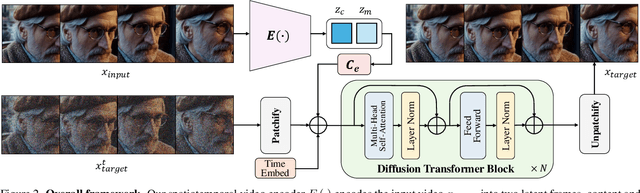

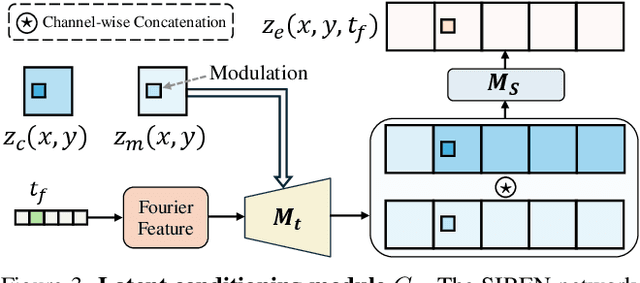
We present a novel perspective on learning video embedders for generative modeling: rather than requiring an exact reproduction of an input video, an effective embedder should focus on synthesizing visually plausible reconstructions. This relaxed criterion enables substantial improvements in compression ratios without compromising the quality of downstream generative models. Specifically, we propose replacing the conventional encoder-decoder video embedder with an encoder-generator framework that employs a diffusion transformer (DiT) to synthesize missing details from a compact latent space. Therein, we develop a dedicated latent conditioning module to condition the DiT decoder on the encoded video latent embedding. Our experiments demonstrate that our approach enables superior encoding-decoding performance compared to state-of-the-art methods, particularly as the compression ratio increases. To demonstrate the efficacy of our approach, we report results from our video embedders achieving a temporal compression ratio of up to 32x (8x higher than leading video embedders) and validate the robustness of this ultra-compact latent space for text-to-video generation, providing a significant efficiency boost in latent diffusion model training and inference.
Presto! Distilling Steps and Layers for Accelerating Music Generation
Oct 07, 2024



Despite advances in diffusion-based text-to-music (TTM) methods, efficient, high-quality generation remains a challenge. We introduce Presto!, an approach to inference acceleration for score-based diffusion transformers via reducing both sampling steps and cost per step. To reduce steps, we develop a new score-based distribution matching distillation (DMD) method for the EDM-family of diffusion models, the first GAN-based distillation method for TTM. To reduce the cost per step, we develop a simple, but powerful improvement to a recent layer distillation method that improves learning via better preserving hidden state variance. Finally, we combine our step and layer distillation methods together for a dual-faceted approach. We evaluate our step and layer distillation methods independently and show each yield best-in-class performance. Our combined distillation method can generate high-quality outputs with improved diversity, accelerating our base model by 10-18x (230/435ms latency for 32 second mono/stereo 44.1kHz, 15x faster than comparable SOTA) -- the fastest high-quality TTM to our knowledge. Sound examples can be found at https://presto-music.github.io/web/.
Scaling Up Adaptive Filter Optimizers
Mar 01, 2024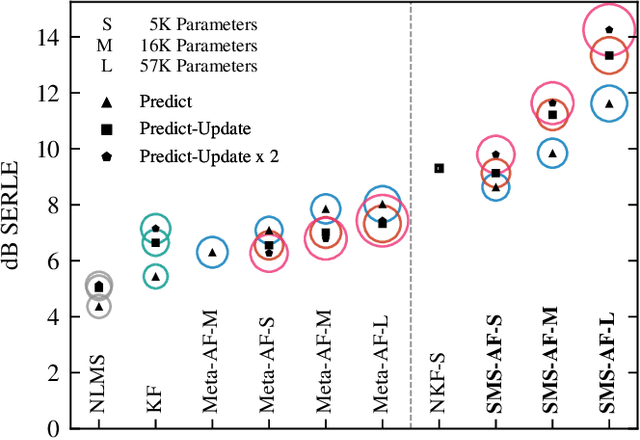
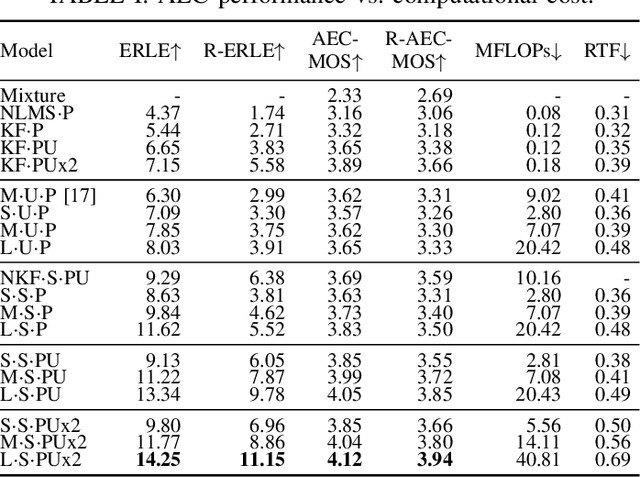
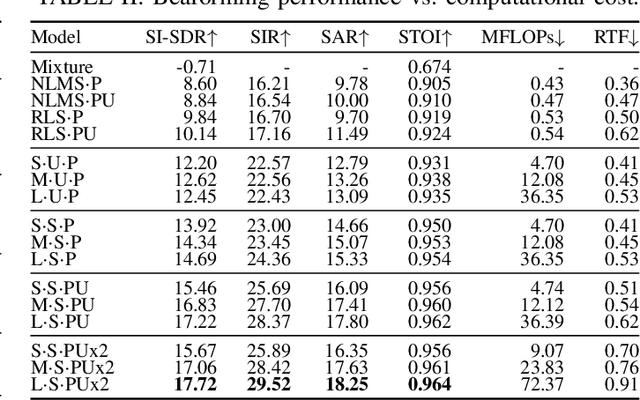
