 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiMI: A Domain-Specific Language Model for Indian Finance Ecosystem
Feb 05, 2026We present FiMI (Finance Model for India), a domain-specialized financial language model developed for Indian digital payment systems. We develop two model variants: FiMI Base and FiMI Instruct. FiMI adapts the Mistral Small 24B architecture through a multi-stage training pipeline, beginning with continuous pre-training on 68 Billion tokens of curated financial, multilingual (English, Hindi, Hinglish), and synthetic data. This is followed by instruction fine-tuning and domain-specific supervised fine-tuning focused on multi-turn, tool-driven conversations that model real-world workflows, such as transaction disputes and mandate lifecycle management. Evaluations reveal that FiMI Base achieves a 20% improvement over the Mistral Small 24B Base model on finance reasoning benchmark, while FiMI Instruct outperforms the Mistral Small 24B Instruct model by 87% on domain-specific tool-calling. Moreover, FiMI achieves these significant domain gains while maintaining comparable performance to models of similar size on general benchmarks.
HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction
Aug 09, 2024



Extraction and interpretation of intricate information from unstructured text data arising in financial applications, such as earnings call transcripts, present substantial challenges to large language models (LLMs) even using the current best practices to use Retrieval Augmented Generation (RAG) (referred to as VectorRAG techniques which utilize vector databases for information retrieval) due to challenges such as domain specific terminology and complex formats of the documents. We introduce a novel approach based on a combination, called HybridRAG, of the Knowledge Graphs (KGs) based RAG techniques (called GraphRAG) and VectorRAG techniques to enhance question-answer (Q&A) systems for information extraction from financial documents that is shown to be capable of generating accurate and contextually relevant answers. Using experiments on a set of financial earning call transcripts documents which come in the form of Q&A format, and hence provide a natural set of pairs of ground-truth Q&As, we show that HybridRAG which retrieves context from both vector database and KG outperforms both traditional VectorRAG and GraphRAG individually when evaluated at both the retrieval and generation stages in terms of retrieval accuracy and answer generation. The proposed technique has applications beyond the financial domain
Machine Learning Techniques to Identify Hand Gestures amidst Forearm Muscle Signals
Jan 15, 2024This study investigated the use of forearm EMG data for distinguishing eight hand gestures, employing the Neural Network and Random Forest algorithms on data from ten participants. The Neural Network achieved 97 percent accuracy with 1000-millisecond windows, while the Random Forest achieved 85 percent accuracy with 200-millisecond windows. Larger window sizes improved gesture classification due to increased temporal resolution. The Random Forest exhibited faster processing at 92 milliseconds, compared to the Neural Network's 124 milliseconds. In conclusion, the study identified a Neural Network with a 1000-millisecond stream as the most accurate (97 percent), and a Random Forest with a 200-millisecond stream as the most efficient (85 percent). Future research should focus on increasing sample size, incorporating more hand gestures, and exploring different feature extraction methods and modeling algorithms to enhance system accuracy and efficiency.
Fast, Self Supervised, Fully Convolutional Color Normalization of H&E Stained Images
Nov 30, 2020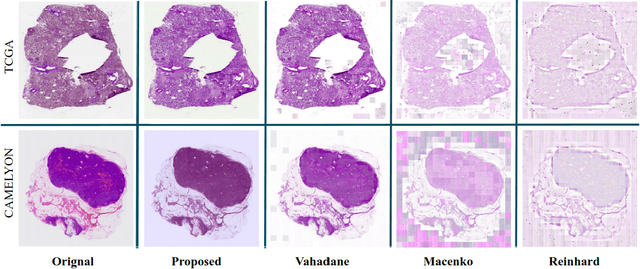
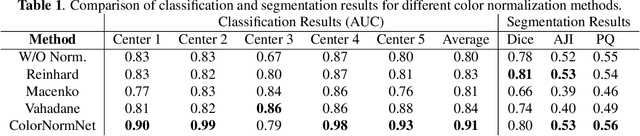

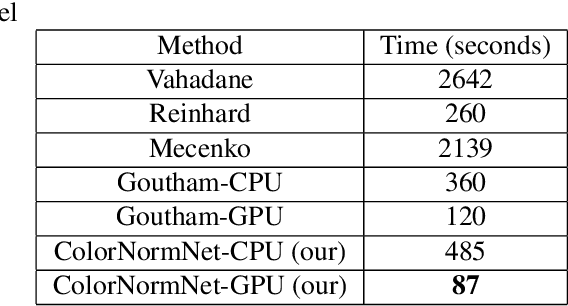
Performance of deep learning algorithms decreases drastically if the data distributions of the training and testing sets are different. Due to variations in staining protocols, reagent brands, and habits of technicians, color variation in digital histopathology images is quite common. Color variation causes problems for the deployment of deep learning-based solutions for automatic diagnosis system in histopathology. Previously proposed color normalization methods consider a small patch as a reference for normalization, which creates artifacts on out-of-distribution source images. These methods are also slow as most of the computation is performed on CPUs instead of the GPUs. We propose a color normalization technique, which is fast during its self-supervised training as well as inference. Our method is based on a lightweight fully-convolutional neural network and can be easily attached to a deep learning-based pipeline as a pre-processing block. For classification and segmentation tasks on CAMELYON17 and MoNuSeg datasets respectively, the proposed method is faster and gives a greater increase in accuracy than the state of the art methods.
