 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamLoop: Controllable Cinemagraph Generation from a Single Photograph
Jan 06, 2026Cinemagraphs, which combine static photographs with selective, looping motion, offer unique artistic appeal. Generating them from a single photograph in a controllable manner is particularly challenging. Existing image-animation techniques are restricted to simple, low-frequency motions and operate only in narrow domains with repetitive textures like water and smoke. In contrast, large-scale video diffusion models are not tailored for cinemagraph constraints and lack the specialized data required to generate seamless, controlled loops. We present DreamLoop, a controllable video synthesis framework dedicated to generating cinemagraphs from a single photo without requiring any cinemagraph training data. Our key idea is to adapt a general video diffusion model by training it on two objectives: temporal bridging and motion conditioning. This strategy enables flexible cinemagraph generation. During inference, by using the input image as both the first- and last- frame condition, we enforce a seamless loop. By conditioning on static tracks, we maintain a static background. Finally, by providing a user-specified motion path for a target object, our method provides intuitive control over the animation's trajectory and timing. To our knowledge, DreamLoop is the first method to enable cinemagraph generation for general scenes with flexible and intuitive controls. We demonstrate that our method produces high-quality, complex cinemagraphs that align with user intent, outperforming existing approaches.
Diffusion Transformer-to-Mamba Distillation for High-Resolution Image Generation
Jun 23, 2025
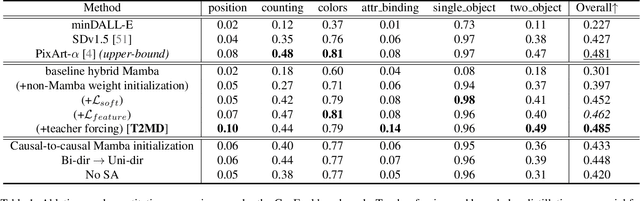
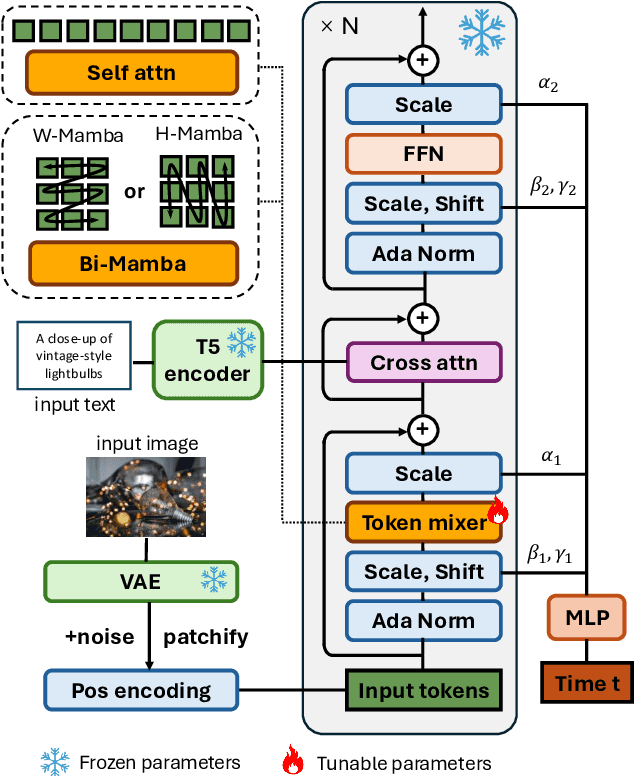
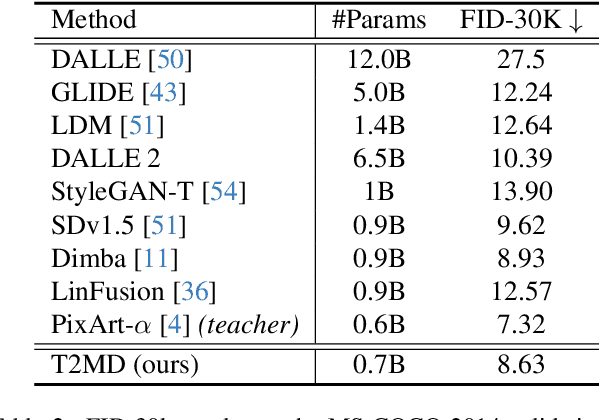
The quadratic computational complexity of self-attention in diffusion transformers (DiT) introduces substantial computational costs in high-resolution image generation. While the linear-complexity Mamba model emerges as a potential alternative, direct Mamba training remains empirically challenging. To address this issue, this paper introduces diffusion transformer-to-mamba distillation (T2MD), forming an efficient training pipeline that facilitates the transition from the self-attention-based transformer to the linear complexity state-space model Mamba. We establish a diffusion self-attention and Mamba hybrid model that simultaneously achieves efficiency and global dependencies. With the proposed layer-level teacher forcing and feature-based knowledge distillation, T2MD alleviates the training difficulty and high cost of a state space model from scratch. Starting from the distilled 512$\times$512 resolution base model, we push the generation towards 2048$\times$2048 images via lightweight adaptation and high-resolution fine-tuning. Experiments demonstrate that our training path leads to low overhead but high-quality text-to-image generation. Importantly, our results also justify the feasibility of using sequential and causal Mamba models for generating non-causal visual output, suggesting the potential for future exploration.
