 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStdGEN++: A Comprehensive System for Semantic-Decomposed 3D Character Generation
Jan 12, 2026We present StdGEN++, a novel and comprehensive system for generating high-fidelity, semantically decomposed 3D characters from diverse inputs. Existing 3D generative methods often produce monolithic meshes that lack the structural flexibility required by industrial pipelines in gaming and animation. Addressing this gap, StdGEN++ is built upon a Dual-branch Semantic-aware Large Reconstruction Model (Dual-Branch S-LRM), which jointly reconstructs geometry, color, and per-component semantics in a feed-forward manner. To achieve production-level fidelity, we introduce a novel semantic surface extraction formalism compatible with hybrid implicit fields. This mechanism is accelerated by a coarse-to-fine proposal scheme, which significantly reduces memory footprint and enables high-resolution mesh generation. Furthermore, we propose a video-diffusion-based texture decomposition module that disentangles appearance into editable layers (e.g., separated iris and skin), resolving semantic confusion in facial regions. Experiments demonstrate that StdGEN++ achieves state-of-the-art performance, significantly outperforming existing methods in geometric accuracy and semantic disentanglement. Crucially, the resulting structural independence unlocks advanced downstream capabilities, including non-destructive editing, physics-compliant animation, and gaze tracking, making it a robust solution for automated character asset production.
DepthSync: Diffusion Guidance-Based Depth Synchronization for Scale- and Geometry-Consistent Video Depth Estimation
Jul 02, 2025
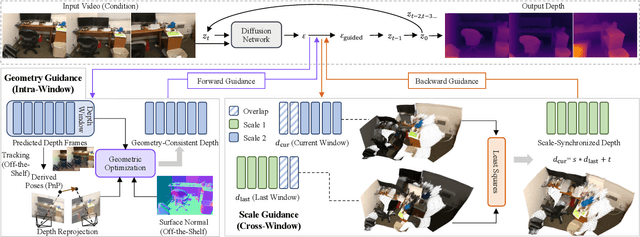

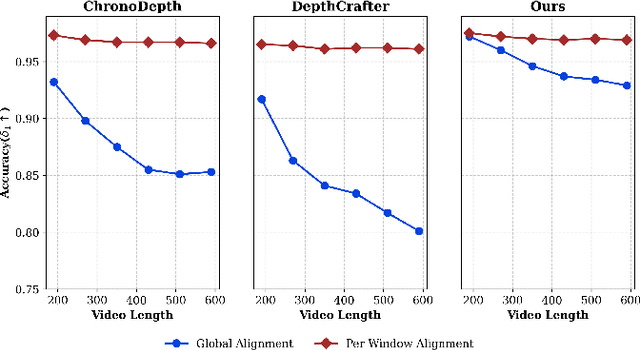
Diffusion-based video depth estimation methods have achieved remarkable success with strong generalization ability. However, predicting depth for long videos remains challenging. Existing methods typically split videos into overlapping sliding windows, leading to accumulated scale discrepancies across different windows, particularly as the number of windows increases. Additionally, these methods rely solely on 2D diffusion priors, overlooking the inherent 3D geometric structure of video depths, which results in geometrically inconsistent predictions. In this paper, we propose DepthSync, a novel, training-free framework using diffusion guidance to achieve scale- and geometry-consistent depth predictions for long videos. Specifically, we introduce scale guidance to synchronize the depth scale across windows and geometry guidance to enforce geometric alignment within windows based on the inherent 3D constraints in video depths. These two terms work synergistically, steering the denoising process toward consistent depth predictions. Experiments on various datasets validate the effectiveness of our method in producing depth estimates with improved scale and geometry consistency, particularly for long videos.
DI-PCG: Diffusion-based Efficient Inverse Procedural Content Generation for High-quality 3D Asset Creation
Dec 19, 2024



Procedural Content Generation (PCG) is powerful in creating high-quality 3D contents, yet controlling it to produce desired shapes is difficult and often requires extensive parameter tuning. Inverse Procedural Content Generation aims to automatically find the best parameters under the input condition. However, existing sampling-based and neural network-based methods still suffer from numerous sample iterations or limited controllability. In this work, we present DI-PCG, a novel and efficient method for Inverse PCG from general image conditions. At its core is a lightweight diffusion transformer model, where PCG parameters are directly treated as the denoising target and the observed images as conditions to control parameter generation. DI-PCG is efficient and effective. With only 7.6M network parameters and 30 GPU hours to train, it demonstrates superior performance in recovering parameters accurately, and generalizing well to in-the-wild images. Quantitative and qualitative experiment results validate the effectiveness of DI-PCG in inverse PCG and image-to-3D generation tasks. DI-PCG offers a promising approach for efficient inverse PCG and represents a valuable exploration step towards a 3D generation path that models how to construct a 3D asset using parametric models.
AlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos
Nov 29, 2024



We introduce AlphaTablets, a novel and generic representation of 3D planes that features continuous 3D surface and precise boundary delineation. By representing 3D planes as rectangles with alpha channels, AlphaTablets combine the advantages of current 2D and 3D plane representations, enabling accurate, consistent and flexible modeling of 3D planes. We derive differentiable rasterization on top of AlphaTablets to efficiently render 3D planes into images, and propose a novel bottom-up pipeline for 3D planar reconstruction from monocular videos. Starting with 2D superpixels and geometric cues from pre-trained models, we initialize 3D planes as AlphaTablets and optimize them via differentiable rendering. An effective merging scheme is introduced to facilitate the growth and refinement of AlphaTablets. Through iterative optimization and merging, we reconstruct complete and accurate 3D planes with solid surfaces and clear boundaries. Extensive experiments on the ScanNet dataset demonstrate state-of-the-art performance in 3D planar reconstruction, underscoring the great potential of AlphaTablets as a generic 3D plane representation for various applications. Project page is available at: https://hyzcluster.github.io/alphatablets
StdGEN: Semantic-Decomposed 3D Character Generation from Single Images
Nov 08, 2024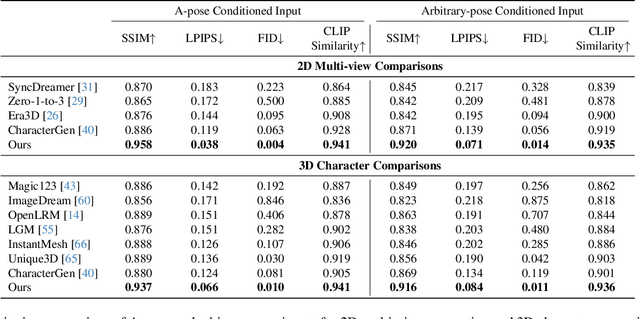
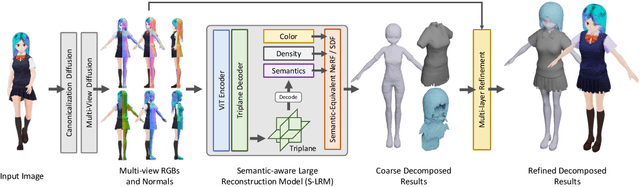
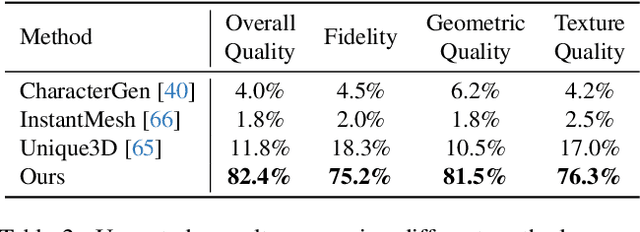
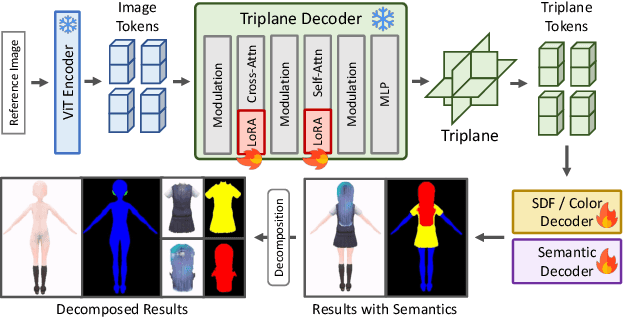
We present StdGEN, an innovative pipeline for generating semantically decomposed high-quality 3D characters from single images, enabling broad applications in virtual reality, gaming, and filmmaking, etc. Unlike previous methods which struggle with limited decomposability, unsatisfactory quality, and long optimization times, StdGEN features decomposability, effectiveness and efficiency; i.e., it generates intricately detailed 3D characters with separated semantic components such as the body, clothes, and hair, in three minutes. At the core of StdGEN is our proposed Semantic-aware Large Reconstruction Model (S-LRM), a transformer-based generalizable model that jointly reconstructs geometry, color and semantics from multi-view images in a feed-forward manner. A differentiable multi-layer semantic surface extraction scheme is introduced to acquire meshes from hybrid implicit fields reconstructed by our S-LRM. Additionally, a specialized efficient multi-view diffusion model and an iterative multi-layer surface refinement module are integrated into the pipeline to facilitate high-quality, decomposable 3D character generation. Extensive experiments demonstrate our state-of-the-art performance in 3D anime character generation, surpassing existing baselines by a significant margin in geometry, texture and decomposability. StdGEN offers ready-to-use semantic-decomposed 3D characters and enables flexible customization for a wide range of applications. Project page: https://stdgen.github.io
