 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReassessing the Role of Supervised Fine-Tuning: An Empirical Study in VLM Reasoning
Dec 14, 2025Recent advances in vision-language models (VLMs) reasoning have been largely attributed to the rise of reinforcement Learning (RL), which has shifted the community's focus away from the supervised fine-tuning (SFT) paradigm. Many studies suggest that introducing the SFT stage not only fails to improve reasoning ability but may also negatively impact model training. In this study, we revisit this RL-centric belief through a systematic and controlled comparison of SFT and RL on VLM Reasoning. Using identical data sources, we find that the relative effectiveness of SFT and RL is conditional and strongly influenced by model capacity, data scale, and data distribution. Contrary to common assumptions, our findings show that SFT plays a crucial role across several scenarios: (1) Effectiveness for weaker models. SFT more reliably elicits reasoning capabilities in smaller or weaker VLMs. (2) Data efficiency. SFT with only 2K achieves comparable or better reasoning performance to RL with 20K. (3) Cross-modal transferability. SFT demonstrates stronger generalization across modalities. Moreover, we identify a pervasive issue of deceptive rewards, where higher rewards fail to correlate with better reasoning accuracy in RL. These results challenge the prevailing "RL over SFT" narrative. They highlight that the role of SFT may have been underestimated and support a more balanced post-training pipeline in which SFT and RL function as complementary components.
Climate AI for Corporate Decarbonization Metrics Extraction
Nov 05, 2024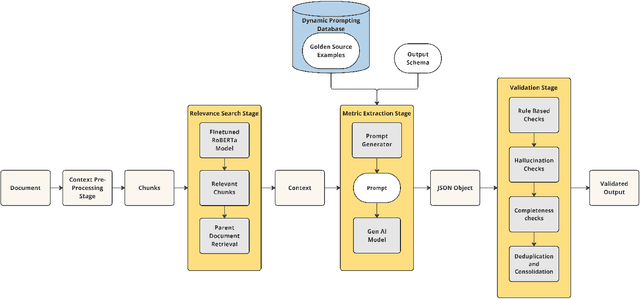

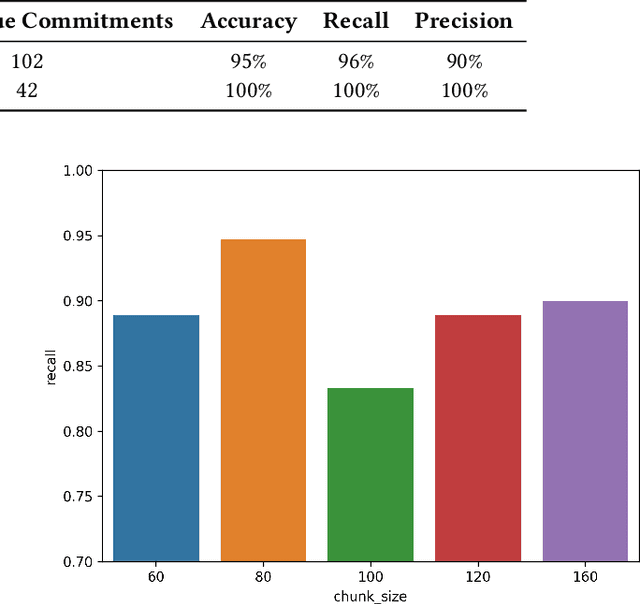

Corporate Greenhouse Gas (GHG) emission targets are important metrics in sustainable investing [12, 16]. To provide a comprehensive view of company emission objectives, we propose an approach to source these metrics from company public disclosures. Without automation, curating these metrics manually is a labor-intensive process that requires combing through lengthy corporate sustainability disclosures that often do not follow a standard format. Furthermore, the resulting dataset needs to be validated thoroughly by Subject Matter Experts (SMEs), further lengthening the time-to-market. We introduce the Climate Artificial Intelligence for Corporate Decarbonization Metrics Extraction (CAI) model and pipeline, a novel approach utilizing Large Language Models (LLMs) to extract and validate linked metrics from corporate disclosures. We demonstrate that the process improves data collection efficiency and accuracy by automating data curation, validation, and metric scoring from public corporate disclosures. We further show that our results are agnostic to the choice of LLMs. This framework can be applied broadly to information extraction from textual data.
