 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFISformer: Replacing Self-Attention with a Fuzzy Inference System in Transformer Models for Time Series Forecasting
Mar 23, 2026Transformers have achieved remarkable progress in time series forecasting, yet their reliance on deterministic dot-product attention limits their capacity to model uncertainty and nonlinear dependencies across multivariate temporal dimensions. To address this limitation, we propose FISFormer, a Fuzzy Inference System-driven Transformer that replaces conventional attention with a FIS Interaction mechanism. In this framework, each query-key pair undergoes a fuzzy inference process for every feature dimension, where learnable membership functions and rule-based reasoning estimate token-wise relational strengths. These FIS-derived interaction weights capture uncertainty and provide interpretable, continuous mappings between tokens. A softmax operation is applied along the token axis to normalize these weights, which are then combined with the corresponding value features through element-wise multiplication to yield the final context-enhanced token representations. This design fuses the interpretability and uncertainty modeling of fuzzy logic with the representational power of Transformers. Extensive experiments on multiple benchmark datasets demonstrate that FISFormer achieves superior forecasting accuracy, noise robustness, and interpretability compared to state-of-the-art Transformer variants, establishing fuzzy inference as an effective alternative to conventional attention mechanisms.
VidStyleODE: Disentangled Video Editing via StyleGAN and NeuralODEs
Apr 12, 2023



We propose $\textbf{VidStyleODE}$, a spatiotemporally continuous disentangled $\textbf{Vid}$eo representation based upon $\textbf{Style}$GAN and Neural-$\textbf{ODE}$s. Effective traversal of the latent space learned by Generative Adversarial Networks (GANs) has been the basis for recent breakthroughs in image editing. However, the applicability of such advancements to the video domain has been hindered by the difficulty of representing and controlling videos in the latent space of GANs. In particular, videos are composed of content (i.e., appearance) and complex motion components that require a special mechanism to disentangle and control. To achieve this, VidStyleODE encodes the video content in a pre-trained StyleGAN $\mathcal{W}_+$ space and benefits from a latent ODE component to summarize the spatiotemporal dynamics of the input video. Our novel continuous video generation process then combines the two to generate high-quality and temporally consistent videos with varying frame rates. We show that our proposed method enables a variety of applications on real videos: text-guided appearance manipulation, motion manipulation, image animation, and video interpolation and extrapolation. Project website: https://cyberiada.github.io/VidStyleODE
Disentangling Content and Motion for Text-Based Neural Video Manipulation
Nov 05, 2022Giving machines the ability to imagine possible new objects or scenes from linguistic descriptions and produce their realistic renderings is arguably one of the most challenging problems in computer vision. Recent advances in deep generative models have led to new approaches that give promising results towards this goal. In this paper, we introduce a new method called DiCoMoGAN for manipulating videos with natural language, aiming to perform local and semantic edits on a video clip to alter the appearances of an object of interest. Our GAN architecture allows for better utilization of multiple observations by disentangling content and motion to enable controllable semantic edits. To this end, we introduce two tightly coupled networks: (i) a representation network for constructing a concise understanding of motion dynamics and temporally invariant content, and (ii) a translation network that exploits the extracted latent content representation to actuate the manipulation according to the target description. Our qualitative and quantitative evaluations demonstrate that DiCoMoGAN significantly outperforms existing frame-based methods, producing temporally coherent and semantically more meaningful results.
Manipulating Attributes of Natural Scenes via Hallucination
Aug 22, 2018
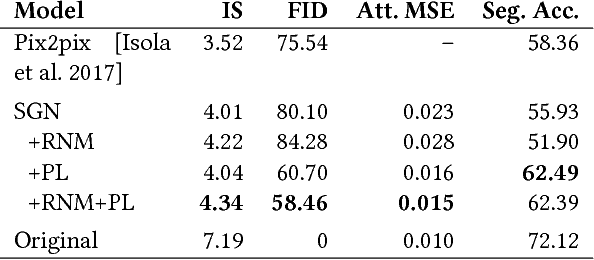
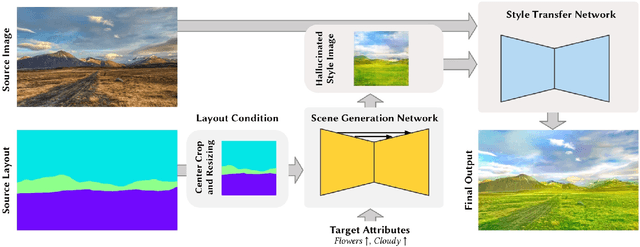
In this study, we explore building a two-stage framework for enabling users to directly manipulate high-level attributes of a natural scene. The key to our approach is a deep generative network which can hallucinate images of a scene as if they were taken at a different season (e.g. during winter), weather condition (e.g. in a cloudy day) or time of the day (e.g. at sunset). Once the scene is hallucinated with the given attributes, the corresponding look is then transferred to the input image while preserving the semantic details intact, giving a photo-realistic manipulation result. As the proposed framework hallucinates what the scene will look like, it does not require any reference style image as commonly utilized in most of the appearance or style transfer approaches. Moreover, it allows to simultaneously manipulate a given scene according to a diverse set of transient attributes within a single model, eliminating the need of training multiple networks per each translation task. Our comprehensive set of qualitative and quantitative results demonstrate the effectiveness of our approach against the competing methods.