MonoPlane: Exploiting Monocular Geometric Cues for Generalizable 3D Plane Reconstruction
Nov 02, 2024
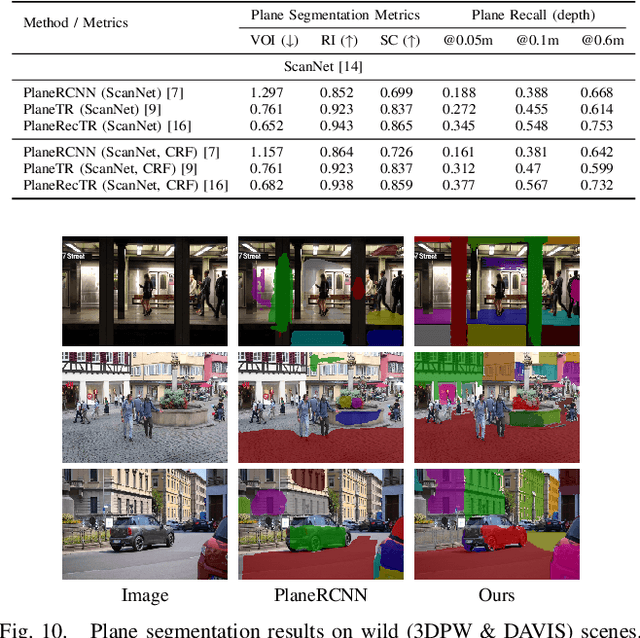


This paper presents a generalizable 3D plane detection and reconstruction framework named MonoPlane. Unlike previous robust estimator-based works (which require multiple images or RGB-D input) and learning-based works (which suffer from domain shift), MonoPlane combines the best of two worlds and establishes a plane reconstruction pipeline based on monocular geometric cues, resulting in accurate, robust and scalable 3D plane detection and reconstruction in the wild. Specifically, we first leverage large-scale pre-trained neural networks to obtain the depth and surface normals from a single image. These monocular geometric cues are then incorporated into a proximity-guided RANSAC framework to sequentially fit each plane instance. We exploit effective 3D point proximity and model such proximity via a graph within RANSAC to guide the plane fitting from noisy monocular depths, followed by image-level multi-plane joint optimization to improve the consistency among all plane instances. We further design a simple but effective pipeline to extend this single-view solution to sparse-view 3D plane reconstruction. Extensive experiments on a list of datasets demonstrate our superior zero-shot generalizability over baselines, achieving state-of-the-art plane reconstruction performance in a transferring setting. Our code is available at https://github.com/thuzhaowang/MonoPlane .
Tracking Everything in Robotic-Assisted Surgery
Sep 29, 2024Accurate tracking of tissues and instruments in videos is crucial for Robotic-Assisted Minimally Invasive Surgery (RAMIS), as it enables the robot to comprehend the surgical scene with precise locations and interactions of tissues and tools. Traditional keypoint-based sparse tracking is limited by featured points, while flow-based dense two-view matching suffers from long-term drifts. Recently, the Tracking Any Point (TAP) algorithm was proposed to overcome these limitations and achieve dense accurate long-term tracking. However, its efficacy in surgical scenarios remains untested, largely due to the lack of a comprehensive surgical tracking dataset for evaluation. To address this gap, we introduce a new annotated surgical tracking dataset for benchmarking tracking methods for surgical scenarios, comprising real-world surgical videos with complex tissue and instrument motions. We extensively evaluate state-of-the-art (SOTA) TAP-based algorithms on this dataset and reveal their limitations in challenging surgical scenarios, including fast instrument motion, severe occlusions, and motion blur, etc. Furthermore, we propose a new tracking method, namely SurgMotion, to solve the challenges and further improve the tracking performance. Our proposed method outperforms most TAP-based algorithms in surgical instruments tracking, and especially demonstrates significant improvements over baselines in challenging medical videos.
