 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoFusionLRM: Geometry-Aware Self-Correction for Consistent 3D Reconstruction
Feb 15, 2026Single-image 3D reconstruction with large reconstruction models (LRMs) has advanced rapidly, yet reconstructions often exhibit geometric inconsistencies and misaligned details that limit fidelity. We introduce GeoFusionLRM, a geometry-aware self-correction framework that leverages the model's own normal and depth predictions to refine structural accuracy. Unlike prior approaches that rely solely on features extracted from the input image, GeoFusionLRM feeds back geometric cues through a dedicated transformer and fusion module, enabling the model to correct errors and enforce consistency with the conditioning image. This design improves the alignment between the reconstructed mesh and the input views without additional supervision or external signals. Extensive experiments demonstrate that GeoFusionLRM achieves sharper geometry, more consistent normals, and higher fidelity than state-of-the-art LRM baselines.
Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
Jan 22, 2026Recent foundational video-to-video diffusion models have achieved impressive results in editing user provided videos by modifying appearance, motion, or camera movement. However, real-world video editing is often an iterative process, where users refine results across multiple rounds of interaction. In this multi-turn setting, current video editors struggle to maintain cross-consistency across sequential edits. In this work, we tackle, for the first time, the problem of cross-consistency in multi-turn video editing and introduce Memory-V2V, a simple, yet effective framework that augments existing video-to-video models with explicit memory. Given an external cache of previously edited videos, Memory-V2V employs accurate retrieval and dynamic tokenization strategies to condition the current editing step on prior results. To further mitigate redundancy and computational overhead, we propose a learnable token compressor within the DiT backbone that compresses redundant conditioning tokens while preserving essential visual cues, achieving an overall speedup of 30%. We validate Memory-V2V on challenging tasks including video novel view synthesis and text-conditioned long video editing. Extensive experiments show that Memory-V2V produces videos that are significantly more cross-consistent with minimal computational overhead, while maintaining or even improving task-specific performance over state-of-the-art baselines. Project page: https://dohunlee1.github.io/MemoryV2V
V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Dec 12, 2025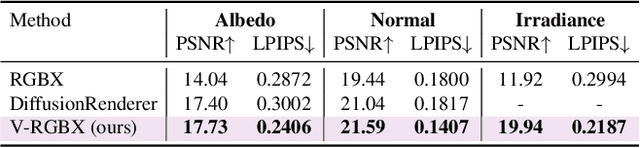
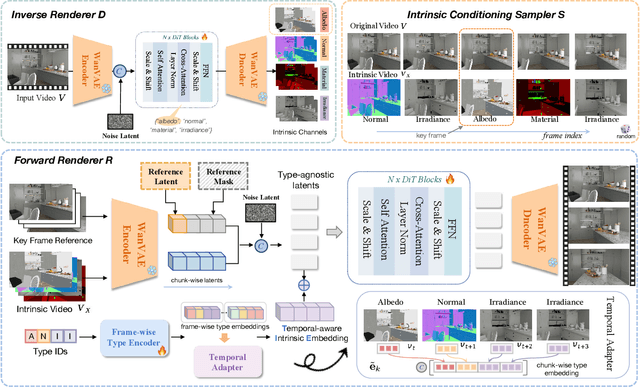
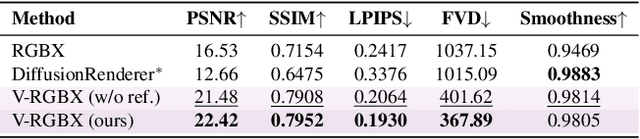

Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.
Improving Video Diffusion Transformer Training by Multi-Feature Fusion and Alignment from Self-Supervised Vision Encoders
Sep 11, 2025Video diffusion models have advanced rapidly in the recent years as a result of series of architectural innovations (e.g., diffusion transformers) and use of novel training objectives (e.g., flow matching). In contrast, less attention has been paid to improving the feature representation power of such models. In this work, we show that training video diffusion models can benefit from aligning the intermediate features of the video generator with feature representations of pre-trained vision encoders. We propose a new metric and conduct an in-depth analysis of various vision encoders to evaluate their discriminability and temporal consistency, thereby assessing their suitability for video feature alignment. Based on the analysis, we present Align4Gen which provides a novel multi-feature fusion and alignment method integrated into video diffusion model training. We evaluate Align4Gen both for unconditional and class-conditional video generation tasks and show that it results in improved video generation as quantified by various metrics. Full video results are available on our project page: https://align4gen.github.io/align4gen/
ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models
May 12, 2025Current diffusion-based text-to-video methods are limited to producing short video clips of a single shot and lack the capability to generate multi-shot videos with discrete transitions where the same character performs distinct activities across the same or different backgrounds. To address this limitation we propose a framework that includes a dataset collection pipeline and architectural extensions to video diffusion models to enable text-to-multi-shot video generation. Our approach enables generation of multi-shot videos as a single video with full attention across all frames of all shots, ensuring character and background consistency, and allows users to control the number, duration, and content of shots through shot-specific conditioning. This is achieved by incorporating a transition token into the text-to-video model to control at which frames a new shot begins and a local attention masking strategy which controls the transition token's effect and allows shot-specific prompting. To obtain training data we propose a novel data collection pipeline to construct a multi-shot video dataset from existing single-shot video datasets. Extensive experiments demonstrate that fine-tuning a pre-trained text-to-video model for a few thousand iterations is enough for the model to subsequently be able to generate multi-shot videos with shot-specific control, outperforming the baselines. You can find more details in https://shotadapter.github.io/
MonetGPT: Solving Puzzles Enhances MLLMs' Image Retouching Skills
