 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoST: Level of Semantics Tokenization for 3D Shapes
Mar 18, 2026Tokenization is a fundamental technique in the generative modeling of various modalities. In particular, it plays a critical role in autoregressive (AR) models, which have recently emerged as a compelling option for 3D generation. However, optimal tokenization of 3D shapes remains an open question. State-of-the-art (SOTA) methods primarily rely on geometric level-of-detail (LoD) hierarchies, originally designed for rendering and compression. These spatial hierarchies are often token-inefficient and lack semantic coherence for AR modeling. We propose Level-of-Semantics Tokenization (LoST), which orders tokens by semantic salience, such that early prefixes decode into complete, plausible shapes that possess principal semantics, while subsequent tokens refine instance-specific geometric and semantic details. To train LoST, we introduce Relational Inter-Distance Alignment (RIDA), a novel 3D semantic alignment loss that aligns the relational structure of the 3D shape latent space with that of the semantic DINO feature space. Experiments show that LoST achieves SOTA reconstruction, surpassing previous LoD-based 3D shape tokenizers by large margins on both geometric and semantic reconstruction metrics. Moreover, LoST achieves efficient, high-quality AR 3D generation and enables downstream tasks like semantic retrieval, while using only 0.1%-10% of the tokens needed by prior AR models.
MonetGPT: Solving Puzzles Enhances MLLMs' Image Retouching Skills
May 09, 2025



Retouching is an essential task in post-manipulation of raw photographs. Generative editing, guided by text or strokes, provides a new tool accessible to users but can easily change the identity of the original objects in unacceptable and unpredictable ways. In contrast, although traditional procedural edits, as commonly supported by photoediting tools (e.g., Gimp, Lightroom), are conservative, they are still preferred by professionals. Unfortunately, professional quality retouching involves many individual procedural editing operations that is challenging to plan for most novices. In this paper, we ask if a multimodal large language model (MLLM) can be taught to critique raw photographs, suggest suitable remedies, and finally realize them with a given set of pre-authored procedural image operations. We demonstrate that MLLMs can be first made aware of the underlying image processing operations, by training them to solve specially designed visual puzzles. Subsequently, such an operation-aware MLLM can both plan and propose edit sequences. To facilitate training, given a set of expert-edited photos, we synthesize a reasoning dataset by procedurally manipulating the expert edits and then grounding a pretrained LLM on the visual adjustments, to synthesize reasoning for finetuning. The proposed retouching operations are, by construction, understandable by the users, preserve object details and resolution, and can be optionally overridden. We evaluate our setup on a variety of test examples and show advantages, in terms of explainability and identity preservation, over existing generative and other procedural alternatives. Code, data, models, and supplementary results can be found via our project website at https://monetgpt.github.io.
SMF: Template-free and Rig-free Animation Transfer using Kinetic Codes
Apr 07, 2025Animation retargeting involves applying a sparse motion description (e.g., 2D/3D keypoint sequences) to a given character mesh to produce a semantically plausible and temporally coherent full-body motion. Existing approaches come with a mix of restrictions - they require annotated training data, assume access to template-based shape priors or artist-designed deformation rigs, suffer from limited generalization to unseen motion and/or shapes, or exhibit motion jitter. We propose Self-supervised Motion Fields (SMF) as a self-supervised framework that can be robustly trained with sparse motion representations, without requiring dataset specific annotations, templates, or rigs. At the heart of our method are Kinetic Codes, a novel autoencoder-based sparse motion encoding, that exposes a semantically rich latent space simplifying large-scale training. Our architecture comprises dedicated spatial and temporal gradient predictors, which are trained end-to-end. The resultant network, regularized by the Kinetic Codes's latent space, has good generalization across shapes and motions. We evaluated our method on unseen motion sampled from AMASS, D4D, Mixamo, and raw monocular video for animation transfer on various characters with varying shapes and topology. We report a new SoTA on the AMASS dataset in the context of generalization to unseen motion. Project webpage at https://motionfields.github.io/
FlairGPT: Repurposing LLMs for Interior Designs
Jan 08, 2025



Interior design involves the careful selection and arrangement of objects to create an aesthetically pleasing, functional, and harmonized space that aligns with the client's design brief. This task is particularly challenging, as a successful design must not only incorporate all the necessary objects in a cohesive style, but also ensure they are arranged in a way that maximizes accessibility, while adhering to a variety of affordability and usage considerations. Data-driven solutions have been proposed, but these are typically room- or domain-specific and lack explainability in their design design considerations used in producing the final layout. In this paper, we investigate if large language models (LLMs) can be directly utilized for interior design. While we find that LLMs are not yet capable of generating complete layouts, they can be effectively leveraged in a structured manner, inspired by the workflow of interior designers. By systematically probing LLMs, we can reliably generate a list of objects along with relevant constraints that guide their placement. We translate this information into a design layout graph, which is then solved using an off-the-shelf constrained optimization setup to generate the final layouts. We benchmark our algorithm in various design configurations against existing LLM-based methods and human designs, and evaluate the results using a variety of quantitative and qualitative metrics along with user studies. In summary, we demonstrate that LLMs, when used in a structured manner, can effectively generate diverse high-quality layouts, making them a viable solution for creating large-scale virtual scenes. Project webpage at https://flairgpt.github.io/
Temporal Residual Jacobians For Rig-free Motion Transfer
Jul 20, 2024We introduce Temporal Residual Jacobians as a novel representation to enable data-driven motion transfer. Our approach does not assume access to any rigging or intermediate shape keyframes, produces geometrically and temporally consistent motions, and can be used to transfer long motion sequences. Central to our approach are two coupled neural networks that individually predict local geometric and temporal changes that are subsequently integrated, spatially and temporally, to produce the final animated meshes. The two networks are jointly trained, complement each other in producing spatial and temporal signals, and are supervised directly with 3D positional information. During inference, in the absence of keyframes, our method essentially solves a motion extrapolation problem. We test our setup on diverse meshes (synthetic and scanned shapes) to demonstrate its superiority in generating realistic and natural-looking animations on unseen body shapes against SoTA alternatives. Supplemental video and code are available at https://temporaljacobians.github.io/ .
Diffusion 3D Features (Diff3F): Decorating Untextured Shapes with Distilled Semantic Features
Nov 28, 2023