PseudoCal: A Source-Free Approach to Unsupervised Uncertainty Calibration in Domain Adaptation
Jul 14, 2023



Unsupervised domain adaptation (UDA) has witnessed remarkable advancements in improving the accuracy of models for unlabeled target domains. However, the calibration of predictive uncertainty in the target domain, a crucial aspect of the safe deployment of UDA models, has received limited attention. The conventional in-domain calibration method, \textit{temperature scaling} (TempScal), encounters challenges due to domain distribution shifts and the absence of labeled target domain data. Recent approaches have employed importance-weighting techniques to estimate the target-optimal temperature based on re-weighted labeled source data. Nonetheless, these methods require source data and suffer from unreliable density estimates under severe domain shifts, rendering them unsuitable for source-free UDA settings. To overcome these limitations, we propose PseudoCal, a source-free calibration method that exclusively relies on unlabeled target data. Unlike previous approaches that treat UDA calibration as a \textit{covariate shift} problem, we consider it as an unsupervised calibration problem specific to the target domain. Motivated by the factorization of the negative log-likelihood (NLL) objective in TempScal, we generate a labeled pseudo-target set that captures the structure of the real target. By doing so, we transform the unsupervised calibration problem into a supervised one, enabling us to effectively address it using widely-used in-domain methods like TempScal. Finally, we thoroughly evaluate the calibration performance of PseudoCal by conducting extensive experiments on 10 UDA methods, considering both traditional UDA settings and recent source-free UDA scenarios. The experimental results consistently demonstrate the superior performance of PseudoCal, exhibiting significantly reduced calibration error compared to existing calibration methods.
UMAD: Universal Model Adaptation under Domain and Category Shift
Dec 16, 2021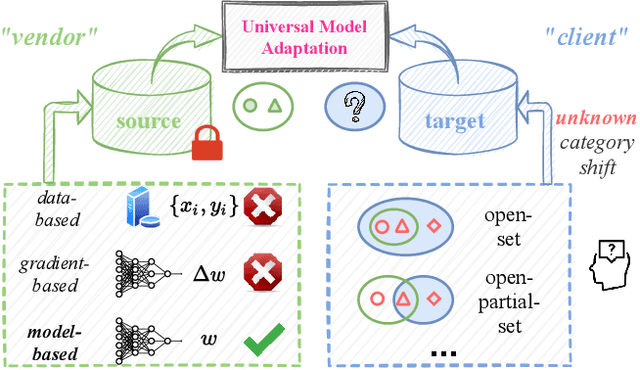
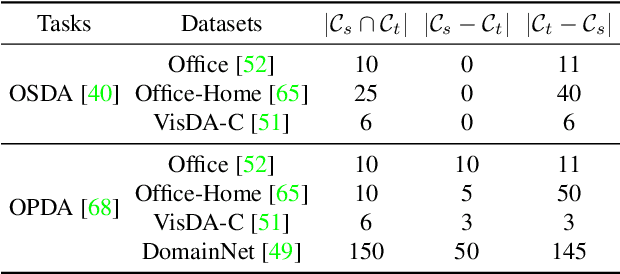
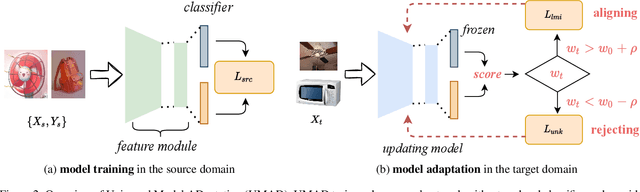
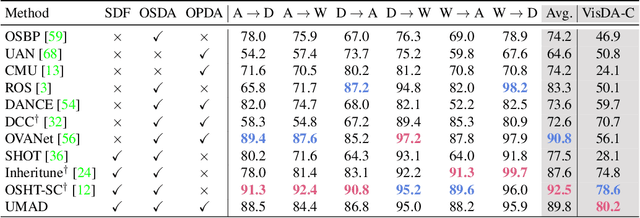
Learning to reject unknown samples (not present in the source classes) in the target domain is fairly important for unsupervised domain adaptation (UDA). There exist two typical UDA scenarios, i.e., open-set, and open-partial-set, and the latter assumes that not all source classes appear in the target domain. However, most prior methods are designed for one UDA scenario and always perform badly on the other UDA scenario. Moreover, they also require the labeled source data during adaptation, limiting their usability in data privacy-sensitive applications. To address these issues, this paper proposes a Universal Model ADaptation (UMAD) framework which handles both UDA scenarios without access to the source data nor prior knowledge about the category shift between domains. Specifically, we aim to learn a source model with an elegantly designed two-head classifier and provide it to the target domain. During adaptation, we develop an informative consistency score to help distinguish unknown samples from known samples. To achieve bilateral adaptation in the target domain, we further maximize localized mutual information to align known samples with the source classifier and employ an entropic loss to push unknown samples far away from the source classification boundary, respectively. Experiments on open-set and open-partial-set UDA scenarios demonstrate that UMAD, as a unified approach without access to source data, exhibits comparable, if not superior, performance to state-of-the-art data-dependent methods.
