 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of DSPy Teleprompter Algorithms for Aligning Large Language Models Evaluation Metrics to Human Evaluation
Dec 19, 2024



We argue that the Declarative Self-improving Python (DSPy) optimizers are a way to align the large language model (LLM) prompts and their evaluations to the human annotations. We present a comparative analysis of five teleprompter algorithms, namely, Cooperative Prompt Optimization (COPRO), Multi-Stage Instruction Prompt Optimization (MIPRO), BootstrapFewShot, BootstrapFewShot with Optuna, and K-Nearest Neighbor Few Shot, within the DSPy framework with respect to their ability to align with human evaluations. As a concrete example, we focus on optimizing the prompt to align hallucination detection (using LLM as a judge) to human annotated ground truth labels for a publicly available benchmark dataset. Our experiments demonstrate that optimized prompts can outperform various benchmark methods to detect hallucination, and certain telemprompters outperform the others in at least these experiments.
Climate AI for Corporate Decarbonization Metrics Extraction
Nov 05, 2024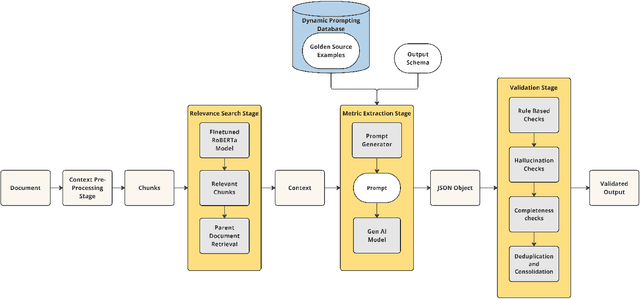

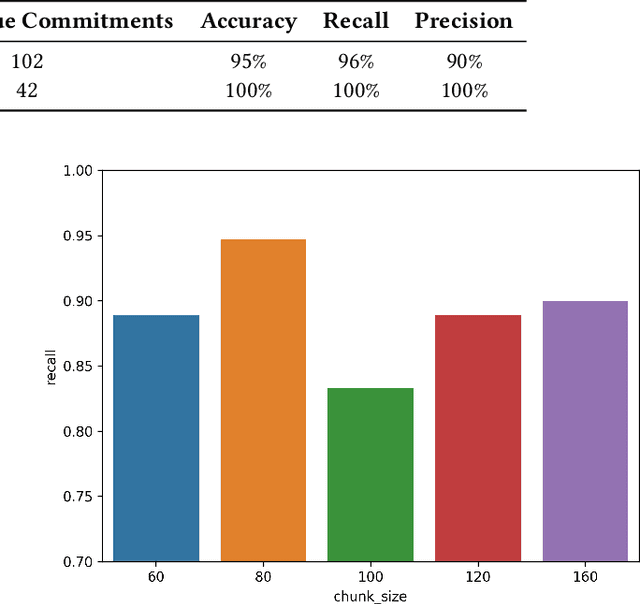

Corporate Greenhouse Gas (GHG) emission targets are important metrics in sustainable investing [12, 16]. To provide a comprehensive view of company emission objectives, we propose an approach to source these metrics from company public disclosures. Without automation, curating these metrics manually is a labor-intensive process that requires combing through lengthy corporate sustainability disclosures that often do not follow a standard format. Furthermore, the resulting dataset needs to be validated thoroughly by Subject Matter Experts (SMEs), further lengthening the time-to-market. We introduce the Climate Artificial Intelligence for Corporate Decarbonization Metrics Extraction (CAI) model and pipeline, a novel approach utilizing Large Language Models (LLMs) to extract and validate linked metrics from corporate disclosures. We demonstrate that the process improves data collection efficiency and accuracy by automating data curation, validation, and metric scoring from public corporate disclosures. We further show that our results are agnostic to the choice of LLMs. This framework can be applied broadly to information extraction from textual data.