 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
Mar 19, 2026Visual generation with discrete tokens has gained significant attention as it enables a unified token prediction paradigm shared with language models, promising seamless multimodal architectures. However, current discrete generation methods remain limited to low-dimensional latent tokens (typically 8-32 dims), sacrificing the semantic richness essential for understanding. While high-dimensional pretrained representations (768-1024 dims) could bridge this gap, their discrete generation poses fundamental challenges. In this paper, we present Cubic Discrete Diffusion (CubiD), the first discrete generation model for high-dimensional representations. CubiD performs fine-grained masking throughout the high-dimensional discrete representation -- any dimension at any position can be masked and predicted from partial observations. This enables the model to learn rich correlations both within and across spatial positions, with the number of generation steps fixed at $T$ regardless of feature dimensionality, where $T \ll hwd$. On ImageNet-256, CubiD achieves state-of-the-art discrete generation with strong scaling behavior from 900M to 3.7B parameters. Crucially, we validate that these discretized tokens preserve original representation capabilities, demonstrating that the same discrete tokens can effectively serve both understanding and generation tasks. We hope this work will inspire future research toward unified multimodal architectures. Code is available at: https://github.com/YuqingWang1029/CubiD.
EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
Mar 12, 2026Autoregressive (AR) video generative models rely on video tokenizers that compress pixels into discrete token sequences. The length of these token sequences is crucial for balancing reconstruction quality against downstream generation computational cost. Traditional video tokenizers apply a uniform token assignment across temporal blocks of different videos, often wasting tokens on simple, static, or repetitive segments while underserving dynamic or complex ones. To address this inefficiency, we introduce $\textbf{EVATok}$, a framework to produce $\textbf{E}$fficient $\textbf{V}$ideo $\textbf{A}$daptive $\textbf{Tok}$enizers. Our framework estimates optimal token assignments for each video to achieve the best quality-cost trade-off, develops lightweight routers for fast prediction of these optimal assignments, and trains adaptive tokenizers that encode videos based on the assignments predicted by routers. We demonstrate that EVATok delivers substantial improvements in efficiency and overall quality for video reconstruction and downstream AR generation. Enhanced by our advanced training recipe that integrates video semantic encoders, EVATok achieves superior reconstruction and state-of-the-art class-to-video generation on UCF-101, with at least 24.4% savings in average token usage compared to the prior state-of-the-art LARP and our fixed-length baseline.
VideoWorld 2: Learning Transferable Knowledge from Real-world Videos
Feb 10, 2026Learning transferable knowledge from unlabeled video data and applying it in new environments is a fundamental capability of intelligent agents. This work presents VideoWorld 2, which extends VideoWorld and offers the first investigation into learning transferable knowledge directly from raw real-world videos. At its core, VideoWorld 2 introduces a dynamic-enhanced Latent Dynamics Model (dLDM) that decouples action dynamics from visual appearance: a pretrained video diffusion model handles visual appearance modeling, enabling the dLDM to learn latent codes that focus on compact and meaningful task-related dynamics. These latent codes are then modeled autoregressively to learn task policies and support long-horizon reasoning. We evaluate VideoWorld 2 on challenging real-world handcraft making tasks, where prior video generation and latent-dynamics models struggle to operate reliably. Remarkably, VideoWorld 2 achieves up to 70% improvement in task success rate and produces coherent long execution videos. In robotics, we show that VideoWorld 2 can acquire effective manipulation knowledge from the Open-X dataset, which substantially improves task performance on CALVIN. This study reveals the potential of learning transferable world knowledge directly from raw videos, with all code, data, and models to be open-sourced for further research.
