 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Covariance Dynamics in Solvable High-Dimensional GANs
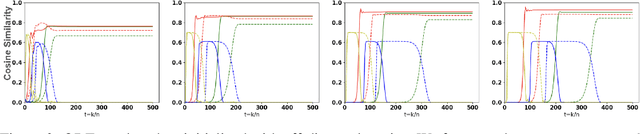
Jun 25, 2026We study a solvable high-dimensional model of generative adversarial network (GAN) training in which a linear generator learns a low-dimensional subspace from data with structured latent covariance. Prior solvable GAN analyses assume unconditional signals with diagonal latent covariance; we extend the multi-feature discriminator setting to class-dependent, correlated, and non-zero-mean latent structure. For the quadratic energy discriminator, all such heterogeneity enters the dynamics through a probability-weighted effective second moment. We prove that the stochastic microscopic training process converges, in the high-dimensional limit, to deterministic ordinary differential equations governed by this effective covariance. In the matched-covariance specialization, the stability analysis yields a mode-wise solvable interval determined by the learning rates and noise level: learning begins when the leading effective eigenvalue crosses the lower threshold, while full recovery requires all relevant effective modes to remain within the interval. This reveals a signal-boosting mechanism: low-rank correlations can lift weak directions above the learnability threshold, whereas overly strong correlations destabilize recovery. Numerical simulations validate the ODE, phase boundary, and boosting mechanism. Experiments on MNIST, FashionMNIST, and CIFAR-10 further show that informed generator covariance improves alignment with the data-driven reference subspace.
GaussianVideo: Efficient Video Representation via Hierarchical Gaussian Splatting
Jan 08, 2025Efficient neural representations for dynamic video scenes are critical for applications ranging from video compression to interactive simulations. Yet, existing methods often face challenges related to high memory usage, lengthy training times, and temporal consistency. To address these issues, we introduce a novel neural video representation that combines 3D Gaussian splatting with continuous camera motion modeling. By leveraging Neural ODEs, our approach learns smooth camera trajectories while maintaining an explicit 3D scene representation through Gaussians. Additionally, we introduce a spatiotemporal hierarchical learning strategy, progressively refining spatial and temporal features to enhance reconstruction quality and accelerate convergence. This memory-efficient approach achieves high-quality rendering at impressive speeds. Experimental results show that our hierarchical learning, combined with robust camera motion modeling, captures complex dynamic scenes with strong temporal consistency, achieving state-of-the-art performance across diverse video datasets in both high- and low-motion scenarios.
Exploring the Precise Dynamics of Single-Layer GAN Models: Leveraging Multi-Feature Discriminators for High-Dimensional Subspace Learning
Nov 01, 2024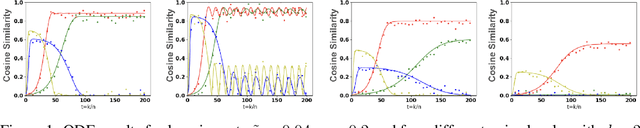
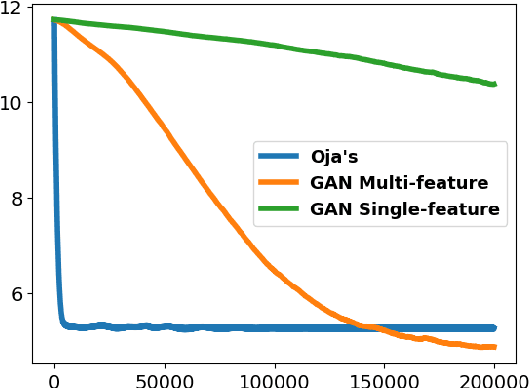

Subspace learning is a critical endeavor in contemporary machine learning, particularly given the vast dimensions of modern datasets. In this study, we delve into the training dynamics of a single-layer GAN model from the perspective of subspace learning, framing these GANs as a novel approach to this fundamental task. Through a rigorous scaling limit analysis, we offer insights into the behavior of this model. Extending beyond prior research that primarily focused on sequential feature learning, we investigate the non-sequential scenario, emphasizing the pivotal role of inter-feature interactions in expediting training and enhancing performance, particularly with an uninformed initialization strategy. Our investigation encompasses both synthetic and real-world datasets, such as MNIST and Olivetti Faces, demonstrating the robustness and applicability of our findings to practical scenarios. By bridging our analysis to the realm of subspace learning, we systematically compare the efficacy of GAN-based methods against conventional approaches, both theoretically and empirically. Notably, our results unveil that while all methodologies successfully capture the underlying subspace, GANs exhibit a remarkable capability to acquire a more informative basis, owing to their intrinsic ability to generate new data samples. This elucidates the unique advantage of GAN-based approaches in subspace learning tasks.
GECTurk: Grammatical Error Correction and Detection Dataset for Turkish
Sep 20, 2023



Grammatical Error Detection and Correction (GEC) tools have proven useful for native speakers and second language learners. Developing such tools requires a large amount of parallel, annotated data, which is unavailable for most languages. Synthetic data generation is a common practice to overcome the scarcity of such data. However, it is not straightforward for morphologically rich languages like Turkish due to complex writing rules that require phonological, morphological, and syntactic information. In this work, we present a flexible and extensible synthetic data generation pipeline for Turkish covering more than 20 expert-curated grammar and spelling rules (a.k.a., writing rules) implemented through complex transformation functions. Using this pipeline, we derive 130,000 high-quality parallel sentences from professionally edited articles. Additionally, we create a more realistic test set by manually annotating a set of movie reviews. We implement three baselines formulating the task as i) neural machine translation, ii) sequence tagging, and iii) prefix tuning with a pretrained decoder-only model, achieving strong results. Furthermore, we perform exhaustive experiments on out-of-domain datasets to gain insights on the transferability and robustness of the proposed approaches. Our results suggest that our corpus, GECTurk, is high-quality and allows knowledge transfer for the out-of-domain setting. To encourage further research on Turkish GEC, we release our datasets, baseline models, and the synthetic data generation pipeline at https://github.com/GGLAB-KU/gecturk.
VidStyleODE: Disentangled Video Editing via StyleGAN and NeuralODEs
Apr 12, 2023



We propose $\textbf{VidStyleODE}$, a spatiotemporally continuous disentangled $\textbf{Vid}$eo representation based upon $\textbf{Style}$GAN and Neural-$\textbf{ODE}$s. Effective traversal of the latent space learned by Generative Adversarial Networks (GANs) has been the basis for recent breakthroughs in image editing. However, the applicability of such advancements to the video domain has been hindered by the difficulty of representing and controlling videos in the latent space of GANs. In particular, videos are composed of content (i.e., appearance) and complex motion components that require a special mechanism to disentangle and control. To achieve this, VidStyleODE encodes the video content in a pre-trained StyleGAN $\mathcal{W}_+$ space and benefits from a latent ODE component to summarize the spatiotemporal dynamics of the input video. Our novel continuous video generation process then combines the two to generate high-quality and temporally consistent videos with varying frame rates. We show that our proposed method enables a variety of applications on real videos: text-guided appearance manipulation, motion manipulation, image animation, and video interpolation and extrapolation. Project website: https://cyberiada.github.io/VidStyleODE