 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos
Nov 29, 2024



We introduce AlphaTablets, a novel and generic representation of 3D planes that features continuous 3D surface and precise boundary delineation. By representing 3D planes as rectangles with alpha channels, AlphaTablets combine the advantages of current 2D and 3D plane representations, enabling accurate, consistent and flexible modeling of 3D planes. We derive differentiable rasterization on top of AlphaTablets to efficiently render 3D planes into images, and propose a novel bottom-up pipeline for 3D planar reconstruction from monocular videos. Starting with 2D superpixels and geometric cues from pre-trained models, we initialize 3D planes as AlphaTablets and optimize them via differentiable rendering. An effective merging scheme is introduced to facilitate the growth and refinement of AlphaTablets. Through iterative optimization and merging, we reconstruct complete and accurate 3D planes with solid surfaces and clear boundaries. Extensive experiments on the ScanNet dataset demonstrate state-of-the-art performance in 3D planar reconstruction, underscoring the great potential of AlphaTablets as a generic 3D plane representation for various applications. Project page is available at: https://hyzcluster.github.io/alphatablets
SS3DM: Benchmarking Street-View Surface Reconstruction with a Synthetic 3D Mesh Dataset
Oct 29, 2024


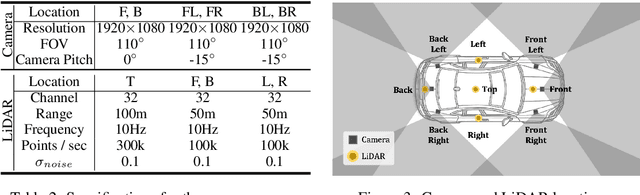
Reconstructing accurate 3D surfaces for street-view scenarios is crucial for applications such as digital entertainment and autonomous driving simulation. However, existing street-view datasets, including KITTI, Waymo, and nuScenes, only offer noisy LiDAR points as ground-truth data for geometric evaluation of reconstructed surfaces. These geometric ground-truths often lack the necessary precision to evaluate surface positions and do not provide data for assessing surface normals. To overcome these challenges, we introduce the SS3DM dataset, comprising precise \textbf{S}ynthetic \textbf{S}treet-view \textbf{3D} \textbf{M}esh models exported from the CARLA simulator. These mesh models facilitate accurate position evaluation and include normal vectors for evaluating surface normal. To simulate the input data in realistic driving scenarios for 3D reconstruction, we virtually drive a vehicle equipped with six RGB cameras and five LiDAR sensors in diverse outdoor scenes. Leveraging this dataset, we establish a benchmark for state-of-the-art surface reconstruction methods, providing a comprehensive evaluation of the associated challenges. For more information, visit our homepage at https://ss3dm.top.
PVP-Recon: Progressive View Planning via Warping Consistency for Sparse-View Surface Reconstruction
Sep 09, 2024



Neural implicit representations have revolutionized dense multi-view surface reconstruction, yet their performance significantly diminishes with sparse input views. A few pioneering works have sought to tackle the challenge of sparse-view reconstruction by leveraging additional geometric priors or multi-scene generalizability. However, they are still hindered by the imperfect choice of input views, using images under empirically determined viewpoints to provide considerable overlap. We propose PVP-Recon, a novel and effective sparse-view surface reconstruction method that progressively plans the next best views to form an optimal set of sparse viewpoints for image capturing. PVP-Recon starts initial surface reconstruction with as few as 3 views and progressively adds new views which are determined based on a novel warping score that reflects the information gain of each newly added view. This progressive view planning progress is interleaved with a neural SDF-based reconstruction module that utilizes multi-resolution hash features, enhanced by a progressive training scheme and a directional Hessian loss. Quantitative and qualitative experiments on three benchmark datasets show that our framework achieves high-quality reconstruction with a constrained input budget and outperforms existing baselines.
Gaussian in the Dark: Real-Time View Synthesis From Inconsistent Dark Images Using Gaussian Splatting
Aug 20, 2024