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Apr 18, 2024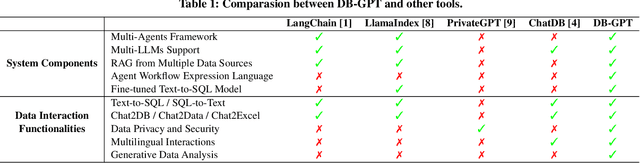
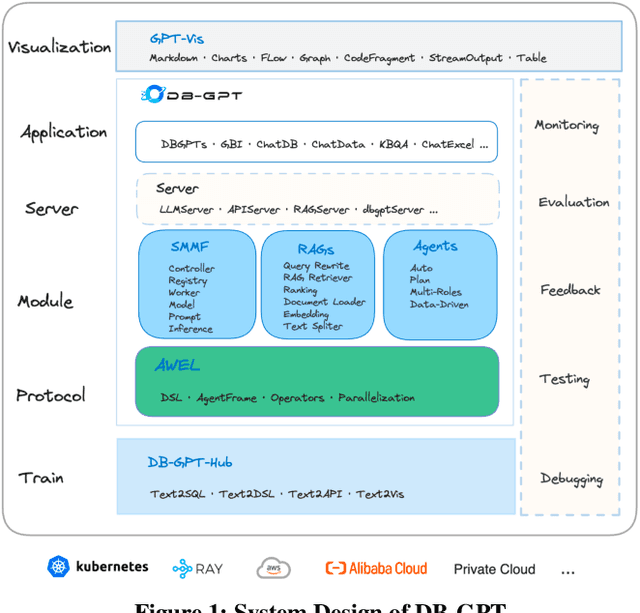

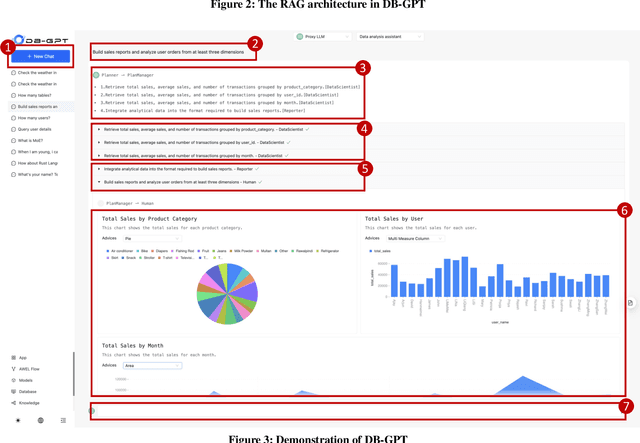
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
T$^3$Bench: Benchmarking Current Progress in Text-to-3D Generation
Oct 04, 2023Recent methods in text-to-3D leverage powerful pretrained diffusion models to optimize NeRF. Notably, these methods are able to produce high-quality 3D scenes without training on 3D data. Due to the open-ended nature of the task, most studies evaluate their results with subjective case studies and user experiments, thereby presenting a challenge in quantitatively addressing the question: How has current progress in Text-to-3D gone so far? In this paper, we introduce T$^3$Bench, the first comprehensive text-to-3D benchmark containing diverse text prompts of three increasing complexity levels that are specially designed for 3D generation. To assess both the subjective quality and the text alignment, we propose two automatic metrics based on multi-view images produced by the 3D contents. The quality metric combines multi-view text-image scores and regional convolution to detect quality and view inconsistency. The alignment metric uses multi-view captioning and Large Language Model (LLM) evaluation to measure text-3D consistency. Both metrics closely correlate with different dimensions of human judgments, providing a paradigm for efficiently evaluating text-to-3D models. The benchmarking results, shown in Fig. 1, reveal performance differences among six prevalent text-to-3D methods. Our analysis further highlights the common struggles for current methods on generating surroundings and multi-object scenes, as well as the bottleneck of leveraging 2D guidance for 3D generation. Our project page is available at: https://t3bench.com.
MMPI: a Flexible Radiance Field Representation by Multiple Multi-plane Images Blending
Sep 30, 2023This paper presents a flexible representation of neural radiance fields based on multi-plane images (MPI), for high-quality view synthesis of complex scenes. MPI with Normalized Device Coordinate (NDC) parameterization is widely used in NeRF learning for its simple definition, easy calculation, and powerful ability to represent unbounded scenes. However, existing NeRF works that adopt MPI representation for novel view synthesis can only handle simple forward-facing unbounded scenes, where the input cameras are all observing in similar directions with small relative translations. Hence, extending these MPI-based methods to more complex scenes like large-range or even 360-degree scenes is very challenging. In this paper, we explore the potential of MPI and show that MPI can synthesize high-quality novel views of complex scenes with diverse camera distributions and view directions, which are not only limited to simple forward-facing scenes. Our key idea is to encode the neural radiance field with multiple MPIs facing different directions and blend them with an adaptive blending operation. For each region of the scene, the blending operation gives larger blending weights to those advantaged MPIs with stronger local representation abilities while giving lower weights to those with weaker representation abilities. Such blending operation automatically modulates the multiple MPIs to appropriately represent the diverse local density and color information. Experiments on the KITTI dataset and ScanNet dataset demonstrate that our proposed MMPI synthesizes high-quality images from diverse camera pose distributions and is fast to train, outperforming the previous fast-training NeRF methods for novel view synthesis. Moreover, we show that MMPI can encode extremely long trajectories and produce novel view renderings, demonstrating its potential in applications like autonomous driving.