We present Diff3F as a simple, robust, and class-agnostic feature descriptor that can be computed for untextured input shapes (meshes or point clouds). Our method distills diffusion features from image foundational models onto input shapes. Specifically, we use the input shapes to produce depth and normal maps as guidance for conditional image synthesis, and in the process produce (diffusion) features in 2D that we subsequently lift and aggregate on the original surface. Our key observation is that even if the conditional image generations obtained from multi-view rendering of the input shapes are inconsistent, the associated image features are robust and can be directly aggregated across views. This produces semantic features on the input shapes, without requiring additional data or training. We perform extensive experiments on multiple benchmarks (SHREC'19, SHREC'20, and TOSCA) and demonstrate that our features, being semantic instead of geometric, produce reliable correspondence across both isometeric and non-isometrically related shape families.
ProteusNeRF: Fast Lightweight NeRF Editing using 3D-Aware Image Context
Oct 15, 2023



Neural Radiance Fields (NeRFs) have recently emerged as a popular option for photo-realistic object capture due to their ability to faithfully capture high-fidelity volumetric content even from handheld video input. Although much research has been devoted to efficient optimization leading to real-time training and rendering, options for interactive editing NeRFs remain limited. We present a very simple but effective neural network architecture that is fast and efficient while maintaining a low memory footprint. This architecture can be incrementally guided through user-friendly image-based edits. Our representation allows straightforward object selection via semantic feature distillation at the training stage. More importantly, we propose a local 3D-aware image context to facilitate view-consistent image editing that can then be distilled into fine-tuned NeRFs, via geometric and appearance adjustments. We evaluate our setup on a variety of examples to demonstrate appearance and geometric edits and report 10-30x speedup over concurrent work focusing on text-guided NeRF editing. Video results can be seen on our project webpage at https://proteusnerf.github.io.
A study of traits that affect learnability in GANs
Nov 27, 2020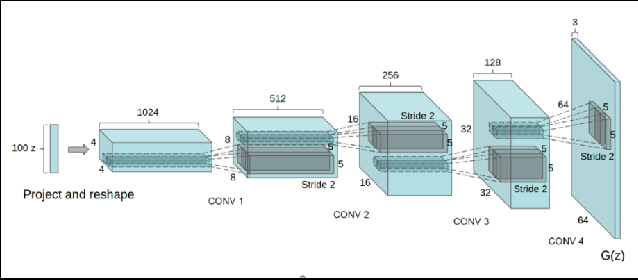
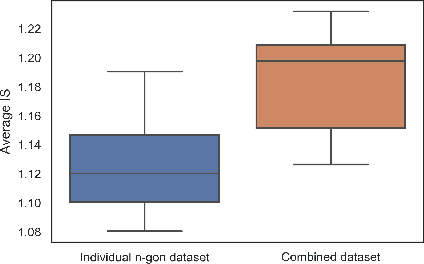
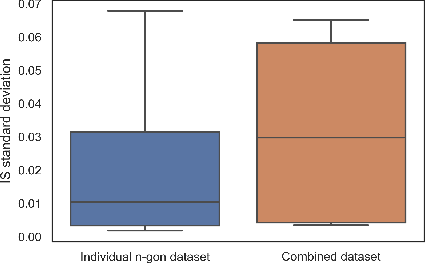
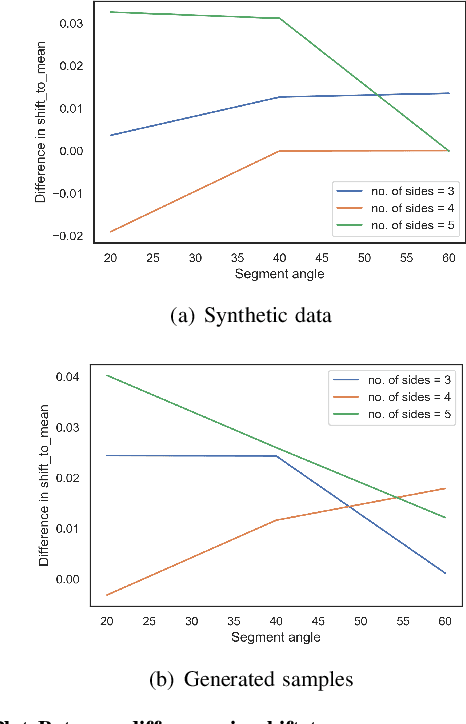
Generative Adversarial Networks GANs are algorithmic architectures that use two neural networks, pitting one against the opposite so as to come up with new, synthetic instances of data that can pass for real data. Training a GAN is a challenging problem which requires us to apply advanced techniques like hyperparameter tuning, architecture engineering etc. Many different losses, regularization and normalization schemes, network architectures have been proposed to solve this challenging problem for different types of datasets. It becomes necessary to understand the experimental observations and deduce a simple theory for it. In this paper, we perform empirical experiments using parameterized synthetic datasets to probe what traits affect learnability.