A study of traits that affect learnability in GANs
Nov 27, 2020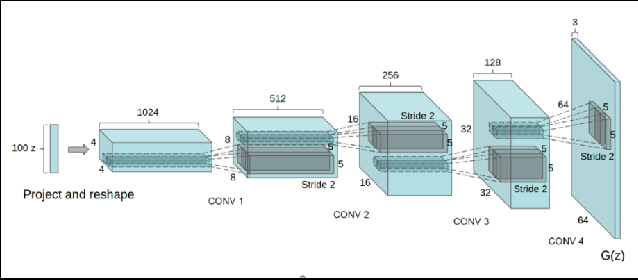
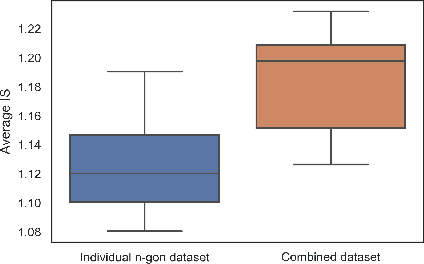
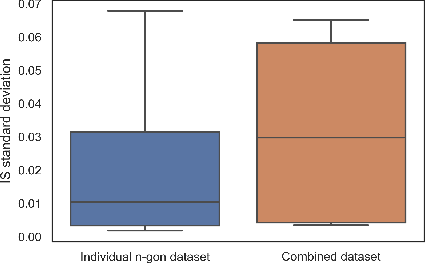
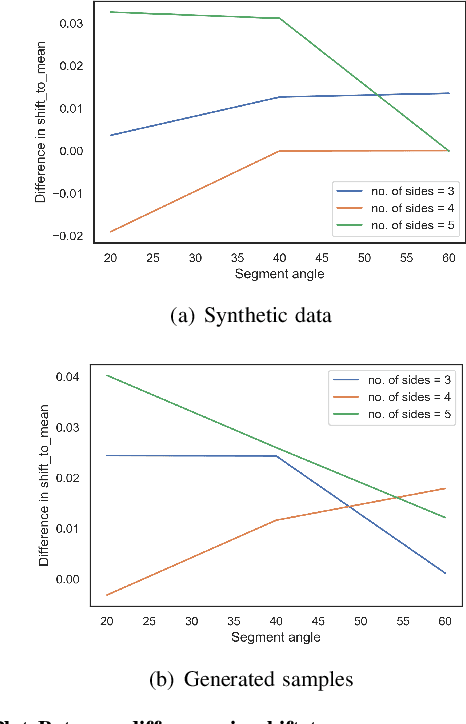
Generative Adversarial Networks GANs are algorithmic architectures that use two neural networks, pitting one against the opposite so as to come up with new, synthetic instances of data that can pass for real data. Training a GAN is a challenging problem which requires us to apply advanced techniques like hyperparameter tuning, architecture engineering etc. Many different losses, regularization and normalization schemes, network architectures have been proposed to solve this challenging problem for different types of datasets. It becomes necessary to understand the experimental observations and deduce a simple theory for it. In this paper, we perform empirical experiments using parameterized synthetic datasets to probe what traits affect learnability.