 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenDial: Continuous Attribute Control in Text-to-Video via Spatiotemporal Token Offsets
Mar 29, 2026We present TokenDial, a framework for continuous, slider-style attribute control in pretrained text-to-video generation models. While modern generators produce strong holistic videos, they offer limited control over how much an attribute changes (e.g., effect intensity or motion magnitude) without drifting identity, background, or temporal coherence. TokenDial is built on the observation: additive offsets in the intermediate spatiotemporal visual patch-token space form a semantic control direction, where adjusting the offset magnitude yields coherent, predictable edits for both appearance and motion dynamics. We learn attribute-specific token offsets without retraining the backbone, using pretrained understanding signals: semantic direction matching for appearance and motion-magnitude scaling for motion. We demonstrate TokenDial's effectiveness on diverse attributes and prompts, achieving stronger controllability and higher-quality edits than state-of-the-art baselines, supported by extensive quantitative evaluation and human studies.
TRACE: Object Motion Editing in Videos with First-Frame Trajectory Guidance
Mar 26, 2026We study object motion path editing in videos, where the goal is to alter a target object's trajectory while preserving the original scene content. Unlike prior video editing methods that primarily manipulate appearance or rely on point-track-based trajectory control, which is often challenging for users to provide during inference, especially in videos with camera motion, we offer a practical, easy-to-use approach to controllable object-centric motion editing. We present Trace, a framework that enables users to design the desired trajectory in a single anchor frame and then synthesizes a temporally consistent edited video. Our approach addresses this task with a two-stage pipeline: a cross-view motion transformation module that maps first-frame path design to frame-aligned box trajectories under camera motion, and a motion-conditioned video re-synthesis module that follows these trajectories to regenerate the object while preserving the remaining content of the input video. Experiments on diverse real-world videos show that our method produces more coherent, realistic, and controllable motion edits than recent image-to-video and video-to-video methods.
V2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation
Mar 11, 2026Generating music that temporally aligns with video events is challenging for existing text-to-music models, which lack fine-grained temporal control. We introduce V2M-Zero, a zero-pair video-to-music generation approach that outputs time-aligned music for video. Our method is motivated by a key observation: temporal synchronization requires matching when and how much change occurs, not what changes. While musical and visual events differ semantically, they exhibit shared temporal structure that can be captured independently within each modality. We capture this structure through event curves computed from intra-modal similarity using pretrained music and video encoders. By measuring temporal change within each modality independently, these curves provide comparable representations across modalities. This enables a simple training strategy: fine-tune a text-to-music model on music-event curves, then substitute video-event curves at inference without cross-modal training or paired data. Across OES-Pub, MovieGenBench-Music, and AIST++, V2M-Zero achieves substantial gains over paired-data baselines: 5-21% higher audio quality, 13-15% better semantic alignment, 21-52% improved temporal synchronization, and 28% higher beat alignment on dance videos. We find similar results via a large crowd-source subjective listening test. Overall, our results validate that temporal alignment through within-modality features, rather than paired cross-modal supervision, is effective for video-to-music generation. Results are available at https://genjib.github.io/v2m_zero/
DreamLoop: Controllable Cinemagraph Generation from a Single Photograph
Jan 06, 2026Cinemagraphs, which combine static photographs with selective, looping motion, offer unique artistic appeal. Generating them from a single photograph in a controllable manner is particularly challenging. Existing image-animation techniques are restricted to simple, low-frequency motions and operate only in narrow domains with repetitive textures like water and smoke. In contrast, large-scale video diffusion models are not tailored for cinemagraph constraints and lack the specialized data required to generate seamless, controlled loops. We present DreamLoop, a controllable video synthesis framework dedicated to generating cinemagraphs from a single photo without requiring any cinemagraph training data. Our key idea is to adapt a general video diffusion model by training it on two objectives: temporal bridging and motion conditioning. This strategy enables flexible cinemagraph generation. During inference, by using the input image as both the first- and last- frame condition, we enforce a seamless loop. By conditioning on static tracks, we maintain a static background. Finally, by providing a user-specified motion path for a target object, our method provides intuitive control over the animation's trajectory and timing. To our knowledge, DreamLoop is the first method to enable cinemagraph generation for general scenes with flexible and intuitive controls. We demonstrate that our method produces high-quality, complex cinemagraphs that align with user intent, outperforming existing approaches.
