 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Depth Anything 3: Recovering the Visual Space from Any Views
Nov 13, 2025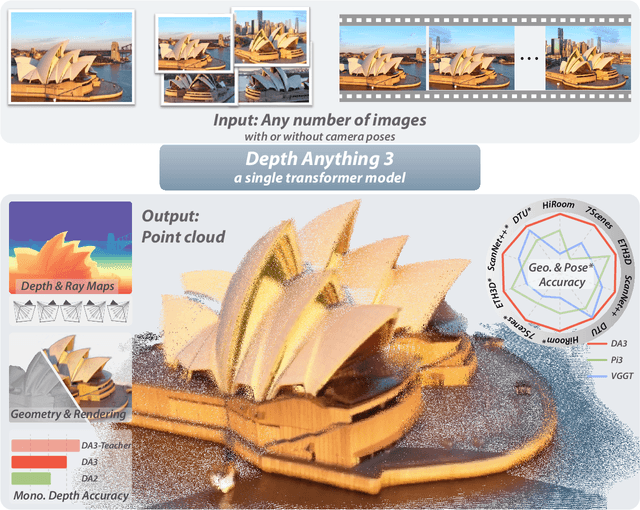
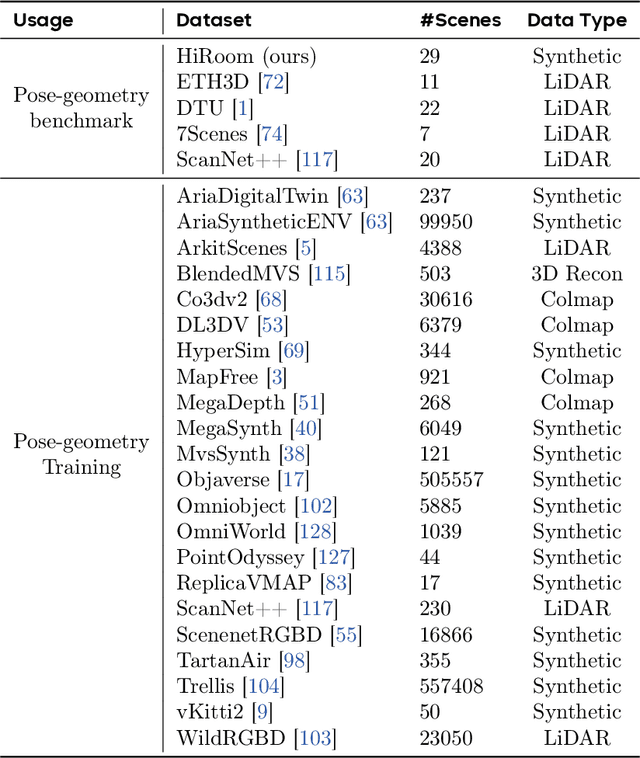
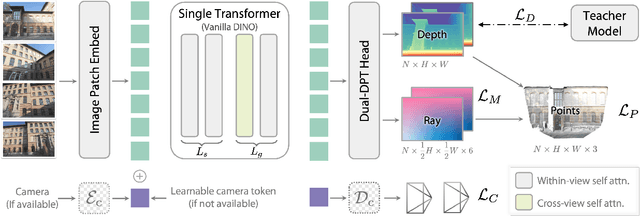
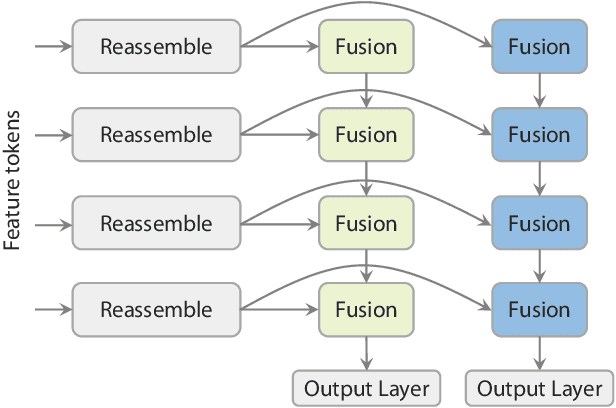
We present Depth Anything 3 (DA3), a model that predicts spatially consistent geometry from an arbitrary number of visual inputs, with or without known camera poses. In pursuit of minimal modeling, DA3 yields two key insights: a single plain transformer (e.g., vanilla DINO encoder) is sufficient as a backbone without architectural specialization, and a singular depth-ray prediction target obviates the need for complex multi-task learning. Through our teacher-student training paradigm, the model achieves a level of detail and generalization on par with Depth Anything 2 (DA2). We establish a new visual geometry benchmark covering camera pose estimation, any-view geometry and visual rendering. On this benchmark, DA3 sets a new state-of-the-art across all tasks, surpassing prior SOTA VGGT by an average of 44.3% in camera pose accuracy and 25.1% in geometric accuracy. Moreover, it outperforms DA2 in monocular depth estimation. All models are trained exclusively on public academic datasets.
Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
Jan 21, 2025Depth Anything has achieved remarkable success in monocular depth estimation with strong generalization ability. However, it suffers from temporal inconsistency in videos, hindering its practical applications. Various methods have been proposed to alleviate this issue by leveraging video generation models or introducing priors from optical flow and camera poses. Nonetheless, these methods are only applicable to short videos (< 10 seconds) and require a trade-off between quality and computational efficiency. We propose Video Depth Anything for high-quality, consistent depth estimation in super-long videos (over several minutes) without sacrificing efficiency. We base our model on Depth Anything V2 and replace its head with an efficient spatial-temporal head. We design a straightforward yet effective temporal consistency loss by constraining the temporal depth gradient, eliminating the need for additional geometric priors. The model is trained on a joint dataset of video depth and unlabeled images, similar to Depth Anything V2. Moreover, a novel key-frame-based strategy is developed for long video inference. Experiments show that our model can be applied to arbitrarily long videos without compromising quality, consistency, or generalization ability. Comprehensive evaluations on multiple video benchmarks demonstrate that our approach sets a new state-of-the-art in zero-shot video depth estimation. We offer models of different scales to support a range of scenarios, with our smallest model capable of real-time performance at 30 FPS.
MonoPlane: Exploiting Monocular Geometric Cues for Generalizable 3D Plane Reconstruction
Nov 02, 2024
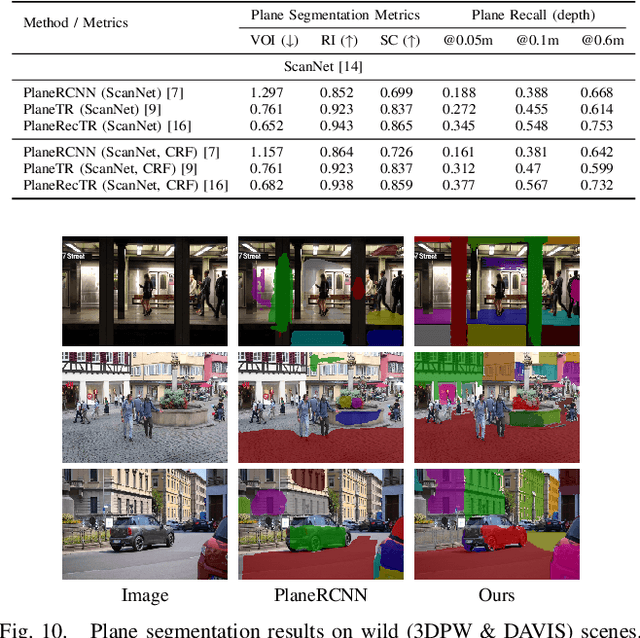


This paper presents a generalizable 3D plane detection and reconstruction framework named MonoPlane. Unlike previous robust estimator-based works (which require multiple images or RGB-D input) and learning-based works (which suffer from domain shift), MonoPlane combines the best of two worlds and establishes a plane reconstruction pipeline based on monocular geometric cues, resulting in accurate, robust and scalable 3D plane detection and reconstruction in the wild. Specifically, we first leverage large-scale pre-trained neural networks to obtain the depth and surface normals from a single image. These monocular geometric cues are then incorporated into a proximity-guided RANSAC framework to sequentially fit each plane instance. We exploit effective 3D point proximity and model such proximity via a graph within RANSAC to guide the plane fitting from noisy monocular depths, followed by image-level multi-plane joint optimization to improve the consistency among all plane instances. We further design a simple but effective pipeline to extend this single-view solution to sparse-view 3D plane reconstruction. Extensive experiments on a list of datasets demonstrate our superior zero-shot generalizability over baselines, achieving state-of-the-art plane reconstruction performance in a transferring setting. Our code is available at https://github.com/thuzhaowang/MonoPlane .
Noise-resistant Deep Learning for Object Classification in 3D Point Clouds Using a Point Pair Descriptor
Apr 05, 2018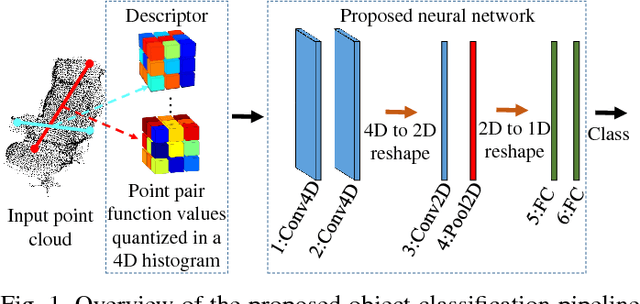
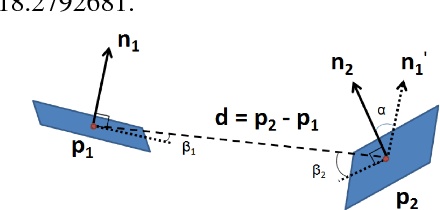
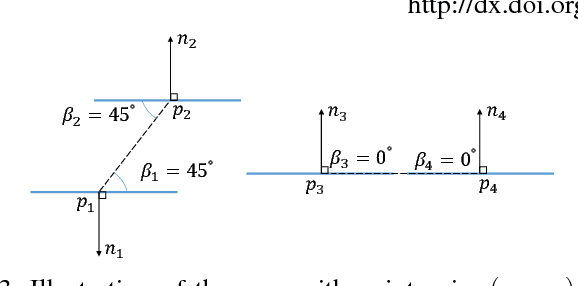
Object retrieval and classification in point cloud data is challenged by noise, irregular sampling density and occlusion. To address this issue, we propose a point pair descriptor that is robust to noise and occlusion and achieves high retrieval accuracy. We further show how the proposed descriptor can be used in a 4D convolutional neural network for the task of object classification. We propose a novel 4D convolutional layer that is able to learn class-specific clusters in the descriptor histograms. Finally, we provide experimental validation on 3 benchmark datasets, which confirms the superiority of the proposed approach.
* 8 pages