We introduce a new online adaptive filtering method called supervised multi-step adaptive filters (SMS-AF). Our method uses neural networks to control or optimize linear multi-delay or multi-channel frequency-domain filters and can flexibly scale-up performance at the cost of increased compute -- a property rarely addressed in the AF literature, but critical for many applications. To do so, we extend recent work with a set of improvements including feature pruning, a supervised loss, and multiple optimization steps per time-frame. These improvements work in a cohesive manner to unlock scaling. Furthermore, we show how our method relates to Kalman filtering and meta-adaptive filtering, making it seamlessly applicable to a diverse set of AF tasks. We evaluate our method on acoustic echo cancellation (AEC) and multi-channel speech enhancement tasks and compare against several baselines on standard synthetic and real-world datasets. Results show our method performance scales with inference cost and model capacity, yields multi-dB performance gains for both tasks, and is real-time capable on a single CPU core.
Meta-AF Echo Cancellation for Improved Keyword Spotting
Dec 17, 2023Adaptive filters (AFs) are vital for enhancing the performance of downstream tasks, such as speech recognition, sound event detection, and keyword spotting. However, traditional AF design prioritizes isolated signal-level objectives, often overlooking downstream task performance. This can lead to suboptimal performance. Recent research has leveraged meta-learning to automatically learn AF update rules from data, alleviating the need for manual tuning when using simple signal-level objectives. This paper improves the Meta-AF framework by expanding it to support end-to-end training for arbitrary downstream tasks. We focus on classification tasks, where we introduce a novel training methodology that harnesses self-supervision and classifier feedback. We evaluate our approach on the combined task of acoustic echo cancellation and keyword spotting. Our findings demonstrate consistent performance improvements with both pre-trained and joint-trained keyword spotting models across synthetic and real playback. Notably, these improvements come without requiring additional tuning, increased inference-time complexity, or reliance on oracle signal-level training data.
Meta-Learning for Adaptive Filters with Higher-Order Frequency Dependencies
Sep 20, 2022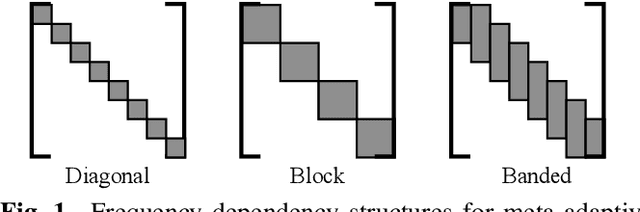
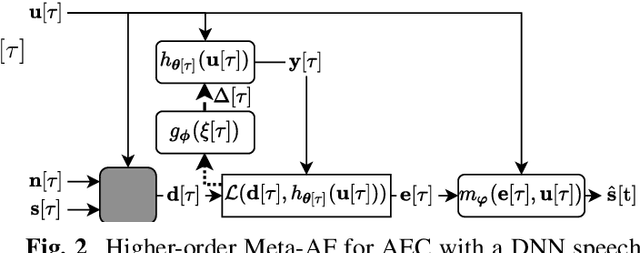
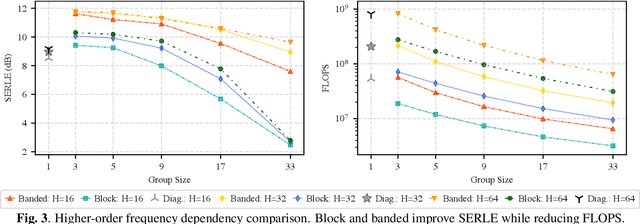
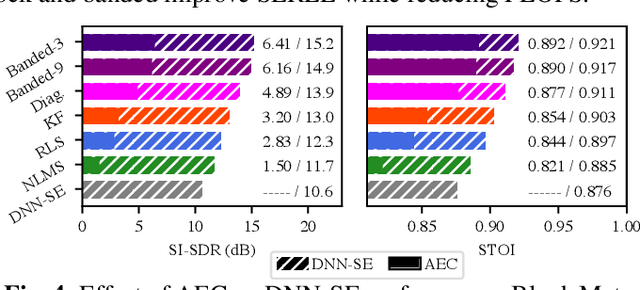
Adaptive filters are applicable to many signal processing tasks including acoustic echo cancellation, beamforming, and more. Adaptive filters are typically controlled using algorithms such as least-mean squares(LMS), recursive least squares(RLS), or Kalman filter updates. Such models are often applied in the frequency domain, assume frequency independent processing, and do not exploit higher-order frequency dependencies, for simplicity. Recent work on meta-adaptive filters, however, has shown that we can control filter adaptation using neural networks without manual derivation, motivating new work to exploit such information. In this work, we present higher-order meta-adaptive filters, a key improvement to meta-adaptive filters that incorporates higher-order frequency dependencies. We demonstrate our approach on acoustic echo cancellation and develop a family of filters that yield multi-dB improvements over competitive baselines, and are at least an order-of-magnitude less complex. Moreover, we show our improvements hold with or without a downstream speech enhancer.
