 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large-Scale Cross-Domain Sequential Recommendation with Dynamic State Representations
Aug 28, 2025Recently, autoregressive recommendation models (ARMs), such as Meta's HSTU model, have emerged as a major breakthrough over traditional Deep Learning Recommendation Models (DLRMs), exhibiting the highly sought-after scaling law behaviour. However, when applied to multi-domain scenarios, the transformer architecture's attention maps become a computational bottleneck, as they attend to all items across every domain. To tackle this challenge, systems must efficiently balance inter and intra-domain knowledge transfer. In this work, we introduce a novel approach for scalable multi-domain recommendation systems by replacing full inter-domain attention with two innovative mechanisms: 1) Transition-Aware Positional Embeddings (TAPE): We propose novel positional embeddings that account for domain-transition specific information. This allows attention to be focused solely on intra-domain items, effectively reducing the unnecessary computational cost associated with attending to irrelevant domains. 2) Dynamic Domain State Representation (DDSR): We introduce a dynamic state representation for each domain, which is stored and accessed during subsequent token predictions. This enables the efficient transfer of relevant domain information without relying on full attention maps. Our method offers a scalable solution to the challenges posed by large-scale, multi-domain recommendation systems and demonstrates significant improvements in retrieval tasks by separately modelling and combining inter- and intra-domain representations.
Rs4rs: Semantically Find Recent Publications from Top Recommendation System-Related Venues
Sep 11, 2024
Rs4rs is a web application designed to perform semantic search on recent papers from top conferences and journals related to Recommender Systems. Current scholarly search engine tools like Google Scholar, Semantic Scholar, and ResearchGate often yield broad results that fail to target the most relevant high-quality publications. Moreover, manually visiting individual conference and journal websites is a time-consuming process that primarily supports only syntactic searches. Rs4rs addresses these issues by providing a user-friendly platform where researchers can input their topic of interest and receive a list of recent, relevant papers from top Recommender Systems venues. Utilizing semantic search techniques, Rs4rs ensures that the search results are not only precise and relevant but also comprehensive, capturing papers regardless of variations in wording. This tool significantly enhances research efficiency and accuracy, thereby benefitting the research community and public by facilitating access to high-quality, pertinent academic resources in the field of Recommender Systems. Rs4rs is available at https://rs4rs.com.
