 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute Zero: Reinforced Self-play Reasoning with Zero Data
May 07, 2025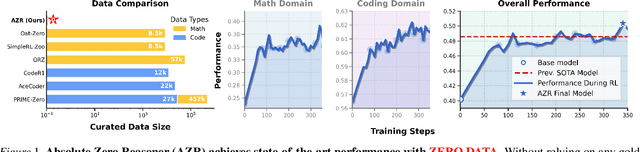
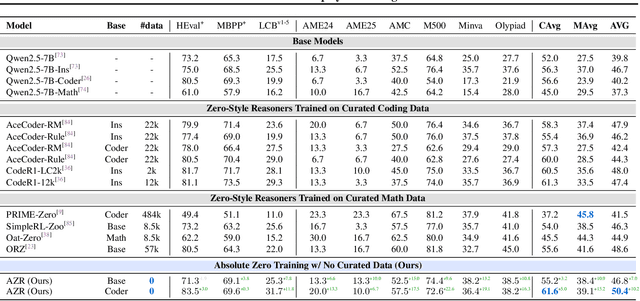

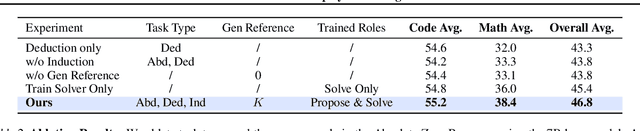
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
Tailor: An Integrated Text-Driven CG-Ready Human and Garment Generation System
Mar 15, 2025Creating detailed 3D human avatars with garments typically requires specialized expertise and labor-intensive processes. Although recent advances in generative AI have enabled text-to-3D human/clothing generation, current methods fall short in offering accessible, integrated pipelines for producing ready-to-use clothed avatars. To solve this, we introduce Tailor, an integrated text-to-avatar system that generates high-fidelity, customizable 3D humans with simulation-ready garments. Our system includes a three-stage pipeline. We first employ a large language model to interpret textual descriptions into parameterized body shapes and semantically matched garment templates. Next, we develop topology-preserving deformation with novel geometric losses to adapt garments precisely to body geometries. Furthermore, an enhanced texture diffusion module with a symmetric local attention mechanism ensures both view consistency and photorealistic details. Quantitative and qualitative evaluations demonstrate that Tailor outperforms existing SoTA methods in terms of fidelity, usability, and diversity. Code will be available for academic use.
Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction
Oct 29, 2024



Document parsing is essential for converting unstructured and semi-structured documents-such as contracts, academic papers, and invoices-into structured, machine-readable data. Document parsing extract reliable structured data from unstructured inputs, providing huge convenience for numerous applications. Especially with recent achievements in Large Language Models, document parsing plays an indispensable role in both knowledge base construction and training data generation. This survey presents a comprehensive review of the current state of document parsing, covering key methodologies, from modular pipeline systems to end-to-end models driven by large vision-language models. Core components such as layout detection, content extraction (including text, tables, and mathematical expressions), and multi-modal data integration are examined in detail. Additionally, this paper discusses the challenges faced by modular document parsing systems and vision-language models in handling complex layouts, integrating multiple modules, and recognizing high-density text. It emphasizes the importance of developing larger and more diverse datasets and outlines future research directions.
LLM-based Optimization of Compound AI Systems: A Survey
Oct 21, 2024

In a compound AI system, components such as an LLM call, a retriever, a code interpreter, or tools are interconnected. The system's behavior is primarily driven by parameters such as instructions or tool definitions. Recent advancements enable end-to-end optimization of these parameters using an LLM. Notably, leveraging an LLM as an optimizer is particularly efficient because it avoids gradient computation and can generate complex code and instructions. This paper presents a survey of the principles and emerging trends in LLM-based optimization of compound AI systems. It covers archetypes of compound AI systems, approaches to LLM-based end-to-end optimization, and insights into future directions and broader impacts. Importantly, this survey uses concepts from program analysis to provide a unified view of how an LLM optimizer is prompted to optimize a compound AI system. The exhaustive list of paper is provided at https://github.com/linyuhongg/LLM-based-Optimization-of-Compound-AI-Systems.
PVP-Recon: Progressive View Planning via Warping Consistency for Sparse-View Surface Reconstruction
Sep 09, 2024



Neural implicit representations have revolutionized dense multi-view surface reconstruction, yet their performance significantly diminishes with sparse input views. A few pioneering works have sought to tackle the challenge of sparse-view reconstruction by leveraging additional geometric priors or multi-scene generalizability. However, they are still hindered by the imperfect choice of input views, using images under empirically determined viewpoints to provide considerable overlap. We propose PVP-Recon, a novel and effective sparse-view surface reconstruction method that progressively plans the next best views to form an optimal set of sparse viewpoints for image capturing. PVP-Recon starts initial surface reconstruction with as few as 3 views and progressively adds new views which are determined based on a novel warping score that reflects the information gain of each newly added view. This progressive view planning progress is interleaved with a neural SDF-based reconstruction module that utilizes multi-resolution hash features, enhanced by a progressive training scheme and a directional Hessian loss. Quantitative and qualitative experiments on three benchmark datasets show that our framework achieves high-quality reconstruction with a constrained input budget and outperforms existing baselines.
DiveR-CT: Diversity-enhanced Red Teaming with Relaxing Constraints
May 29, 2024



