 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Adjusted Harm Scoring for Automated Red Teaming for LLMs in Financial Services
Mar 11, 2026The rapid adoption of large language models (LLMs) in financial services introduces new operational, regulatory, and security risks. Yet most red-teaming benchmarks remain domain-agnostic and fail to capture failure modes specific to regulated BFSI settings, where harmful behavior can be elicited through legally or professionally plausible framing. We propose a risk-aware evaluation framework for LLM security failures in Banking, Financial Services, and Insurance (BFSI), combining a domain-specific taxonomy of financial harms, an automated multi-round red-teaming pipeline, and an ensemble-based judging protocol. We introduce the Risk-Adjusted Harm Score (RAHS), a risk-sensitive metric that goes beyond success rates by quantifying the operational severity of disclosures, accounting for mitigation signals, and leveraging inter-judge agreement. Across diverse models, we find that higher decoding stochasticity and sustained adaptive interaction not only increase jailbreak success, but also drive systematic escalation toward more severe and operationally actionable financial disclosures. These results expose limitations of single-turn, domain-agnostic security evaluation and motivate risk-sensitive assessment under prolonged adversarial pressure for real-world BFSI deployment.
Memoria: A Scalable Agentic Memory Framework for Personalized Conversational AI
Dec 14, 2025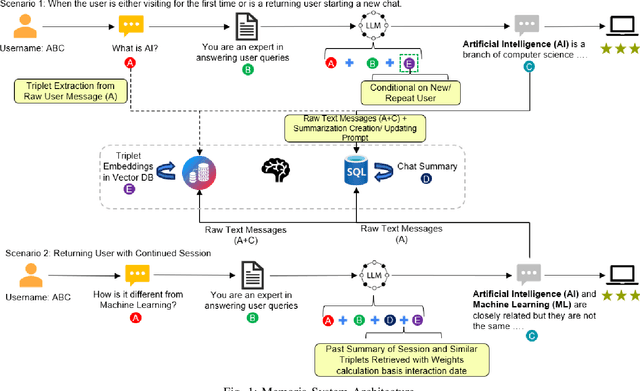

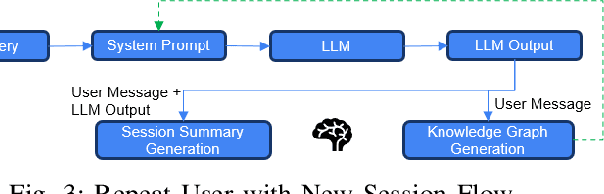
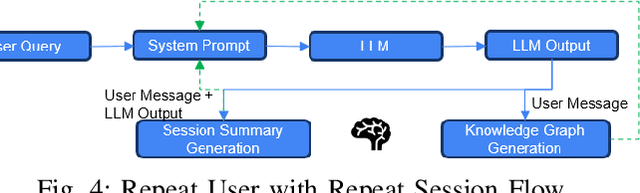
Agentic memory is emerging as a key enabler for large language models (LLM) to maintain continuity, personalization, and long-term context in extended user interactions, critical capabilities for deploying LLMs as truly interactive and adaptive agents. Agentic memory refers to the memory that provides an LLM with agent-like persistence: the ability to retain and act upon information across conversations, similar to how a human would. We present Memoria, a modular memory framework that augments LLM-based conversational systems with persistent, interpretable, and context-rich memory. Memoria integrates two complementary components: dynamic session-level summarization and a weighted knowledge graph (KG)-based user modelling engine that incrementally captures user traits, preferences, and behavioral patterns as structured entities and relationships. This hybrid architecture enables both short-term dialogue coherence and long-term personalization while operating within the token constraints of modern LLMs. We demonstrate how Memoria enables scalable, personalized conversational artificial intelligence (AI) by bridging the gap between stateless LLM interfaces and agentic memory systems, offering a practical solution for industry applications requiring adaptive and evolving user experiences.