REGEN: Learning Compact Video Embedding with (Re-)Generative Decoder
Mar 11, 2025
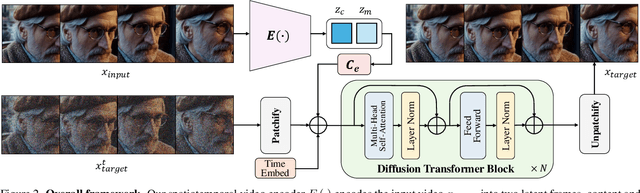

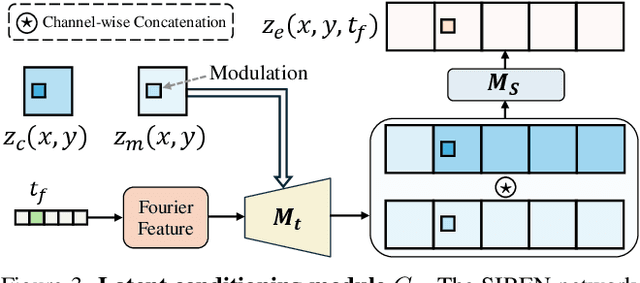
We present a novel perspective on learning video embedders for generative modeling: rather than requiring an exact reproduction of an input video, an effective embedder should focus on synthesizing visually plausible reconstructions. This relaxed criterion enables substantial improvements in compression ratios without compromising the quality of downstream generative models. Specifically, we propose replacing the conventional encoder-decoder video embedder with an encoder-generator framework that employs a diffusion transformer (DiT) to synthesize missing details from a compact latent space. Therein, we develop a dedicated latent conditioning module to condition the DiT decoder on the encoded video latent embedding. Our experiments demonstrate that our approach enables superior encoding-decoding performance compared to state-of-the-art methods, particularly as the compression ratio increases. To demonstrate the efficacy of our approach, we report results from our video embedders achieving a temporal compression ratio of up to 32x (8x higher than leading video embedders) and validate the robustness of this ultra-compact latent space for text-to-video generation, providing a significant efficiency boost in latent diffusion model training and inference.
MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation
Feb 06, 2025



This paper presents a method that allows users to design cinematic video shots in the context of image-to-video generation. Shot design, a critical aspect of filmmaking, involves meticulously planning both camera movements and object motions in a scene. However, enabling intuitive shot design in modern image-to-video generation systems presents two main challenges: first, effectively capturing user intentions on the motion design, where both camera movements and scene-space object motions must be specified jointly; and second, representing motion information that can be effectively utilized by a video diffusion model to synthesize the image animations. To address these challenges, we introduce MotionCanvas, a method that integrates user-driven controls into image-to-video (I2V) generation models, allowing users to control both object and camera motions in a scene-aware manner. By connecting insights from classical computer graphics and contemporary video generation techniques, we demonstrate the ability to achieve 3D-aware motion control in I2V synthesis without requiring costly 3D-related training data. MotionCanvas enables users to intuitively depict scene-space motion intentions, and translates them into spatiotemporal motion-conditioning signals for video diffusion models. We demonstrate the effectiveness of our method on a wide range of real-world image content and shot-design scenarios, highlighting its potential to enhance the creative workflows in digital content creation and adapt to various image and video editing applications.