Recent advances in large language models (LLMs) have made them indispensable, raising significant concerns over managing their safety. Automated red teaming offers a promising alternative to the labor-intensive and error-prone manual probing for vulnerabilities, providing more consistent and scalable safety evaluations. However, existing approaches often compromise diversity by focusing on maximizing attack success rate. Additionally, methods that decrease the cosine similarity from historical embeddings with semantic diversity rewards lead to novelty stagnation as history grows. To address these issues, we introduce DiveR-CT, which relaxes conventional constraints on the objective and semantic reward, granting greater freedom for the policy to enhance diversity. Our experiments demonstrate DiveR-CT's marked superiority over baselines by 1) generating data that perform better in various diversity metrics across different attack success rate levels, 2) better-enhancing resiliency in blue team models through safety tuning based on collected data, 3) allowing dynamic control of objective weights for reliable and controllable attack success rates, and 4) reducing susceptibility to reward overoptimization. Project details and code can be found at https://andrewzh112.github.io/#diverct.
Exploring Text-to-Motion Generation with Human Preference
Apr 15, 2024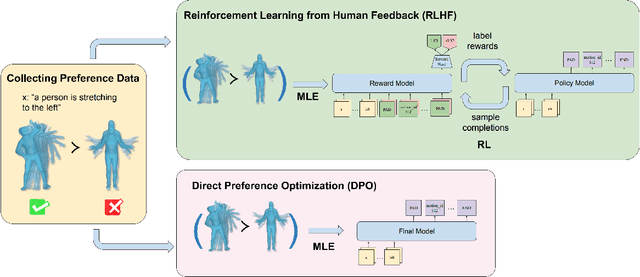

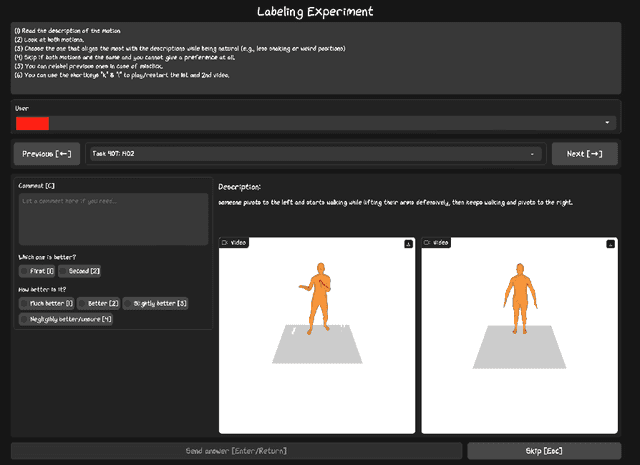

This paper presents an exploration of preference learning in text-to-motion generation. We find that current improvements in text-to-motion generation still rely on datasets requiring expert labelers with motion capture systems. Instead, learning from human preference data does not require motion capture systems; a labeler with no expertise simply compares two generated motions. This is particularly efficient because evaluating the model's output is easier than gathering the motion that performs a desired task (e.g. backflip). To pioneer the exploration of this paradigm, we annotate 3,528 preference pairs generated by MotionGPT, marking the first effort to investigate various algorithms for learning from preference data. In particular, our exploration highlights important design choices when using preference data. Additionally, our experimental results show that preference learning has the potential to greatly improve current text-to-motion generative models. Our code and dataset are publicly available at https://github.com/THU-LYJ-Lab/InstructMotion}{https://github.com/THU-LYJ-Lab/InstructMotion to further facilitate research in this area.
Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
Dec 19, 2023