No Fear of Heterogeneity: Classifier Calibration for Federated Learning with Non-IID Data
Jun 09, 2021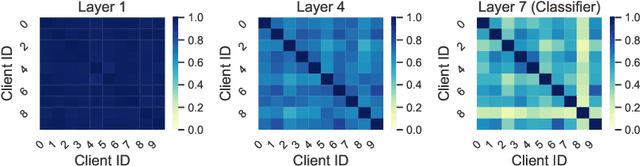

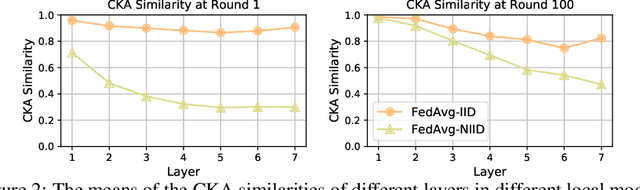
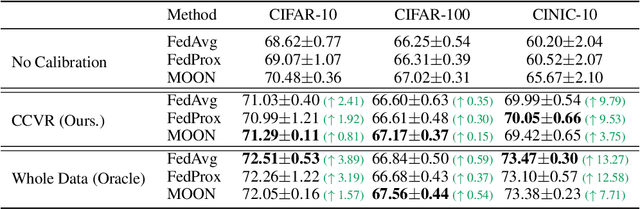
A central challenge in training classification models in the real-world federated system is learning with non-IID data. To cope with this, most of the existing works involve enforcing regularization in local optimization or improving the model aggregation scheme at the server. Other works also share public datasets or synthesized samples to supplement the training of under-represented classes or introduce a certain level of personalization. Though effective, they lack a deep understanding of how the data heterogeneity affects each layer of a deep classification model. In this paper, we bridge this gap by performing an experimental analysis of the representations learned by different layers. Our observations are surprising: (1) there exists a greater bias in the classifier than other layers, and (2) the classification performance can be significantly improved by post-calibrating the classifier after federated training. Motivated by the above findings, we propose a novel and simple algorithm called Classifier Calibration with Virtual Representations (CCVR), which adjusts the classifier using virtual representations sampled from an approximated gaussian mixture model. Experimental results demonstrate that CCVR achieves state-of-the-art performance on popular federated learning benchmarks including CIFAR-10, CIFAR-100, and CINIC-10. We hope that our simple yet effective method can shed some light on the future research of federated learning with non-IID data.
How Well Self-Supervised Pre-Training Performs with Streaming Data?