SuperCLIP: CLIP with Simple Classification Supervision
Dec 16, 2025

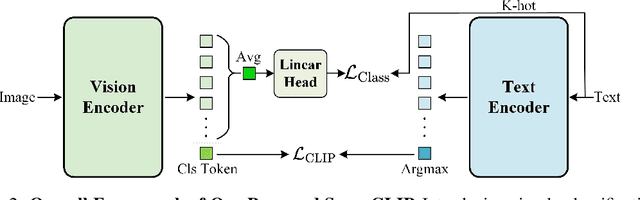
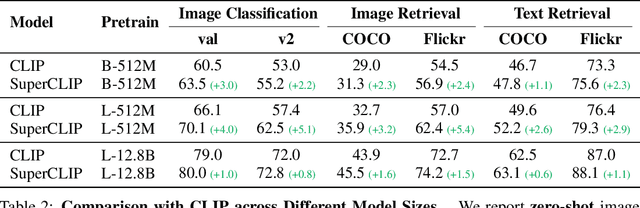
Contrastive Language-Image Pretraining (CLIP) achieves strong generalization in vision-language tasks by aligning images and texts in a shared embedding space. However, recent findings show that CLIP-like models still underutilize fine-grained semantic signals in text, and this issue becomes even more pronounced when dealing with long and detailed captions. This stems from CLIP's training objective, which optimizes only global image-text similarity and overlooks token-level supervision - limiting its ability to achieve fine-grained visual-text alignment. To address this, we propose SuperCLIP, a simple yet effective framework that augments contrastive learning with classification-based supervision. By adding only a lightweight linear layer to the vision encoder, SuperCLIP leverages token-level cues to enhance visual-textual alignment - with just a 0.077% increase in total FLOPs, and no need for additional annotated data. Experiments show that SuperCLIP consistently improves zero-shot classification, image-text retrieval, and purely visual tasks. These gains hold regardless of whether the model is trained on original web data or rich re-captioned data, demonstrating SuperCLIP's ability to recover textual supervision in both cases. Furthermore, SuperCLIP alleviates CLIP's small-batch performance drop through classification-based supervision that avoids reliance on large batch sizes. Code and models will be made open source.
Depth Anything 3: Recovering the Visual Space from Any Views
Nov 13, 2025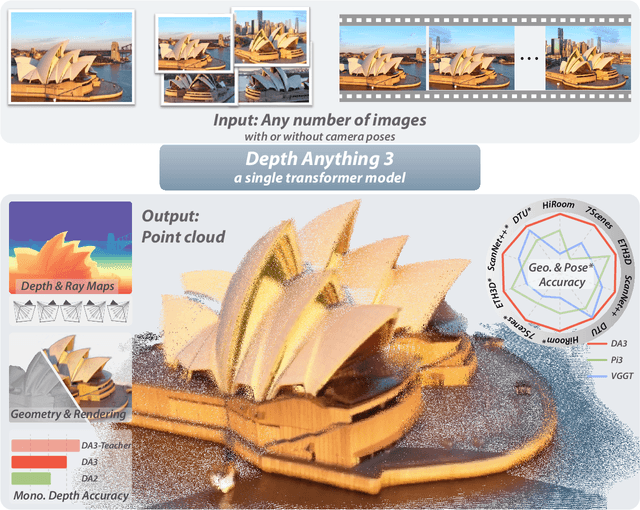
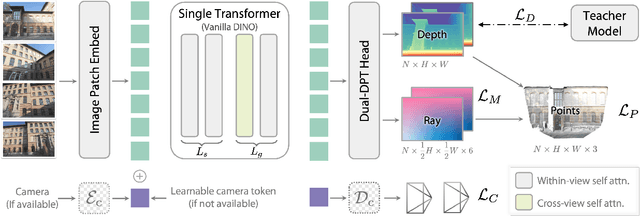
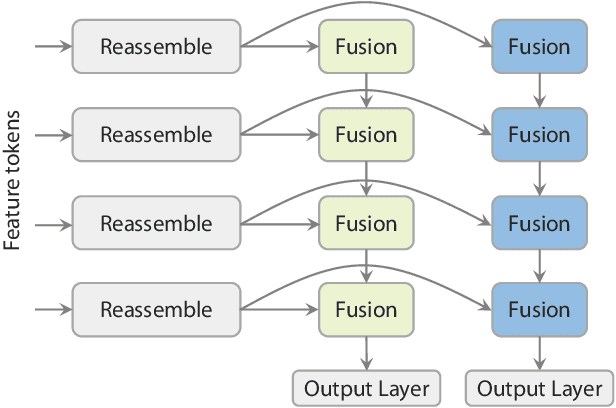
We present Depth Anything 3 (DA3), a model that predicts spatially consistent geometry from an arbitrary number of visual inputs, with or without known camera poses. In pursuit of minimal modeling, DA3 yields two key insights: a single plain transformer (e.g., vanilla DINO encoder) is sufficient as a backbone without architectural specialization, and a singular depth-ray prediction target obviates the need for complex multi-task learning. Through our teacher-student training paradigm, the model achieves a level of detail and generalization on par with Depth Anything 2 (DA2). We establish a new visual geometry benchmark covering camera pose estimation, any-view geometry and visual rendering. On this benchmark, DA3 sets a new state-of-the-art across all tasks, surpassing prior SOTA VGGT by an average of 44.3% in camera pose accuracy and 25.1% in geometric accuracy. Moreover, it outperforms DA2 in monocular depth estimation. All models are trained exclusively on public academic datasets.