3D Gaussian Splatting has recently emerged as a powerful representation that can synthesize remarkable novel views using consistent multi-view images as input. However, we notice that images captured in dark environments where the scenes are not fully illuminated can exhibit considerable brightness variations and multi-view inconsistency, which poses great challenges to 3D Gaussian Splatting and severely degrades its performance. To tackle this problem, we propose Gaussian-DK. Observing that inconsistencies are mainly caused by camera imaging, we represent a consistent radiance field of the physical world using a set of anisotropic 3D Gaussians, and design a camera response module to compensate for multi-view inconsistencies. We also introduce a step-based gradient scaling strategy to constrain Gaussians near the camera, which turn out to be floaters, from splitting and cloning. Experiments on our proposed benchmark dataset demonstrate that Gaussian-DK produces high-quality renderings without ghosting and floater artifacts and significantly outperforms existing methods. Furthermore, we can also synthesize light-up images by controlling exposure levels that clearly show details in shadow areas.
NGP-RT: Fusing Multi-Level Hash Features with Lightweight Attention for Real-Time Novel View Synthesis
Jul 15, 2024



This paper presents NGP-RT, a novel approach for enhancing the rendering speed of Instant-NGP to achieve real-time novel view synthesis. As a classic NeRF-based method, Instant-NGP stores implicit features in multi-level grids or hash tables and applies a shallow MLP to convert the implicit features into explicit colors and densities. Although it achieves fast training speed, there is still a lot of room for improvement in its rendering speed due to the per-point MLP executions for implicit multi-level feature aggregation, especially for real-time applications. To address this challenge, our proposed NGP-RT explicitly stores colors and densities as hash features, and leverages a lightweight attention mechanism to disambiguate the hash collisions instead of using computationally intensive MLP. At the rendering stage, NGP-RT incorporates a pre-computed occupancy distance grid into the ray marching strategy to inform the distance to the nearest occupied voxel, thereby reducing the number of marching points and global memory access. Experimental results show that on the challenging Mip-NeRF360 dataset, NGP-RT achieves better rendering quality than previous NeRF-based methods, achieving 108 fps at 1080p resolution on a single Nvidia RTX 3090 GPU. Our approach is promising for NeRF-based real-time applications that require efficient and high-quality rendering.
Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
Dec 19, 2023



By lifting the pre-trained 2D diffusion models into Neural Radiance Fields (NeRFs), text-to-3D generation methods have made great progress. Many state-of-the-art approaches usually apply score distillation sampling (SDS) to optimize the NeRF representations, which supervises the NeRF optimization with pre-trained text-conditioned 2D diffusion models such as Imagen. However, the supervision signal provided by such pre-trained diffusion models only depends on text prompts and does not constrain the multi-view consistency. To inject the cross-view consistency into diffusion priors, some recent works finetune the 2D diffusion model with multi-view data, but still lack fine-grained view coherence. To tackle this challenge, we incorporate multi-view image conditions into the supervision signal of NeRF optimization, which explicitly enforces fine-grained view consistency. With such stronger supervision, our proposed text-to-3D method effectively mitigates the generation of floaters (due to excessive densities) and completely empty spaces (due to insufficient densities). Our quantitative evaluations on the T$^3$Bench dataset demonstrate that our method achieves state-of-the-art performance over existing text-to-3D methods. We will make the code publicly available.
T$^3$Bench: Benchmarking Current Progress in Text-to-3D Generation
Oct 04, 2023Recent methods in text-to-3D leverage powerful pretrained diffusion models to optimize NeRF. Notably, these methods are able to produce high-quality 3D scenes without training on 3D data. Due to the open-ended nature of the task, most studies evaluate their results with subjective case studies and user experiments, thereby presenting a challenge in quantitatively addressing the question: How has current progress in Text-to-3D gone so far? In this paper, we introduce T$^3$Bench, the first comprehensive text-to-3D benchmark containing diverse text prompts of three increasing complexity levels that are specially designed for 3D generation. To assess both the subjective quality and the text alignment, we propose two automatic metrics based on multi-view images produced by the 3D contents. The quality metric combines multi-view text-image scores and regional convolution to detect quality and view inconsistency. The alignment metric uses multi-view captioning and Large Language Model (LLM) evaluation to measure text-3D consistency. Both metrics closely correlate with different dimensions of human judgments, providing a paradigm for efficiently evaluating text-to-3D models. The benchmarking results, shown in Fig. 1, reveal performance differences among six prevalent text-to-3D methods. Our analysis further highlights the common struggles for current methods on generating surroundings and multi-object scenes, as well as the bottleneck of leveraging 2D guidance for 3D generation. Our project page is available at: https://t3bench.com.
MMPI: a Flexible Radiance Field Representation by Multiple Multi-plane Images Blending
Sep 30, 2023