Apr 25, 2021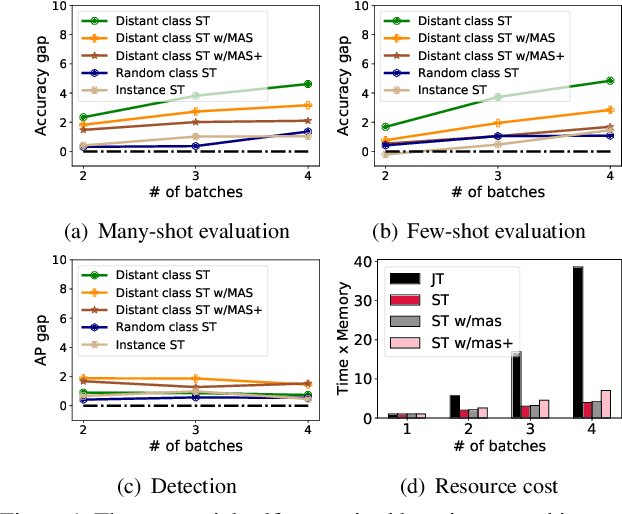
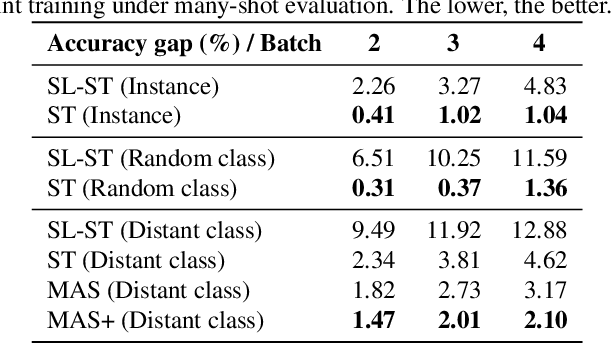
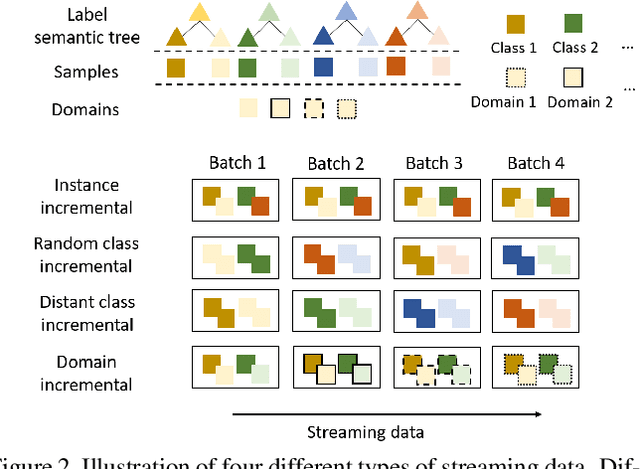
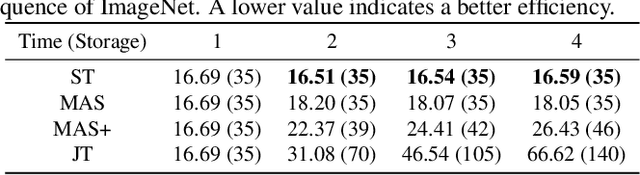
The common self-supervised pre-training practice requires collecting massive unlabeled data together and then trains a representation model, dubbed \textbf{joint training}. However, in real-world scenarios where data are collected in a streaming fashion, the joint training scheme is usually storage-heavy and time-consuming. A more efficient alternative is to train a model continually with streaming data, dubbed \textbf{sequential training}. Nevertheless, it is unclear how well sequential self-supervised pre-training performs with streaming data. In this paper, we conduct thorough experiments to investigate self-supervised pre-training with streaming data. Specifically, we evaluate the transfer performance of sequential self-supervised pre-training with four different data sequences on three different downstream tasks and make comparisons with joint self-supervised pre-training. Surprisingly, we find sequential self-supervised learning exhibits almost the same performance as the joint training when the distribution shifts within streaming data are mild. Even for data sequences with large distribution shifts, sequential self-supervised training with simple techniques, e.g., parameter regularization or data replay, still performs comparably to joint training. Based on our findings, we recommend using sequential self-supervised training as a \textbf{more efficient yet performance-competitive} representation learning practice for real-world applications.