CineVerse: Consistent Keyframe Synthesis for Cinematic Scene Composition
Apr 28, 2025We present CineVerse, a novel framework for the task of cinematic scene composition. Similar to traditional multi-shot generation, our task emphasizes the need for consistency and continuity across frames. However, our task also focuses on addressing challenges inherent to filmmaking, such as multiple characters, complex interactions, and visual cinematic effects. In order to learn to generate such content, we first create the CineVerse dataset. We use this dataset to train our proposed two-stage approach. First, we prompt a large language model (LLM) with task-specific instructions to take in a high-level scene description and generate a detailed plan for the overall setting and characters, as well as the individual shots. Then, we fine-tune a text-to-image generation model to synthesize high-quality visual keyframes. Experimental results demonstrate that CineVerse yields promising improvements in generating visually coherent and contextually rich movie scenes, paving the way for further exploration in cinematic video synthesis.
REGEN: Learning Compact Video Embedding with (Re-)Generative Decoder
Mar 11, 2025
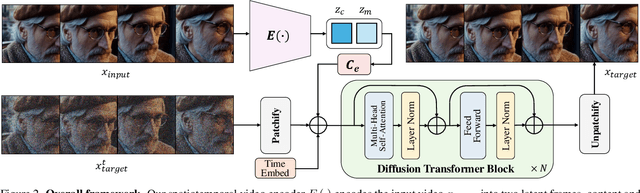

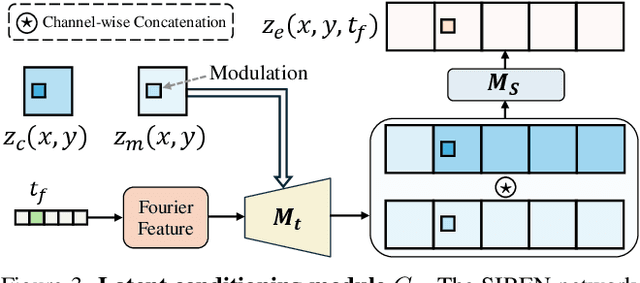
We present a novel perspective on learning video embedders for generative modeling: rather than requiring an exact reproduction of an input video, an effective embedder should focus on synthesizing visually plausible reconstructions. This relaxed criterion enables substantial improvements in compression ratios without compromising the quality of downstream generative models. Specifically, we propose replacing the conventional encoder-decoder video embedder with an encoder-generator framework that employs a diffusion transformer (DiT) to synthesize missing details from a compact latent space. Therein, we develop a dedicated latent conditioning module to condition the DiT decoder on the encoded video latent embedding. Our experiments demonstrate that our approach enables superior encoding-decoding performance compared to state-of-the-art methods, particularly as the compression ratio increases. To demonstrate the efficacy of our approach, we report results from our video embedders achieving a temporal compression ratio of up to 32x (8x higher than leading video embedders) and validate the robustness of this ultra-compact latent space for text-to-video generation, providing a significant efficiency boost in latent diffusion model training and inference.
MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation
Feb 06, 2025



This paper presents a method that allows users to design cinematic video shots in the context of image-to-video generation. Shot design, a critical aspect of filmmaking, involves meticulously planning both camera movements and object motions in a scene. However, enabling intuitive shot design in modern image-to-video generation systems presents two main challenges: first, effectively capturing user intentions on the motion design, where both camera movements and scene-space object motions must be specified jointly; and second, representing motion information that can be effectively utilized by a video diffusion model to synthesize the image animations. To address these challenges, we introduce MotionCanvas, a method that integrates user-driven controls into image-to-video (I2V) generation models, allowing users to control both object and camera motions in a scene-aware manner. By connecting insights from classical computer graphics and contemporary video generation techniques, we demonstrate the ability to achieve 3D-aware motion control in I2V synthesis without requiring costly 3D-related training data. MotionCanvas enables users to intuitively depict scene-space motion intentions, and translates them into spatiotemporal motion-conditioning signals for video diffusion models. We demonstrate the effectiveness of our method on a wide range of real-world image content and shot-design scenarios, highlighting its potential to enhance the creative workflows in digital content creation and adapt to various image and video editing applications.
Pushing the Boundaries of State Space Models for Image and Video Generation
Feb 03, 2025



While Transformers have become the dominant architecture for visual generation, linear attention models, such as the state-space models (SSM), are increasingly recognized for their efficiency in processing long visual sequences. However, the essential efficiency of these models comes from formulating a limited recurrent state, enforcing causality among tokens that are prone to inconsistent modeling of N-dimensional visual data, leaving questions on their capacity to generate long non-causal sequences. In this paper, we explore the boundary of SSM on image and video generation by building the largest-scale diffusion SSM-Transformer hybrid model to date (5B parameters) based on the sub-quadratic bi-directional Hydra and self-attention, and generate up to 2K images and 360p 8 seconds (16 FPS) videos. Our results demonstrate that the model can produce faithful results aligned with complex text prompts and temporal consistent videos with high dynamics, suggesting the great potential of using SSMs for visual generation tasks.
Progressive Growing of Video Tokenizers for Highly Compressed Latent Spaces
Jan 09, 2025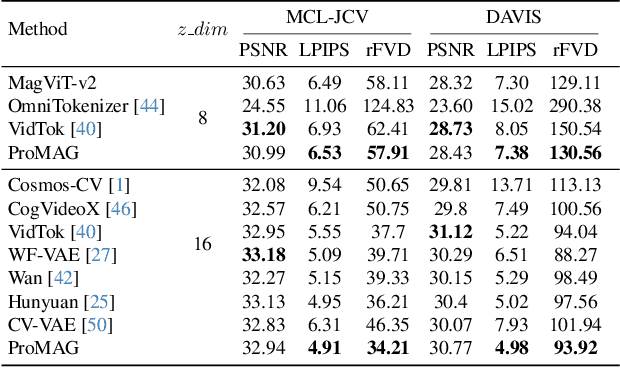

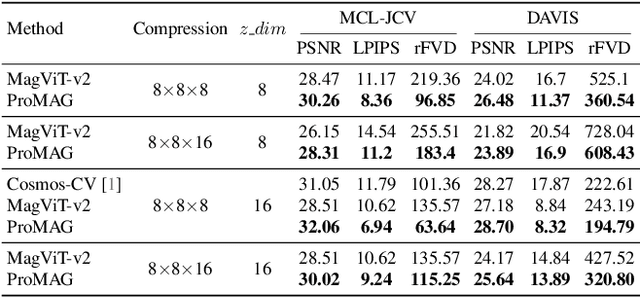

Video tokenizers are essential for latent video diffusion models, converting raw video data into spatiotemporally compressed latent spaces for efficient training. However, extending state-of-the-art video tokenizers to achieve a temporal compression ratio beyond 4x without increasing channel capacity poses significant challenges. In this work, we propose an alternative approach to enhance temporal compression. We find that the reconstruction quality of temporally subsampled videos from a low-compression encoder surpasses that of high-compression encoders applied to original videos. This indicates that high-compression models can leverage representations from lower-compression models. Building on this insight, we develop a bootstrapped high-temporal-compression model that progressively trains high-compression blocks atop well-trained lower-compression models. Our method includes a cross-level feature-mixing module to retain information from the pretrained low-compression model and guide higher-compression blocks to capture the remaining details from the full video sequence. Evaluation of video benchmarks shows that our method significantly improves reconstruction quality while increasing temporal compression compared to direct extensions of existing video tokenizers. Furthermore, the resulting compact latent space effectively trains a video diffusion model for high-quality video generation with a reduced token budget.