Puppeteer: Rig and Animate Your 3D Models
Aug 14, 2025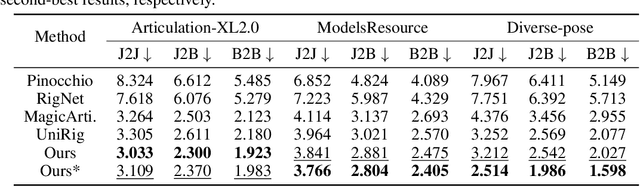

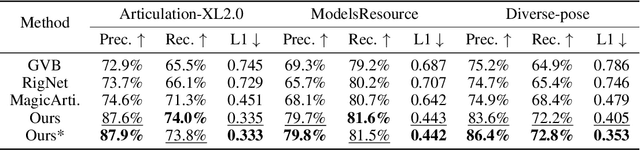

Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
Jul 10, 2025

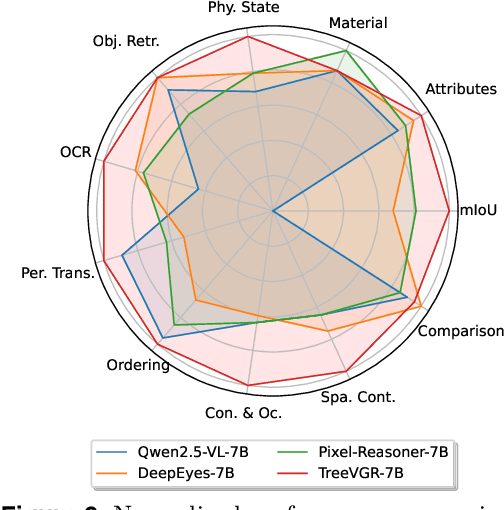
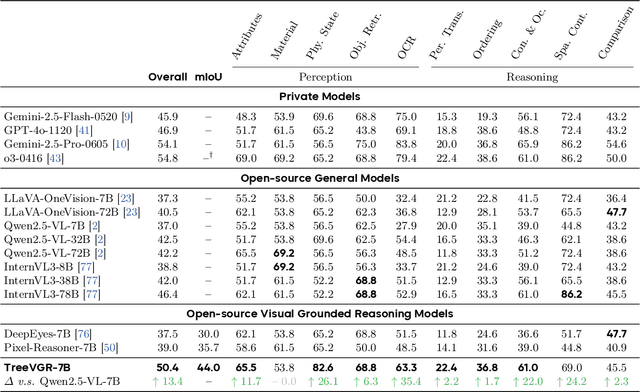
Models like OpenAI-o3 pioneer visual grounded reasoning by dynamically referencing visual regions, just like human "thinking with images". However, no benchmark exists to evaluate these capabilities holistically. To bridge this gap, we propose TreeBench (Traceable Evidence Evaluation Benchmark), a diagnostic benchmark built on three principles: (1) focused visual perception of subtle targets in complex scenes, (2) traceable evidence via bounding box evaluation, and (3) second-order reasoning to test object interactions and spatial hierarchies beyond simple object localization. Prioritizing images with dense objects, we initially sample 1K high-quality images from SA-1B, and incorporate eight LMM experts to manually annotate questions, candidate options, and answers for each image. After three stages of quality control, TreeBench consists of 405 challenging visual question-answering pairs, even the most advanced models struggle with this benchmark, where none of them reach 60% accuracy, e.g., OpenAI-o3 scores only 54.87. Furthermore, we introduce TreeVGR (Traceable Evidence Enhanced Visual Grounded Reasoning), a training paradigm to supervise localization and reasoning jointly with reinforcement learning, enabling accurate localizations and explainable reasoning pathways. Initialized from Qwen2.5-VL-7B, it improves V* Bench (+16.8), MME-RealWorld (+12.6), and TreeBench (+13.4), proving traceability is key to advancing vision-grounded reasoning. The code is available at https://github.com/Haochen-Wang409/TreeVGR.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Pixel-SAIL: Single Transformer For Pixel-Grounded Understanding
Apr 14, 2025



Multimodal Large Language Models (MLLMs) achieve remarkable performance for fine-grained pixel-level understanding tasks. However, all the works rely heavily on extra components, such as vision encoder (CLIP), segmentation experts, leading to high system complexity and limiting model scaling. In this work, our goal is to explore a highly simplified MLLM without introducing extra components. Our work is motivated by the recent works on Single trAnsformer as a unified vIsion-Language Model (SAIL) design, where these works jointly learn vision tokens and text tokens in transformers. We present Pixel-SAIL, a single transformer for pixel-wise MLLM tasks. In particular, we present three technical improvements on the plain baseline. First, we design a learnable upsampling module to refine visual token features. Secondly, we propose a novel visual prompt injection strategy to enable the single transformer to understand visual prompt inputs and benefit from the early fusion of visual prompt embeddings and vision tokens. Thirdly, we introduce a vision expert distillation strategy to efficiently enhance the single transformer's fine-grained feature extraction capability. In addition, we have collected a comprehensive pixel understanding benchmark (PerBench), using a manual check. It includes three tasks: detailed object description, visual prompt-based question answering, and visual-text referring segmentation. Extensive experiments on four referring segmentation benchmarks, one visual prompt benchmark, and our PerBench show that our Pixel-SAIL achieves comparable or even better results with a much simpler pipeline. Code and model will be released at https://github.com/magic-research/Sa2VA.