Progressive Growing of Video Tokenizers for Highly Compressed Latent Spaces
Jan 09, 2025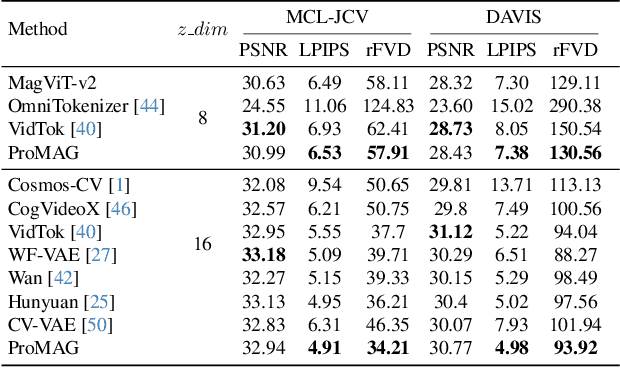

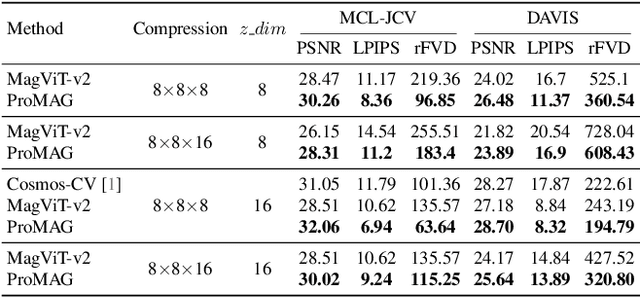

Video tokenizers are essential for latent video diffusion models, converting raw video data into spatiotemporally compressed latent spaces for efficient training. However, extending state-of-the-art video tokenizers to achieve a temporal compression ratio beyond 4x without increasing channel capacity poses significant challenges. In this work, we propose an alternative approach to enhance temporal compression. We find that the reconstruction quality of temporally subsampled videos from a low-compression encoder surpasses that of high-compression encoders applied to original videos. This indicates that high-compression models can leverage representations from lower-compression models. Building on this insight, we develop a bootstrapped high-temporal-compression model that progressively trains high-compression blocks atop well-trained lower-compression models. Our method includes a cross-level feature-mixing module to retain information from the pretrained low-compression model and guide higher-compression blocks to capture the remaining details from the full video sequence. Evaluation of video benchmarks shows that our method significantly improves reconstruction quality while increasing temporal compression compared to direct extensions of existing video tokenizers. Furthermore, the resulting compact latent space effectively trains a video diffusion model for high-quality video generation with a reduced token budget.
On the Content Bias in Fréchet Video Distance
Apr 18, 2024



Fr\'echet Video Distance (FVD), a prominent metric for evaluating video generation models, is known to conflict with human perception occasionally. In this paper, we aim to explore the extent of FVD's bias toward per-frame quality over temporal realism and identify its sources. We first quantify the FVD's sensitivity to the temporal axis by decoupling the frame and motion quality and find that the FVD increases only slightly with large temporal corruption. We then analyze the generated videos and show that via careful sampling from a large set of generated videos that do not contain motions, one can drastically decrease FVD without improving the temporal quality. Both studies suggest FVD's bias towards the quality of individual frames. We further observe that the bias can be attributed to the features extracted from a supervised video classifier trained on the content-biased dataset. We show that FVD with features extracted from the recent large-scale self-supervised video models is less biased toward image quality. Finally, we revisit a few real-world examples to validate our hypothesis.
Synthesizing Artistic Cinemagraphs from Text
Jul 12, 2023We introduce Text2Cinemagraph, a fully automated method for creating cinemagraphs from text descriptions - an especially challenging task when prompts feature imaginary elements and artistic styles, given the complexity of interpreting the semantics and motions of these images. Existing single-image animation methods fall short on artistic inputs, and recent text-based video methods frequently introduce temporal inconsistencies, struggling to keep certain regions static. To address these challenges, we propose an idea of synthesizing image twins from a single text prompt - a pair of an artistic image and its pixel-aligned corresponding natural-looking twin. While the artistic image depicts the style and appearance detailed in our text prompt, the realistic counterpart greatly simplifies layout and motion analysis. Leveraging existing natural image and video datasets, we can accurately segment the realistic image and predict plausible motion given the semantic information. The predicted motion can then be transferred to the artistic image to create the final cinemagraph. Our method outperforms existing approaches in creating cinemagraphs for natural landscapes as well as artistic and other-worldly scenes, as validated by automated metrics and user studies. Finally, we demonstrate two extensions: animating existing paintings and controlling motion directions using text.
