 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal State Estimation in Groups via Active Information Gathering
May 15, 2025Accurately estimating human internal states, such as personality traits or behavioral patterns, is critical for enhancing the effectiveness of human-robot interaction, particularly in group settings. These insights are key in applications ranging from social navigation to autism diagnosis. However, prior methods are limited by scalability and passive observation, making real-time estimation in complex, multi-human settings difficult. In this work, we propose a practical method for active human personality estimation in groups, with a focus on applications related to Autism Spectrum Disorder (ASD). Our method combines a personality-conditioned behavior model, based on the Eysenck 3-Factor theory, with an active robot information gathering policy that triggers human behaviors through a receding-horizon planner. The robot's belief about human personality is then updated via Bayesian inference. We demonstrate the effectiveness of our approach through simulations, user studies with typical adults, and preliminary experiments involving participants with ASD. Our results show that our method can scale to tens of humans and reduce personality prediction error by 29.2% and uncertainty by 79.9% in simulation. User studies with typical adults confirm the method's ability to generalize across complex personality distributions. Additionally, we explore its application in autism-related scenarios, demonstrating that the method can identify the difference between neurotypical and autistic behavior, highlighting its potential for diagnosing ASD. The results suggest that our framework could serve as a foundation for future ASD-specific interventions.
THUD++: Large-Scale Dynamic Indoor Scene Dataset and Benchmark for Mobile Robots
Dec 11, 2024Most existing mobile robotic datasets primarily capture static scenes, limiting their utility for evaluating robotic performance in dynamic environments. To address this, we present a mobile robot oriented large-scale indoor dataset, denoted as THUD++ (TsingHua University Dynamic) robotic dataset, for dynamic scene understanding. Our current dataset includes 13 large-scale dynamic scenarios, combining both real-world and synthetic data collected with a real robot platform and a physical simulation platform, respectively. The RGB-D dataset comprises over 90K image frames, 20M 2D/3D bounding boxes of static and dynamic objects, camera poses, and IMU. The trajectory dataset covers over 6,000 pedestrian trajectories in indoor scenes. Additionally, the dataset is augmented with a Unity3D-based simulation platform, allowing researchers to create custom scenes and test algorithms in a controlled environment. We evaluate state-of-the-art methods on THUD++ across mainstream indoor scene understanding tasks, e.g., 3D object detection, semantic segmentation, relocalization, pedestrian trajectory prediction, and navigation. Our experiments highlight the challenges mobile robots encounter in indoor environments, especially when navigating in complex, crowded, and dynamic scenes. By sharing this dataset, we aim to accelerate the development and testing of mobile robot algorithms, contributing to real-world robotic applications.
SS3DM: Benchmarking Street-View Surface Reconstruction with a Synthetic 3D Mesh Dataset
Oct 29, 2024


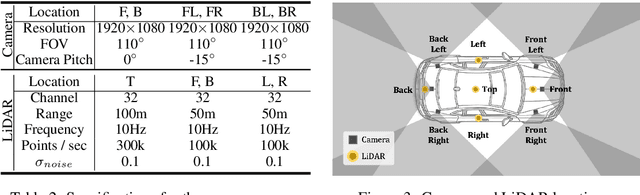
Reconstructing accurate 3D surfaces for street-view scenarios is crucial for applications such as digital entertainment and autonomous driving simulation. However, existing street-view datasets, including KITTI, Waymo, and nuScenes, only offer noisy LiDAR points as ground-truth data for geometric evaluation of reconstructed surfaces. These geometric ground-truths often lack the necessary precision to evaluate surface positions and do not provide data for assessing surface normals. To overcome these challenges, we introduce the SS3DM dataset, comprising precise \textbf{S}ynthetic \textbf{S}treet-view \textbf{3D} \textbf{M}esh models exported from the CARLA simulator. These mesh models facilitate accurate position evaluation and include normal vectors for evaluating surface normal. To simulate the input data in realistic driving scenarios for 3D reconstruction, we virtually drive a vehicle equipped with six RGB cameras and five LiDAR sensors in diverse outdoor scenes. Leveraging this dataset, we establish a benchmark for state-of-the-art surface reconstruction methods, providing a comprehensive evaluation of the associated challenges. For more information, visit our homepage at https://ss3dm.top.
Mobile Robot Oriented Large-Scale Indoor Dataset for Dynamic Scene Understanding
Jun 28, 2024Most existing robotic datasets capture static scene data and thus are limited in evaluating robots' dynamic performance. To address this, we present a mobile robot oriented large-scale indoor dataset, denoted as THUD (Tsinghua University Dynamic) robotic dataset, for training and evaluating their dynamic scene understanding algorithms. Specifically, the THUD dataset construction is first detailed, including organization, acquisition, and annotation methods. It comprises both real-world and synthetic data, collected with a real robot platform and a physical simulation platform, respectively. Our current dataset includes 13 larges-scale dynamic scenarios, 90K image frames, 20M 2D/3D bounding boxes of static and dynamic objects, camera poses, and IMU. The dataset is still continuously expanding. Then, the performance of mainstream indoor scene understanding tasks, e.g. 3D object detection, semantic segmentation, and robot relocalization, is evaluated on our THUD dataset. These experiments reveal serious challenges for some robot scene understanding tasks in dynamic scenes. By sharing this dataset, we aim to foster and iterate new mobile robot algorithms quickly for robot actual working dynamic environment, i.e. complex crowded dynamic scenes.