FINCH: Financial Intelligence using Natural language for Contextualized SQL Handling
Oct 02, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, has long been a central challenge in NLP. While progress has been significant, applying it to the financial domain remains especially difficult due to complex schema, domain-specific terminology, and high stakes of error. Despite this, there is no dedicated large-scale financial dataset to advance research, creating a critical gap. To address this, we introduce a curated financial dataset (FINCH) comprising 292 tables and 75,725 natural language-SQL pairs, enabling both fine-tuning and rigorous evaluation. Building on this resource, we benchmark reasoning models and language models of varying scales, providing a systematic analysis of their strengths and limitations in financial Text-to-SQL tasks. Finally, we propose a finance-oriented evaluation metric (FINCH Score) that captures nuances overlooked by existing measures, offering a more faithful assessment of model performance.
A Comparative Study of DSPy Teleprompter Algorithms for Aligning Large Language Models Evaluation Metrics to Human Evaluation
Dec 19, 2024



We argue that the Declarative Self-improving Python (DSPy) optimizers are a way to align the large language model (LLM) prompts and their evaluations to the human annotations. We present a comparative analysis of five teleprompter algorithms, namely, Cooperative Prompt Optimization (COPRO), Multi-Stage Instruction Prompt Optimization (MIPRO), BootstrapFewShot, BootstrapFewShot with Optuna, and K-Nearest Neighbor Few Shot, within the DSPy framework with respect to their ability to align with human evaluations. As a concrete example, we focus on optimizing the prompt to align hallucination detection (using LLM as a judge) to human annotated ground truth labels for a publicly available benchmark dataset. Our experiments demonstrate that optimized prompts can outperform various benchmark methods to detect hallucination, and certain telemprompters outperform the others in at least these experiments.
How to Choose a Threshold for an Evaluation Metric for Large Language Models
Dec 10, 2024



To ensure and monitor large language models (LLMs) reliably, various evaluation metrics have been proposed in the literature. However, there is little research on prescribing a methodology to identify a robust threshold on these metrics even though there are many serious implications of an incorrect choice of the thresholds during deployment of the LLMs. Translating the traditional model risk management (MRM) guidelines within regulated industries such as the financial industry, we propose a step-by-step recipe for picking a threshold for a given LLM evaluation metric. We emphasize that such a methodology should start with identifying the risks of the LLM application under consideration and risk tolerance of the stakeholders. We then propose concrete and statistically rigorous