GEMS: Scene Expansion using Generative Models of Graphs
Jul 08, 2022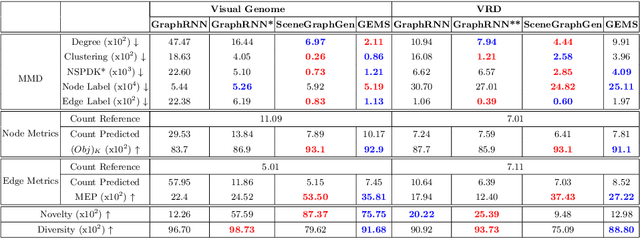
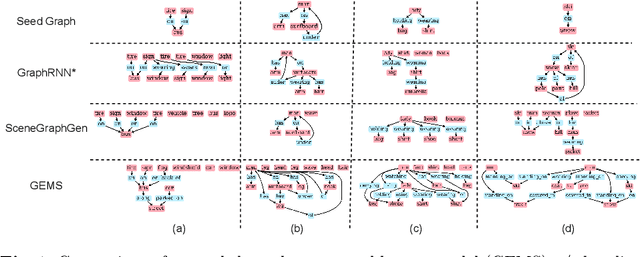
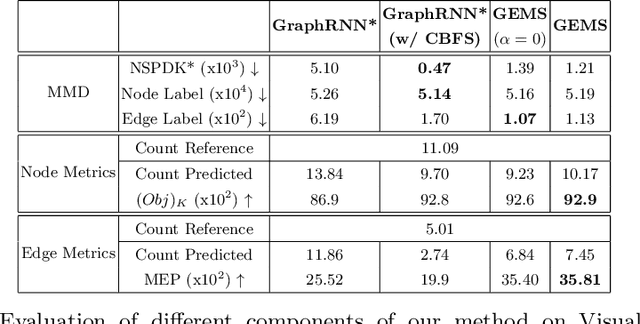
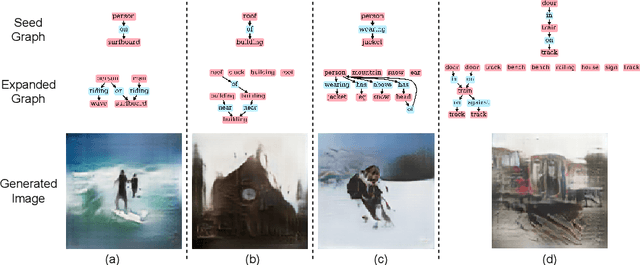
Applications based on image retrieval require editing and associating in intermediate spaces that are representative of the high-level concepts like objects and their relationships rather than dense, pixel-level representations like RGB images or semantic-label maps. We focus on one such representation, scene graphs, and propose a novel scene expansion task where we enrich an input seed graph by adding new nodes (objects) and the corresponding relationships. To this end, we formulate scene graph expansion as a sequential prediction task involving multiple steps of first predicting a new node and then predicting the set of relationships between the newly predicted node and previous nodes in the graph. We propose a sequencing strategy for observed graphs that retains the clustering patterns amongst nodes. In addition, we leverage external knowledge to train our graph generation model, enabling greater generalization of node predictions. Due to the inefficiency of existing maximum mean discrepancy (MMD) based metrics for graph generation problems in evaluating predicted relationships between nodes (objects), we design novel metrics that comprehensively evaluate different aspects of predicted relations. We conduct extensive experiments on Visual Genome and VRD datasets to evaluate the expanded scene graphs using the standard MMD-based metrics and our proposed metrics. We observe that the graphs generated by our method, GEMS, better represent the real distribution of the scene graphs than the baseline methods like GraphRNN.