May 09, 2025Retouching is an essential task in post-manipulation of raw photographs. Generative editing, guided by text or strokes, provides a new tool accessible to users but can easily change the identity of the original objects in unacceptable and unpredictable ways. In contrast, although traditional procedural edits, as commonly supported by photoediting tools (e.g., Gimp, Lightroom), are conservative, they are still preferred by professionals. Unfortunately, professional quality retouching involves many individual procedural editing operations that is challenging to plan for most novices. In this paper, we ask if a multimodal large language model (MLLM) can be taught to critique raw photographs, suggest suitable remedies, and finally realize them with a given set of pre-authored procedural image operations. We demonstrate that MLLMs can be first made aware of the underlying image processing operations, by training them to solve specially designed visual puzzles. Subsequently, such an operation-aware MLLM can both plan and propose edit sequences. To facilitate training, given a set of expert-edited photos, we synthesize a reasoning dataset by procedurally manipulating the expert edits and then grounding a pretrained LLM on the visual adjustments, to synthesize reasoning for finetuning. The proposed retouching operations are, by construction, understandable by the users, preserve object details and resolution, and can be optionally overridden. We evaluate our setup on a variety of test examples and show advantages, in terms of explainability and identity preservation, over existing generative and other procedural alternatives. Code, data, models, and supplementary results can be found via our project website at https://monetgpt.github.io.
3D Stylization via Large Reconstruction Model
Apr 30, 2025With the growing success of text or image guided 3D generators, users demand more control over the generation process, appearance stylization being one of them. Given a reference image, this requires adapting the appearance of a generated 3D asset to reflect the visual style of the reference while maintaining visual consistency from multiple viewpoints. To tackle this problem, we draw inspiration from the success of 2D stylization methods that leverage the attention mechanisms in large image generation models to capture and transfer visual style. In particular, we probe if large reconstruction models, commonly used in the context of 3D generation, has a similar capability. We discover that the certain attention blocks in these models capture the appearance specific features. By injecting features from a visual style image to such blocks, we develop a simple yet effective 3D appearance stylization method. Our method does not require training or test time optimization. Through both quantitative and qualitative evaluations, we demonstrate that our approach achieves superior results in terms of 3D appearance stylization, significantly improving efficiency while maintaining high-quality visual outcomes.
PRISM: A Unified Framework for Photorealistic Reconstruction and Intrinsic Scene Modeling
Apr 19, 2025We present PRISM, a unified framework that enables multiple image generation and editing tasks in a single foundational model. Starting from a pre-trained text-to-image diffusion model, PRISM proposes an effective fine-tuning strategy to produce RGB images along with intrinsic maps (referred to as X layers) simultaneously. Unlike previous approaches, which infer intrinsic properties individually or require separate models for decomposition and conditional generation, PRISM maintains consistency across modalities by generating all intrinsic layers jointly. It supports diverse tasks, including text-to-RGBX generation, RGB-to-X decomposition, and X-to-RGBX conditional generation. Additionally, PRISM enables both global and local image editing through conditioning on selected intrinsic layers and text prompts. Extensive experiments demonstrate the competitive performance of PRISM both for intrinsic image decomposition and conditional image generation while preserving the base model's text-to-image generation capability.
MD-ProjTex: Texturing 3D Shapes with Multi-Diffusion Projection
Apr 03, 2025We introduce MD-ProjTex, a method for fast and consistent text-guided texture generation for 3D shapes using pretrained text-to-image diffusion models. At the core of our approach is a multi-view consistency mechanism in UV space, which ensures coherent textures across different viewpoints. Specifically, MD-ProjTex fuses noise predictions from multiple views at each diffusion step and jointly updates the per-view denoising directions to maintain 3D consistency. In contrast to existing state-of-the-art methods that rely on optimization or sequential view synthesis, MD-ProjTex is computationally more efficient and achieves better quantitative and qualitative results.
VideoHandles: Editing 3D Object Compositions in Videos Using Video Generative Priors
Mar 03, 2025Generative methods for image and video editing use generative models as priors to perform edits despite incomplete information, such as changing the composition of 3D objects shown in a single image. Recent methods have shown promising composition editing results in the image setting, but in the video setting, editing methods have focused on editing object's appearance and motion, or camera motion, and as a result, methods to edit object composition in videos are still missing. We propose \name as a method for editing 3D object compositions in videos of static scenes with camera motion. Our approach allows editing the 3D position of a 3D object across all frames of a video in a temporally consistent manner. This is achieved by lifting intermediate features of a generative model to a 3D reconstruction that is shared between all frames, editing the reconstruction, and projecting the features on the edited reconstruction back to each frame. To the best of our knowledge, this is the first generative approach to edit object compositions in videos. Our approach is simple and training-free, while outperforming state-of-the-art image editing baselines.