Real-Time Textless Dialogue Generation
Jan 08, 2025Recent advancements in large language models (LLMs) have led to significant progress in text-based dialogue systems. These systems can now generate high-quality responses that are accurate and coherent across a wide range of topics and tasks. However, spoken dialogue systems still lag behind in terms of naturalness. They tend to produce robotic interactions, with issues such as slow response times, overly generic or cautious replies, and a lack of natural rhythm and fluid turn-taking. This shortcoming is largely due to the over-reliance on the traditional cascaded design, which involve separate, sequential components, as well as the use of text as an intermediate representation. This paper propose a real-time, textless spoken dialogue generation model (RTTL-DG) that aims to overcome these challenges. Our system enables fluid turn-taking and generates responses with minimal delay by processing streaming spoken conversation directly. Additionally, our model incorporates backchannels, filters, laughter, and other paralinguistic signals, which are often absent in cascaded dialogue systems, to create more natural and human-like interactions. The implementations and generated samples are available in our repository: https://github.com/mailong25/rts2s-dg
GaussianVideo: Efficient Video Representation via Hierarchical Gaussian Splatting
Jan 08, 2025Efficient neural representations for dynamic video scenes are critical for applications ranging from video compression to interactive simulations. Yet, existing methods often face challenges related to high memory usage, lengthy training times, and temporal consistency. To address these issues, we introduce a novel neural video representation that combines 3D Gaussian splatting with continuous camera motion modeling. By leveraging Neural ODEs, our approach learns smooth camera trajectories while maintaining an explicit 3D scene representation through Gaussians. Additionally, we introduce a spatiotemporal hierarchical learning strategy, progressively refining spatial and temporal features to enhance reconstruction quality and accelerate convergence. This memory-efficient approach achieves high-quality rendering at impressive speeds. Experimental results show that our hierarchical learning, combined with robust camera motion modeling, captures complex dynamic scenes with strong temporal consistency, achieving state-of-the-art performance across diverse video datasets in both high- and low-motion scenarios.
TAB: Transformer Attention Bottlenecks enable User Intervention and Debugging in Vision-Language Models
Dec 24, 2024Multi-head self-attention (MHSA) is a key component of Transformers, a widely popular architecture in both language and vision. Multiple heads intuitively enable different parallel processes over the same input. Yet, they also obscure the attribution of each input patch to the output of a model. We propose a novel 1-head Transformer Attention Bottleneck (TAB) layer, inserted after the traditional MHSA architecture, to serve as an attention bottleneck for interpretability and intervention. Unlike standard self-attention, TAB constrains the total attention over all patches to $\in [0, 1]$. That is, when the total attention is 0, no visual information is propagated further into the network and the vision-language model (VLM) would default to a generic, image-independent response. To demonstrate the advantages of TAB, we train VLMs with TAB to perform image difference captioning. Over three datasets, our models perform similarly to baseline VLMs in captioning but the bottleneck is superior in localizing changes and in identifying when no changes occur. TAB is the first architecture to enable users to intervene by editing attention, which often produces expected outputs by VLMs.