procedures to determine a threshold for the given LLM evaluation metric using available ground-truth data. As a concrete example to demonstrate the proposed methodology at work, we employ it on the Faithfulness metric, as implemented in various publicly available libraries, using the publicly available HaluBench dataset. We also lay a foundation for creating systematic approaches to select thresholds, not only for LLMs but for any GenAI applications.
HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction
Aug 09, 2024



Extraction and interpretation of intricate information from unstructured text data arising in financial applications, such as earnings call transcripts, present substantial challenges to large language models (LLMs) even using the current best practices to use Retrieval Augmented Generation (RAG) (referred to as VectorRAG techniques which utilize vector databases for information retrieval) due to challenges such as domain specific terminology and complex formats of the documents. We introduce a novel approach based on a combination, called HybridRAG, of the Knowledge Graphs (KGs) based RAG techniques (called GraphRAG) and VectorRAG techniques to enhance question-answer (Q&A) systems for information extraction from financial documents that is shown to be capable of generating accurate and contextually relevant answers. Using experiments on a set of financial earning call transcripts documents which come in the form of Q&A format, and hence provide a natural set of pairs of ground-truth Q&As, we show that HybridRAG which retrieves context from both vector database and KG outperforms both traditional VectorRAG and GraphRAG individually when evaluated at both the retrieval and generation stages in terms of retrieval accuracy and answer generation. The proposed technique has applications beyond the financial domain
Quantile Regression using Random Forest Proximities
Aug 05, 2024
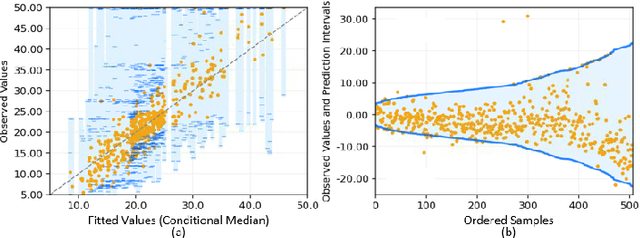
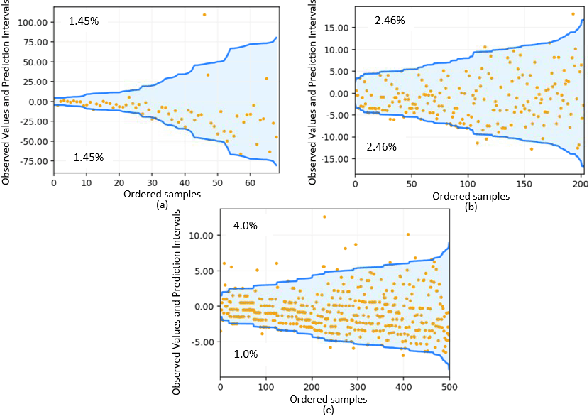

Due to the dynamic nature of financial markets, maintaining models that produce precise predictions over time is difficult. Often the goal isn't just point prediction but determining uncertainty. Quantifying uncertainty, especially the aleatoric uncertainty due to the unpredictable nature of market drivers, helps investors understand varying risk levels. Recently, quantile regression forests (QRF) have emerged as a promising solution: Unlike most basic quantile regression methods that need separate models for each quantile, quantile regression forests estimate the entire conditional distribution of the target variable with a single model, while retaining all the salient features of a typical random forest. We introduce a novel approach to compute quantile regressions from random forests that leverages the proximity (i.e., distance metric) learned by the model and infers the conditional distribution of the target variable. We evaluate the proposed methodology