 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning
Paper and Code
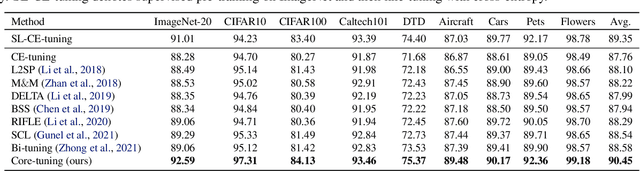

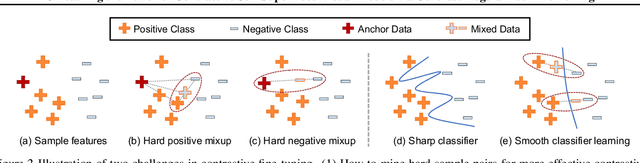

Contrastive self-supervised learning (CSL) leverages unlabeled data to train models that provide instance-discriminative visual representations uniformly scattered in the feature space. In deployment, the common practice is to directly fine-tune models with the cross-entropy loss, which however may not be an optimal strategy. Although cross-entropy tends to separate inter-class features, the resulted models still have limited capability of reducing intra-class feature scattering that inherits from pre-training, and thus may suffer unsatisfactory performance on downstream tasks. In this paper, we investigate whether applying contrastive learning to fine-tuning would bring further benefits, and analytically find that optimizing the supervised contrastive loss benefits both class-discriminative representation learning and model optimization during fine-tuning. Inspired by these findings, we propose Contrast-regularized tuning (Core-tuning), a novel approach for fine-tuning contrastive self-supervised visual models. Instead of simply adding the contrastive loss to the objective of fine-tuning, Core-tuning also generates hard sample pairs for more effective contrastive learning through a novel feature mixup strategy, as well as improves the generalizability of the model by smoothing the decision boundary via mixed samples. Extensive experiments on image classification and semantic segmentation verify the effectiveness of Core-tuning.