Image Synthesis in Multi-Contrast MRI with Conditional Generative Adversarial Networks
Feb 05, 2018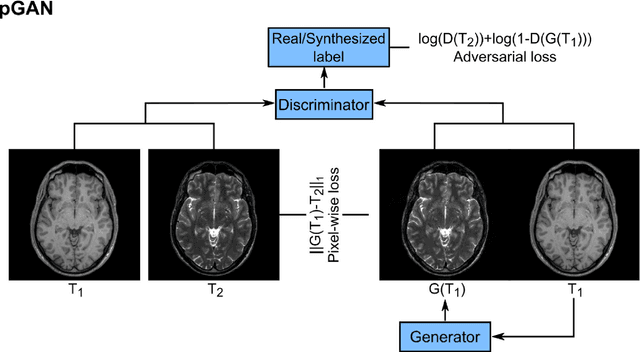
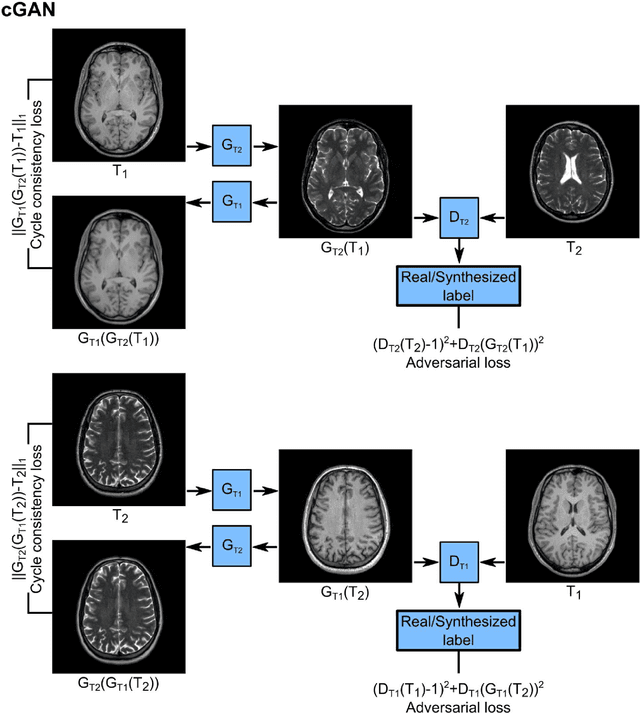
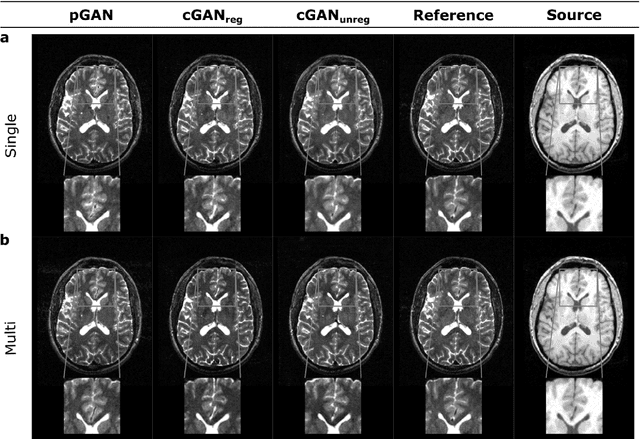
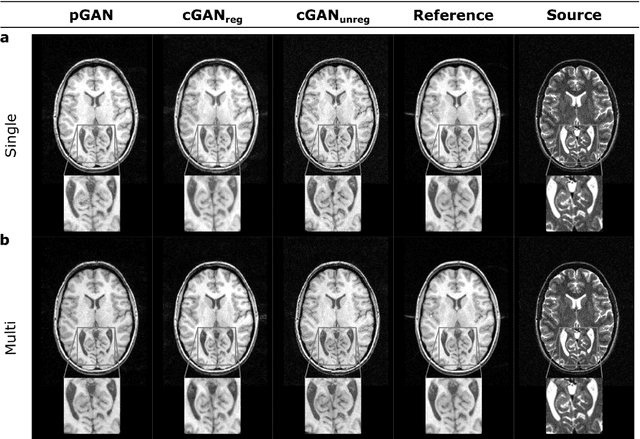
Acquiring images of the same anatomy with multiple different contrasts increases the diversity of diagnostic information available in an MR exam. Yet, scan time limitations may prohibit acquisition of certain contrasts, and images for some contrast may be corrupted by noise and artifacts. In such cases, the ability to synthesize unacquired or corrupted contrasts from remaining contrasts can improve diagnostic utility. For multi-contrast synthesis, current methods learn a nonlinear intensity transformation between the source and target images, either via nonlinear regression or deterministic neural networks. These methods can in turn suffer from loss of high-spatial-frequency information in synthesized images. Here we propose a new approach for multi-contrast MRI synthesis based on conditional generative adversarial networks. The proposed approach preserves high-frequency details via an adversarial loss; and it offers enhanced synthesis performance via a pixel-wise loss for registered multi-contrast images and a cycle-consistency loss for unregistered images. Information from neighboring cross-sections are utilized to further improved