using publicly available datasets and then apply it towards the problem of forecasting the average daily volume of corporate bonds. We show that using quantile regression using Random Forest proximities demonstrates superior performance in approximating conditional target distributions and prediction intervals to the original version of QRF. We also demonstrate that the proposed framework is significantly more computationally efficient than traditional approaches to quantile regressions.
Towards Enhanced Local Explainability of Random Forests: a Proximity-Based Approach
Oct 19, 2023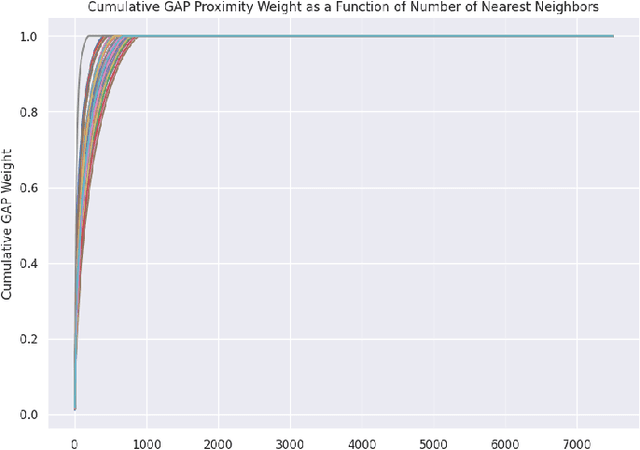
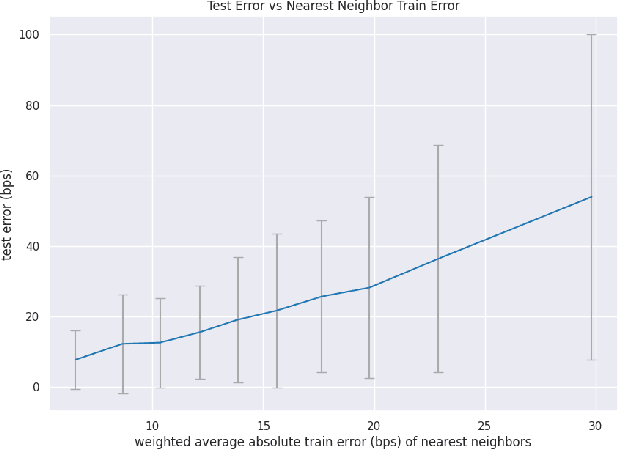
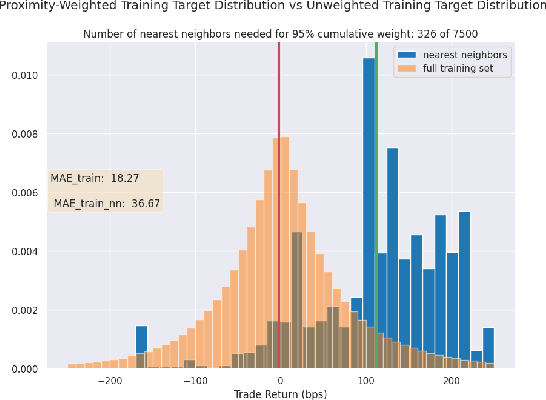
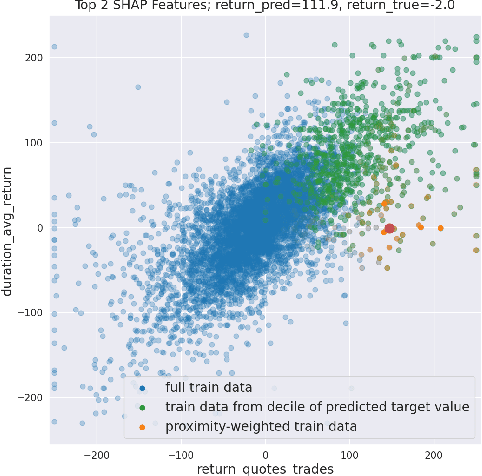
We initiate a novel approach to explain the out of sample performance of random forest (RF) models by exploiting the fact that any RF can be formulated as an adaptive weighted K nearest-neighbors model. Specifically, we use the proximity between points in the feature space learned by the RF to re-write random forest predictions exactly as a weighted average of the target labels of training data points. This linearity facilitates a local notion of explainability of RF predictions that generates attributions for any model prediction across observations in the training set, and thereby complements established methods like SHAP, which instead generates attributions for a model prediction across dimensions of the feature space. We demonstrate this approach in the context of a bond pricing model trained on US corporate bond trades, and compare our approach to various existing approaches to model explainability.
Towards reducing hallucination in extracting information from financial reports using Large Language Models
Oct 16, 2023
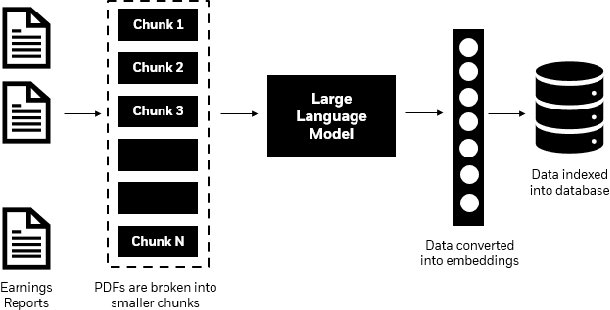

For a financial analyst, the question and answer (Q\&A) segment of the company financial report is a crucial piece of information for various analysis and investment decisions. However, extracting valuable insights from the Q\&A section has posed considerable challenges as the conventional methods such as detailed reading and note-taking lack scalability and are susceptible to human errors, and Optical Character Recognition (OCR) and similar techniques encounter difficulties in accurately processing unstructured transcript text, often missing subtle linguistic nuances that drive investor decisions. Here, we demonstrate the utilization of Large Language Models (LLMs) to efficiently and rapidly extract information from earnings report transcripts while ensuring high accuracy transforming the extraction process as well as reducing hallucination by combining retrieval-augmented generation technique as well as metadata. We evaluate the outcomes of various LLMs with and without using our proposed approach based on various objective metrics for evaluating Q\&A systems, and empirically demonstrate superiority of our method.