The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
Apr 14, 2025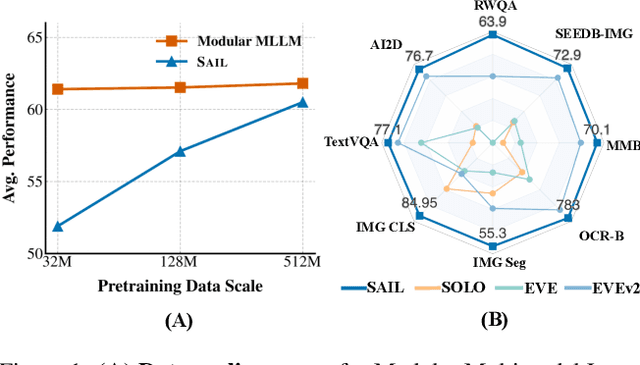
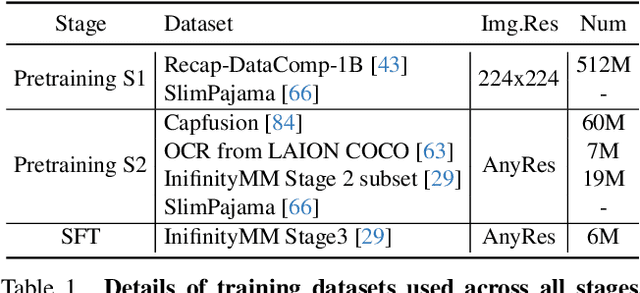
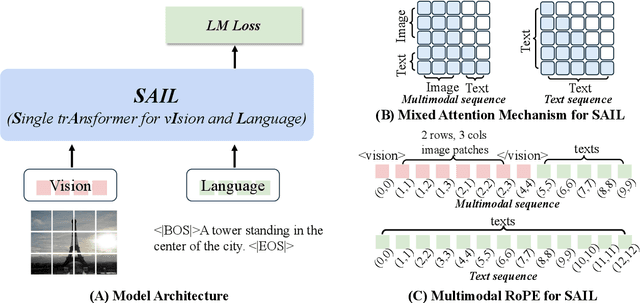
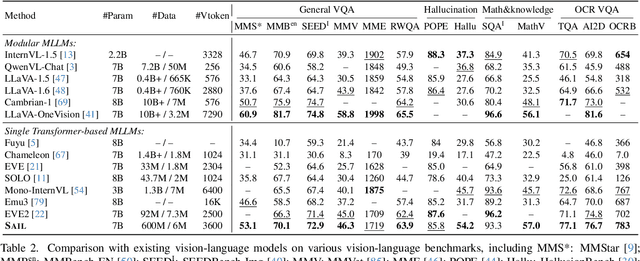
This paper introduces SAIL, a single transformer unified multimodal large language model (MLLM) that integrates raw pixel encoding and language decoding within a singular architecture. Unlike existing modular MLLMs, which rely on a pre-trained vision transformer (ViT), SAIL eliminates the need for a separate vision encoder, presenting a more minimalist architecture design. Instead of introducing novel architectural components, SAIL adapts mix-attention mechanisms and multimodal positional encodings to better align with the distinct characteristics of visual and textual modalities. We systematically compare SAIL's properties-including scalability, cross-modal information flow patterns, and visual representation capabilities-with those of modular MLLMs. By scaling both training data and model size, SAIL achieves performance comparable to modular MLLMs. Notably, the removal of pretrained ViT components enhances SAIL's scalability and results in significantly different cross-modal information flow patterns. Moreover, SAIL demonstrates strong visual representation capabilities, achieving results on par with ViT-22B in vision tasks such as semantic segmentation. Code and models are available at https://github.com/bytedance/SAIL.