synthesis quality. Demonstrations on T1- and T2-weighted images from healthy subjects and patients clearly indicate the superior performance of the proposed approach compared to previous state-of-the-art methods. Our synthesis approach can help improve quality and versatility of multi-contrast MRI exams without the need for prolonged examinations.
Learning to Generate Images of Outdoor Scenes from Attributes and Semantic Layouts
Dec 01, 2016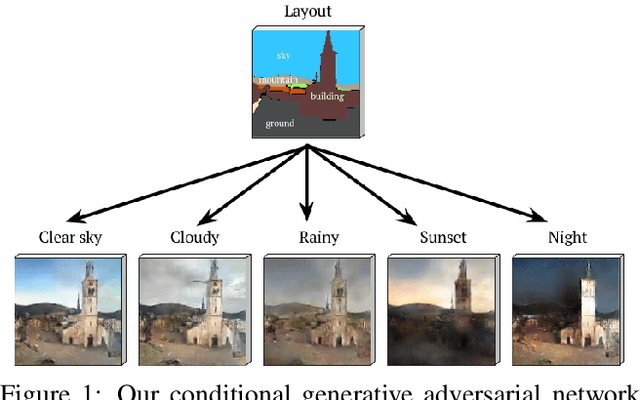
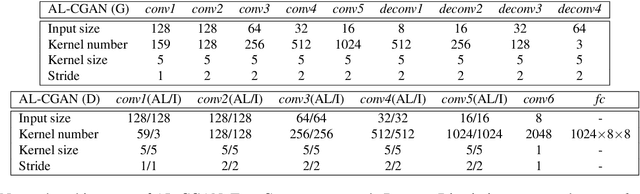
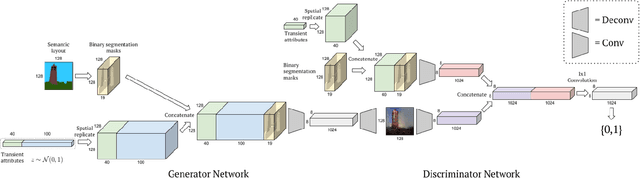

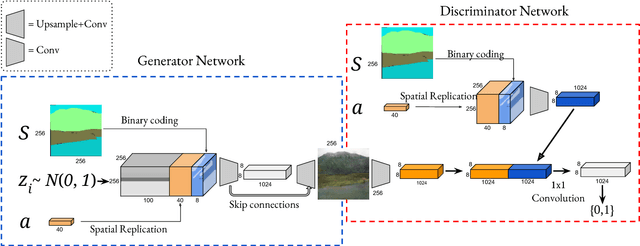
Automatic image synthesis research has been rapidly growing with deep networks getting more and more expressive. In the last couple of years, we have observed images of digits, indoor scenes, birds, chairs, etc. being automatically generated. The expressive power of image generators have also been enhanced by introducing several forms of conditioning variables such as object names, sentences, bounding box and key-point locations. In this work, we propose a novel deep conditional generative adversarial network architecture that takes its strength from the semantic layout and scene attributes integrated as conditioning variables. We show that our architecture is able to generate realistic outdoor scene images under different conditions, e.g. day-night, sunny-foggy, with clear object boundaries.