Distill and Fine-tune: Effective Adaptation from a Black-box Source Model
Apr 04, 2021
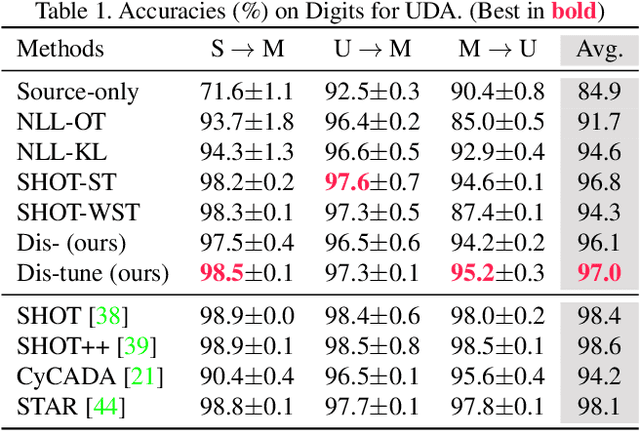
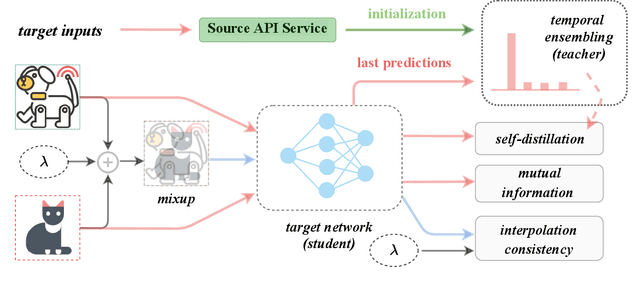
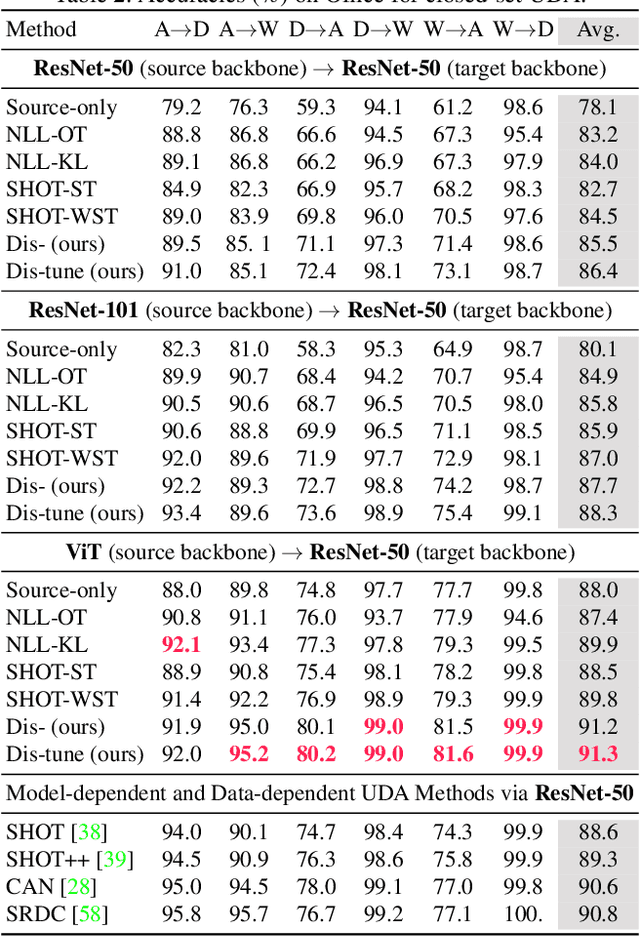
To alleviate the burden of labeling, unsupervised domain adaptation (UDA) aims to transfer knowledge in previous related labeled datasets (source) to a new unlabeled dataset (target). Despite impressive progress, prior methods always need to access the raw source data and develop data-dependent alignment approaches to recognize the target samples in a transductive learning manner, which may raise privacy concerns from source individuals. Several recent studies resort to an alternative solution by exploiting the well-trained white-box model instead of the raw data from the source domain, however, it may leak the raw data through generative adversarial training. This paper studies a practical and interesting setting for UDA, where only a black-box source model (i.e., only network predictions are available) is provided during adaptation in the target domain. Besides, different neural networks are even allowed to be employed for different domains. For this new problem, we propose a novel two-step adaptation framework called Distill and Fine-tune (Dis-tune). Specifically, Dis-tune first structurally distills the knowledge from the source model to a customized target model, then unsupervisedly fine-tunes the distilled model to fit the target domain. To verify the effectiveness, we consider two UDA scenarios (\ie, closed-set and partial-set), and discover that Dis-tune achieves highly competitive performance to state-of-the-art approaches.
Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning
Feb 12, 2021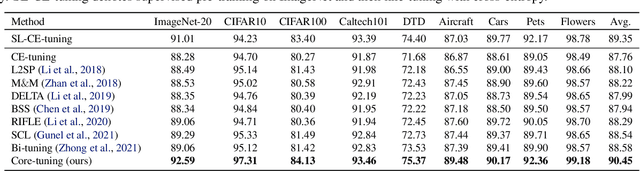


Contrastive self-supervised learning (CSL) leverages unlabeled data to train models that provide instance-discriminative visual representations uniformly scattered in the feature space. In deployment, the common practice is to directly fine-tune models with the cross-entropy loss, which however may not be an optimal strategy. Although cross-entropy tends to separate inter-class features, the resulted models still have limited capability of reducing intra-class feature scattering that inherits from pre-training, and thus may suffer unsatisfactory performance on downstream tasks. In this paper, we investigate whether applying contrastive learning to fine-tuning would bring further benefits, and analytically find that optimizing the supervised contrastive loss benefits both class-discriminative representation learning and model optimization during fine-tuning. Inspired by these findings, we propose Contrast-regularized tuning (Core-tuning), a novel approach for fine-tuning contrastive self-supervised visual models. Instead of simply adding the contrastive loss to the objective of fine-tuning, Core-tuning also generates hard sample pairs for more effective contrastive learning through a novel feature mixup strategy, as well as improves the generalizability of the model by smoothing the decision boundary via mixed samples. Extensive experiments on image classification and semantic segmentation verify the effectiveness of Core-tuning.
Source Data-absent Unsupervised Domain Adaptation through Hypothesis Transfer and Labeling Transfer
Dec 14, 2020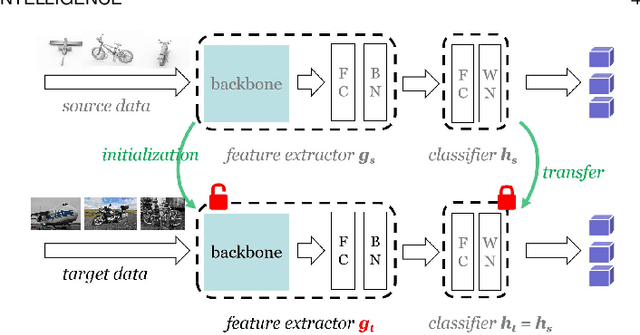
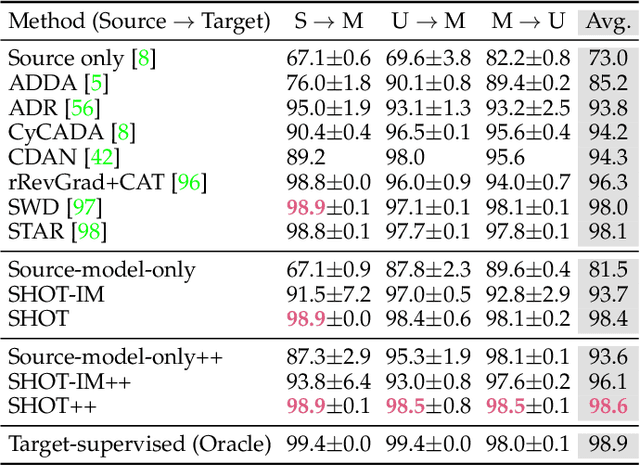
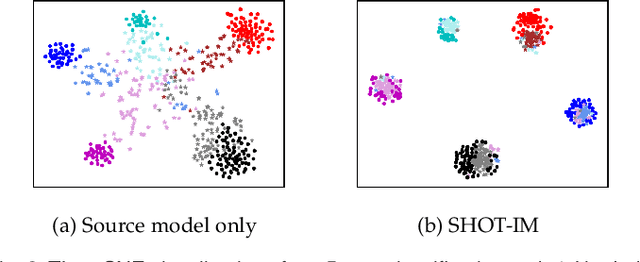

Unsupervised domain adaptation (UDA) aims to transfer knowledge from a related but different well-labeled source domain to a new unlabeled target domain. Most existing UDA methods require access to the source data, and thus are not applicable when the data are confidential and not shareable due to privacy concerns. This paper aims to tackle a realistic setting with only a classification model available trained over, instead of accessing to, the source data. To effectively utilize the source model for adaptation, we propose a novel approach called Source HypOthesis Transfer (SHOT), which learns the feature extraction module for the target domain by fitting the target data features to the frozen source classification module (representing classification hypothesis). Specifically, SHOT exploits both information maximization and self-supervised learning for the feature extraction module learning to ensure the target features are implicitly aligned with the features of unseen source data via the same hypothesis. Furthermore, we propose a new labeling transfer strategy, which separates the target data into two splits based on the confidence of predictions (labeling information), and then employ semi-supervised learning to improve the accuracy of less-confident predictions in the target domain. We denote labeling transfer as SHOT++ if the predictions are obtained by SHOT. Extensive experiments on both digit classification and object recognition tasks show that SHOT and SHOT++ achieve results surpassing or comparable to the state-of-the-arts, demonstrating the effectiveness of our approaches for various visual domain adaptation problems.