SPICED: News Similarity Detection Dataset with Multiple Topics and Complexity Levels
Sep 21, 2023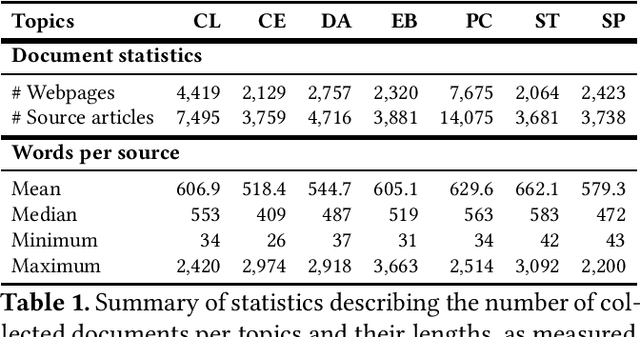
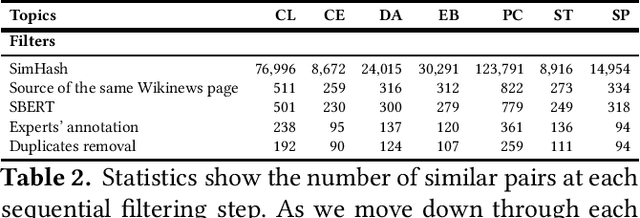
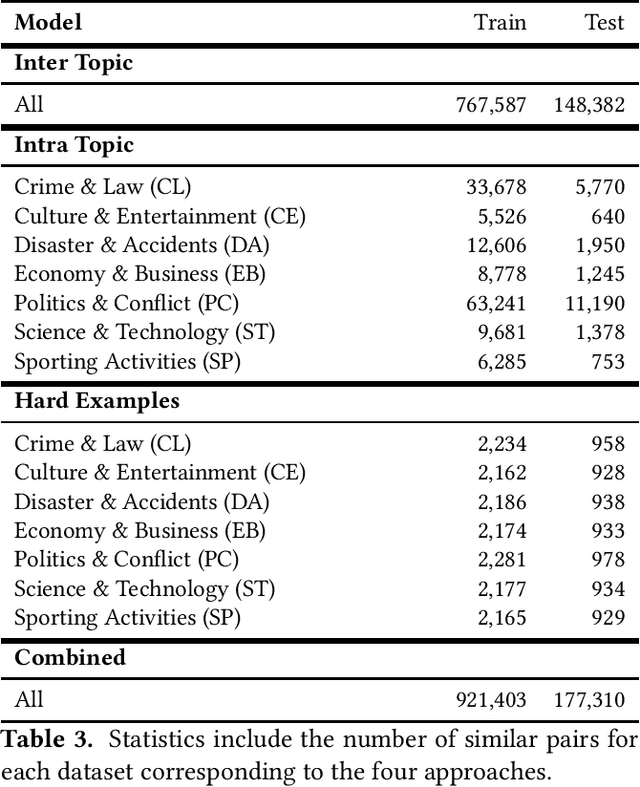
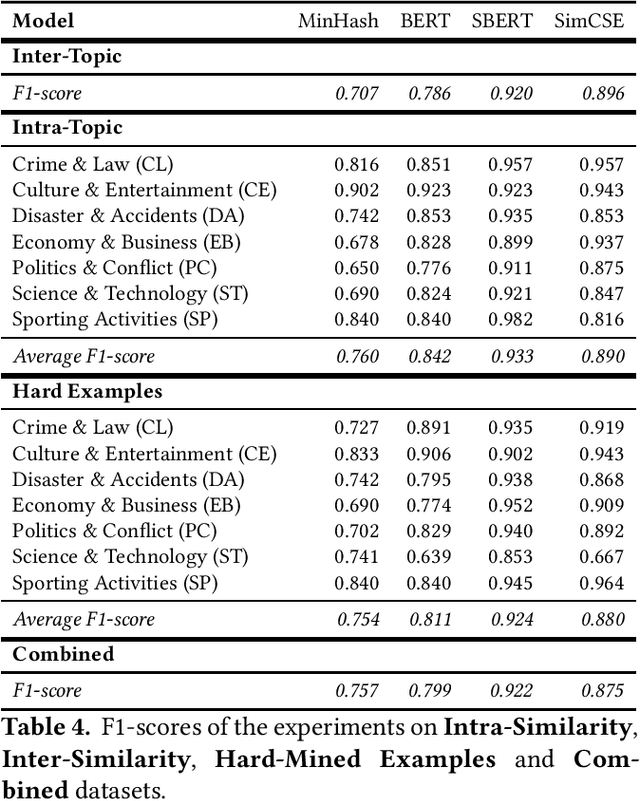
Nowadays, the use of intelligent systems to detect redundant information in news articles has become especially prevalent with the proliferation of news media outlets in order to enhance user experience. However, the heterogeneous nature of news can lead to spurious findings in these systems: Simple heuristics such as whether a pair of news are both about politics can provide strong but deceptive downstream performance. Segmenting news similarity datasets into topics improves the training of these models by forcing them to learn how to distinguish salient characteristics under more narrow domains. However, this requires the existence of topic-specific datasets, which are currently lacking. In this article, we propose a new dataset of similar news, SPICED, which includes seven topics: Crime & Law, Culture & Entertainment, Disasters & Accidents, Economy & Business, Politics & Conflicts, Science & Technology, and Sports. Futhermore, we present four distinct approaches for generating news pairs, which are used in the creation of datasets specifically designed for news similarity detection task. We benchmarked the created datasets using MinHash, BERT, SBERT, and SimCSE models.
Topics as Entity Clusters: Entity-based Topics from Language Models and Graph Neural Networks
Jan 06, 2023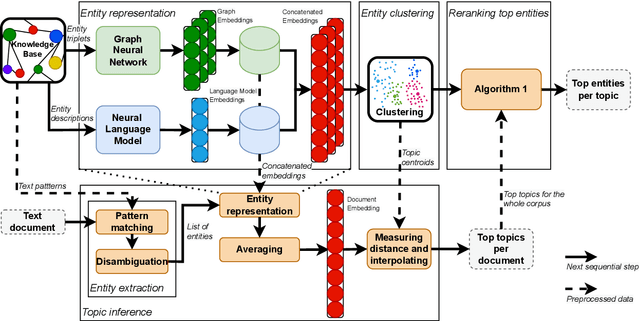
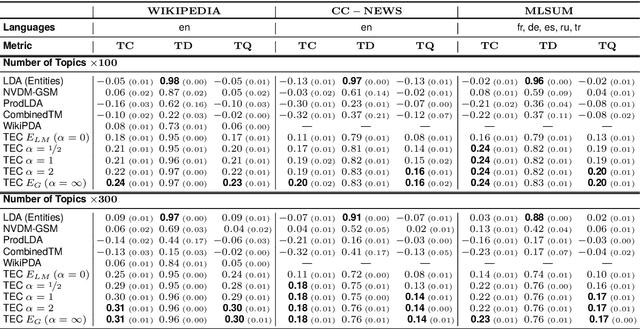

Topic models aim to reveal the latent structure behind a corpus, typically conducted over a bag-of-words representation of documents. In the context of topic modeling, most vocabulary is either irrelevant for uncovering underlying topics or contains strong relationships with relevant concepts, impacting the interpretability of these topics. Furthermore, their limited expressiveness and dependency on language demand considerable computation resources. Hence, we propose a novel approach for cluster-based topic modeling that employs conceptual entities. Entities are language-agnostic representations of real-world concepts rich in relational information. To this end, we extract vector representations of entities from (i) an encyclopedic corpus using a language model; and (ii) a knowledge base using a graph neural network. We demonstrate that our approach consistently outperforms other state-of-the-art topic models across coherency metrics and find that the explicit knowledge encoded in the graph-based embeddings provides more coherent topics than the implicit knowledge encoded with the contextualized embeddings of language models.