 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPICED: News Similarity Detection Dataset with Multiple Topics and Complexity Levels
Paper and Code
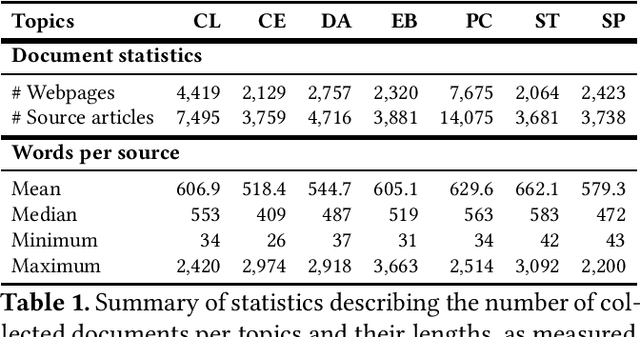
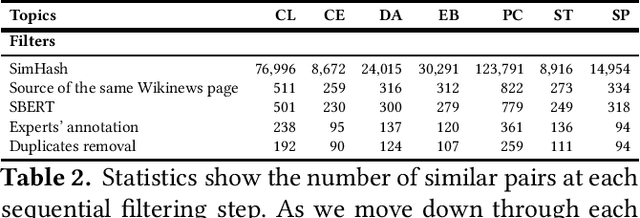
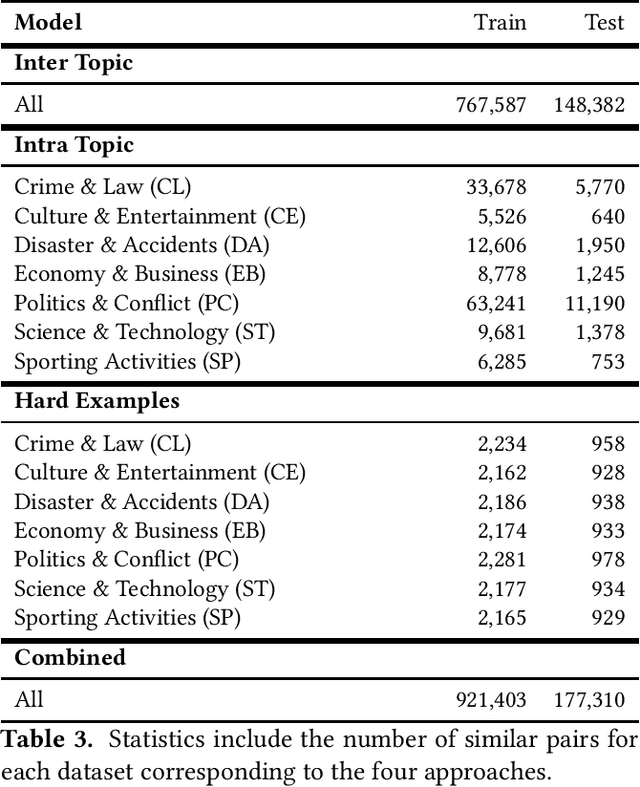
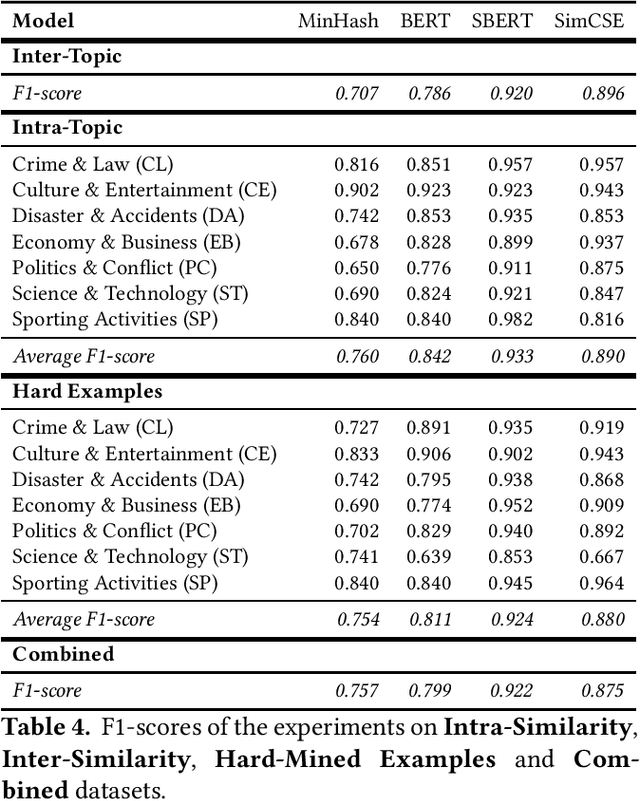
Nowadays, the use of intelligent systems to detect redundant information in news articles has become especially prevalent with the proliferation of news media outlets in order to enhance user experience. However, the heterogeneous nature of news can lead to spurious findings in these systems: Simple heuristics such as whether a pair of news are both about politics can provide strong but deceptive downstream performance. Segmenting news similarity datasets into topics improves the training of these models by forcing them to learn how to distinguish salient characteristics under more narrow domains. However, this requires the existence of topic-specific datasets, which are currently lacking. In this article, we propose a new dataset of similar news, SPICED, which includes seven topics: Crime & Law, Culture & Entertainment, Disasters & Accidents, Economy & Business, Politics & Conflicts, Science & Technology, and Sports. Futhermore, we present four distinct approaches for generating news pairs, which are used in the creation of datasets specifically designed for news similarity detection task. We benchmarked the created datasets using MinHash, BERT, SBERT, and SimCSE models.