Combating Domain Shift with Self-Taught Labeling
Jul 08, 2020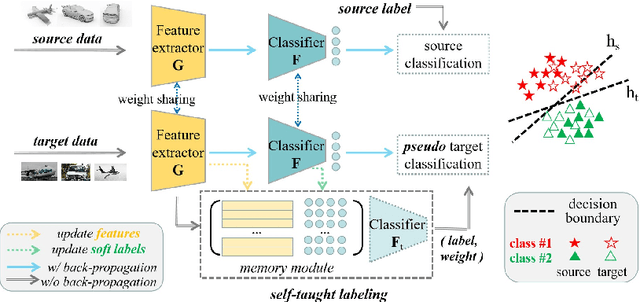
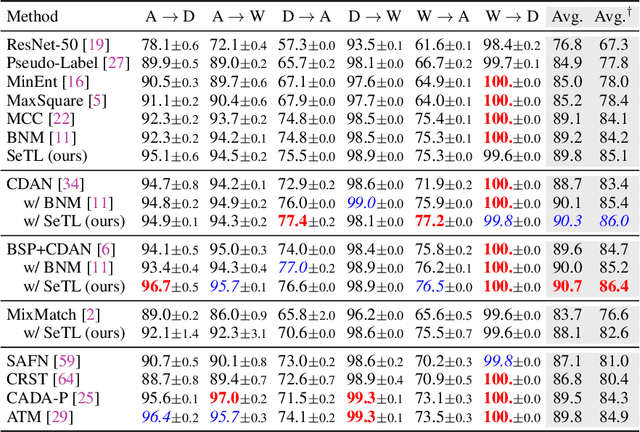
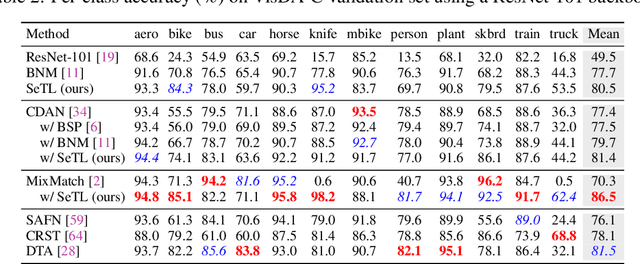
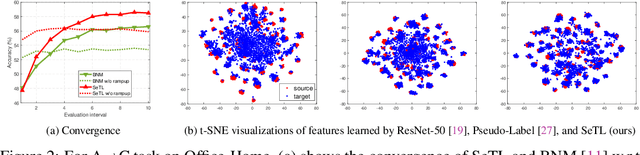
We present a novel method to combat domain shift when adapting classification models trained on one domain to other new domains with few or no target labels. In the existing literature, a prevailing solution paradigm is to learn domain-invariant feature representations so that a classifier learned on the source features generalizes well to the target features. However, such a classifier is inevitably biased to the source domain by overlooking the structure of the target data. Instead, we propose Self-Taught Labeling (SeTL), a new regularization approach that finds an auxiliary target-specific classifier for unlabeled data. During adaptation, this classifier is able to teach the target domain itself by providing \emph{unbiased accurate} pseudo labels. In particular, for each target data, we employ the memory bank to store the feature along with its soft label from the domain-shared classifier. Then we develop a non-parametric neighborhood aggregation strategy to generate new pseudo labels as well as confidence weights for unlabeled data. Though simply using the standard classification objective, SeTL significantly outperforms existing domain alignment techniques on a large variety of domain adaptation benchmarks. We expect that SeTL can provide a new perspective of addressing domain shift and inspire future research of domain adaptation and transfer learning.