Meta-AF: Meta-Learning for Adaptive Filters
Apr 25, 2022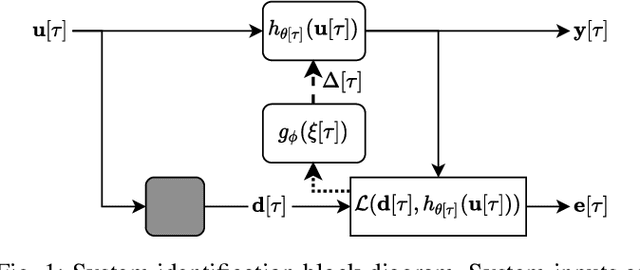
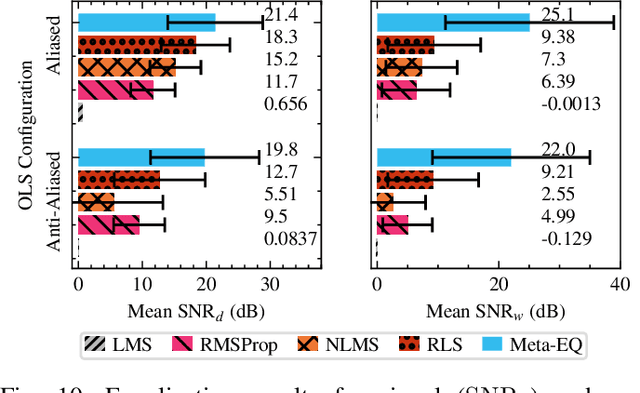
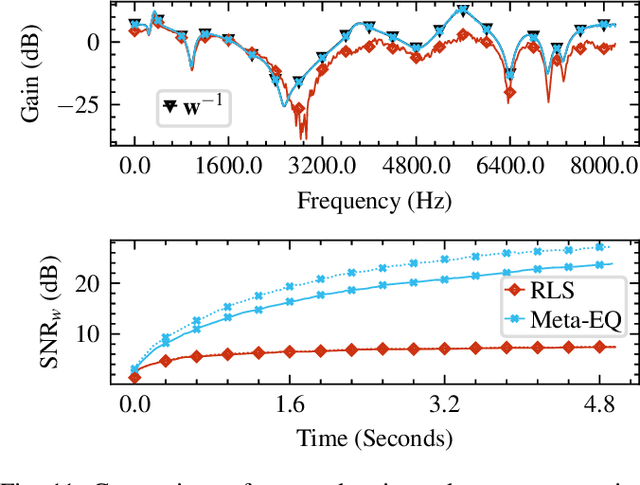
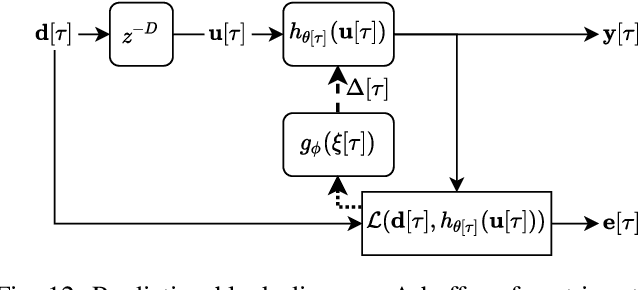
Adaptive filtering algorithms are pervasive throughout modern society and have had a significant impact on a wide variety of domains including audio processing, telecommunications, biomedical sensing, astropyhysics and cosmology, seismology, and many more. Adaptive filters typically operate via specialized online, iterative optimization methods such as least-mean squares or recursive least squares and aim to process signals in unknown or nonstationary environments. Such algorithms, however, can be slow and laborious to develop, require domain expertise to create, and necessitate mathematical insight for improvement. In this work, we seek to go beyond the limits of human-derived adaptive filter algorithms and present a comprehensive framework for learning online, adaptive signal processing algorithms or update rules directly from data. To do so, we frame the development of adaptive filters as a meta-learning problem in the context of deep learning and use a form of self-supervision to learn online iterative update rules for adaptive filters. To demonstrate our approach, we focus on audio applications and systematically develop meta-learned adaptive filters for five canonical audio problems including system identification, acoustic echo cancellation, blind equalization, multi-channel dereverberation, and beamforming. For each application, we compare against common baselines and/or current state-of-the-art methods and show we can learn high-performing adaptive filters that operate in real-time and, in most cases, significantly out perform all past specially developed methods for each task using a single general-purpose configuration of our method.