By lifting the pre-trained 2D diffusion models into Neural Radiance Fields (NeRFs), text-to-3D generation methods have made great progress. Many state-of-the-art approaches usually apply score distillation sampling (SDS) to optimize the NeRF representations, which supervises the NeRF optimization with pre-trained text-conditioned 2D diffusion models such as Imagen. However, the supervision signal provided by such pre-trained diffusion models only depends on text prompts and does not constrain the multi-view consistency. To inject the cross-view consistency into diffusion priors, some recent works finetune the 2D diffusion model with multi-view data, but still lack fine-grained view coherence. To tackle this challenge, we incorporate multi-view image conditions into the supervision signal of NeRF optimization, which explicitly enforces fine-grained view consistency. With such stronger supervision, our proposed text-to-3D method effectively mitigates the generation of floaters (due to excessive densities) and completely empty spaces (due to insufficient densities). Our quantitative evaluations on the T$^3$Bench dataset demonstrate that our method achieves state-of-the-art performance over existing text-to-3D methods. We will make the code publicly available.
Augmenting Unsupervised Reinforcement Learning with Self-Reference
Nov 16, 2023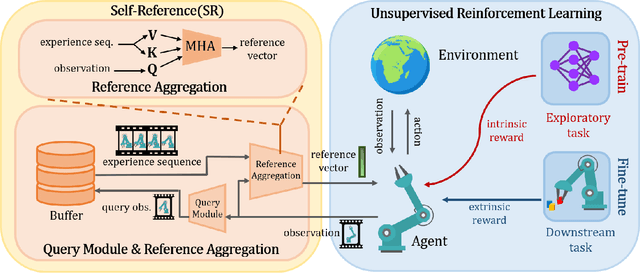
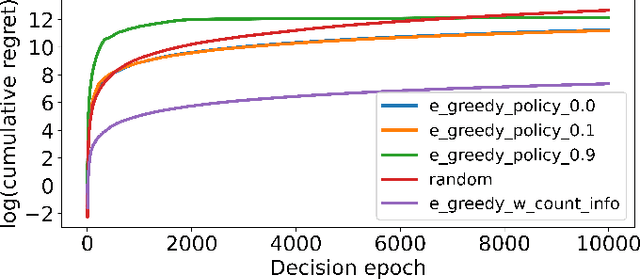
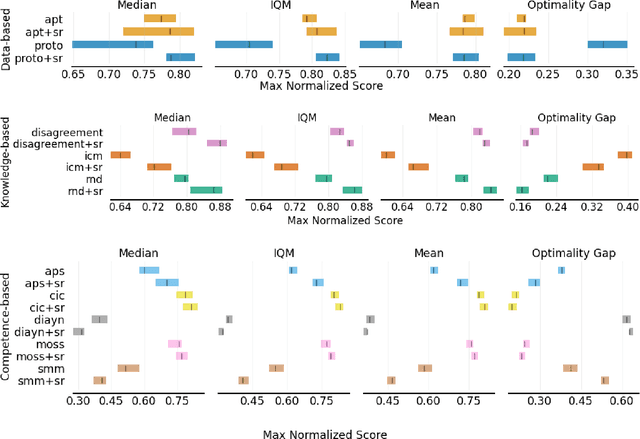
Humans possess the ability to draw on past experiences explicitly when learning new tasks and applying them accordingly. We believe this capacity for self-referencing is especially advantageous for reinforcement learning agents in the unsupervised pretrain-then-finetune setting. During pretraining, an agent's past experiences can be explicitly utilized to mitigate the nonstationarity of intrinsic rewards. In the finetuning phase, referencing historical trajectories prevents the unlearning of valuable exploratory behaviors. Motivated by these benefits, we propose the Self-Reference (SR) approach, an add-on module explicitly designed to leverage historical information and enhance agent performance within the pretrain-finetune paradigm. Our approach achieves state-of-the-art results in terms of Interquartile Mean (IQM) performance and Optimality Gap reduction on the Unsupervised Reinforcement Learning Benchmark for model-free methods, recording an 86% IQM and a 16% Optimality Gap. Additionally, it improves current algorithms by up to 17% IQM and reduces the Optimality Gap by 31%. Beyond performance enhancement, the Self-Reference add-on also increases sample efficiency, a crucial attribute for real-world applications.
T$^3$Bench: Benchmarking Current Progress in Text-to-3D Generation
Oct 04, 2023Recent methods in text-to-3D leverage powerful pretrained diffusion models to optimize NeRF. Notably, these methods are able to produce high-quality 3D scenes without training on 3D data. Due to the open-ended nature of the task, most studies evaluate their results with subjective case studies and user experiments, thereby presenting a challenge in quantitatively addressing the question: How has current progress in Text-to-3D gone so far? In this paper, we introduce T$^3$Bench, the first comprehensive text-to-3D benchmark containing diverse text prompts of three increasing complexity levels that are specially designed for 3D generation. To assess both the subjective quality and the text alignment, we propose two automatic metrics based on multi-view images produced by the 3D contents. The quality metric combines multi-view text-image scores and regional convolution to detect quality and view inconsistency. The alignment metric uses multi-view captioning and Large Language Model (LLM) evaluation to measure text-3D consistency. Both metrics closely correlate with different dimensions of human judgments, providing a paradigm for efficiently evaluating text-to-3D models. The benchmarking results, shown in Fig. 1, reveal performance differences among six prevalent text-to-3D methods. Our analysis further highlights the common struggles for current methods on generating surroundings and multi-object scenes, as well as the bottleneck of leveraging 2D guidance for 3D generation. Our project page is available at: https://t3bench.com.