This paper presents a flexible representation of neural radiance fields based on multi-plane images (MPI), for high-quality view synthesis of complex scenes. MPI with Normalized Device Coordinate (NDC) parameterization is widely used in NeRF learning for its simple definition, easy calculation, and powerful ability to represent unbounded scenes. However, existing NeRF works that adopt MPI representation for novel view synthesis can only handle simple forward-facing unbounded scenes, where the input cameras are all observing in similar directions with small relative translations. Hence, extending these MPI-based methods to more complex scenes like large-range or even 360-degree scenes is very challenging. In this paper, we explore the potential of MPI and show that MPI can synthesize high-quality novel views of complex scenes with diverse camera distributions and view directions, which are not only limited to simple forward-facing scenes. Our key idea is to encode the neural radiance field with multiple MPIs facing different directions and blend them with an adaptive blending operation. For each region of the scene, the blending operation gives larger blending weights to those advantaged MPIs with stronger local representation abilities while giving lower weights to those with weaker representation abilities. Such blending operation automatically modulates the multiple MPIs to appropriately represent the diverse local density and color information. Experiments on the KITTI dataset and ScanNet dataset demonstrate that our proposed MMPI synthesizes high-quality images from diverse camera pose distributions and is fast to train, outperforming the previous fast-training NeRF methods for novel view synthesis. Moreover, we show that MMPI can encode extremely long trajectories and produce novel view renderings, demonstrating its potential in applications like autonomous driving.
Indoor Scene Reconstruction with Fine-Grained Details Using Hybrid Representation and Normal Prior Enhancement
Sep 14, 2023



The reconstruction of indoor scenes from multi-view RGB images is challenging due to the coexistence of flat and texture-less regions alongside delicate and fine-grained regions. Recent methods leverage neural radiance fields aided by predicted surface normal priors to recover the scene geometry. These methods excel in producing complete and smooth results for floor and wall areas. However, they struggle to capture complex surfaces with high-frequency structures due to the inadequate neural representation and the inaccurately predicted normal priors. To improve the capacity of the implicit representation, we propose a hybrid architecture to represent low-frequency and high-frequency regions separately. To enhance the normal priors, we introduce a simple yet effective image sharpening and denoising technique, coupled with a network that estimates the pixel-wise uncertainty of the predicted surface normal vectors. Identifying such uncertainty can prevent our model from being misled by unreliable surface normal supervisions that hinder the accurate reconstruction of intricate geometries. Experiments on the benchmark datasets show that our method significantly outperforms existing methods in terms of reconstruction quality.
O^2-Recon: Completing 3D Reconstruction of Occluded Objects in the Scene with a Pre-trained 2D Diffusion Model
Aug 18, 2023Occlusion is a common issue in 3D reconstruction from RGB-D videos, often blocking the complete reconstruction of objects and presenting an ongoing problem. In this paper, we propose a novel framework, empowered by a 2D diffusion-based in-painting model, to reconstruct complete surfaces for the hidden parts of objects. Specifically, we utilize a pre-trained diffusion model to fill in the hidden areas of 2D images. Then we use these in-painted images to optimize a neural implicit surface representation for each instance for 3D reconstruction. Since creating the in-painting masks needed for this process is tricky, we adopt a human-in-the-loop strategy that involves very little human engagement to generate high-quality masks. Moreover, some parts of objects can be totally hidden because the videos are usually shot from limited perspectives. To ensure recovering these invisible areas, we develop a cascaded network architecture for predicting signed distance field, making use of different frequency bands of positional encoding and maintaining overall smoothness. Besides the commonly used rendering loss, Eikonal loss, and silhouette loss, we adopt a CLIP-based semantic consistency loss to guide the surface from unseen camera angles. Experiments on ScanNet scenes show that our proposed framework achieves state-of-the-art accuracy and completeness in object-level reconstruction from scene-level RGB-D videos.