Automatic Tooth Arrangement with Joint Features of Point and Mesh Representations via Diffusion Probabilistic Models
Dec 23, 2023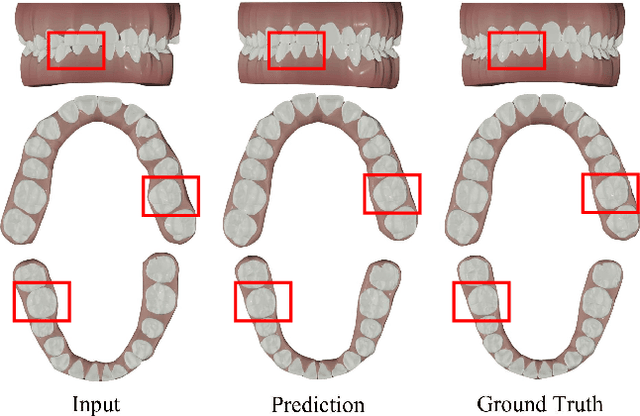
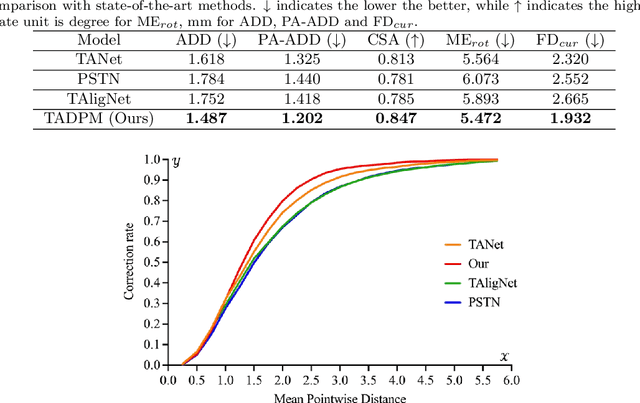

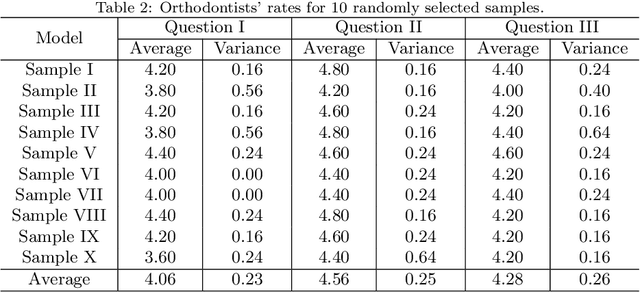
Tooth arrangement is a crucial step in orthodontics treatment, in which aligning teeth could improve overall well-being, enhance facial aesthetics, and boost self-confidence. To improve the efficiency of tooth arrangement and minimize errors associated with unreasonable designs by inexperienced practitioners, some deep learning-based tooth arrangement methods have been proposed. Currently, most existing approaches employ MLPs to model the nonlinear relationship between tooth features and transformation matrices to achieve tooth arrangement automatically. However, the limited datasets (which to our knowledge, have not been made public) collected from clinical practice constrain the applicability of existing methods, making them inadequate for addressing diverse malocclusion issues. To address this challenge, we propose a general tooth arrangement neural network based on the diffusion probabilistic model. Conditioned on the features extracted from the dental model, the diffusion probabilistic model can learn the distribution of teeth transformation matrices from malocclusion to normal occlusion by gradually denoising from a random variable, thus more adeptly managing real orthodontic data. To take full advantage of effective features, we exploit both mesh and point cloud representations by designing different encoding networks to extract the tooth (local) and jaw (global) features, respectively. In addition to traditional metrics ADD, PA-ADD, CSA, and ME_{rot}, we propose a new evaluation metric based on dental arch curves to judge whether the generated teeth meet the individual normal occlusion. Experimental results demonstrate that our proposed method achieves state-of-the-art tooth alignment results and satisfactory occlusal relationships between dental arches. We will publish the code and dataset.
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
Mar 20, 2021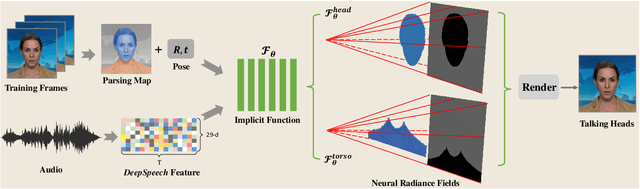
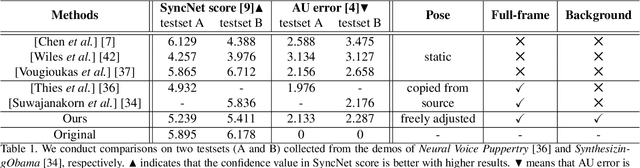
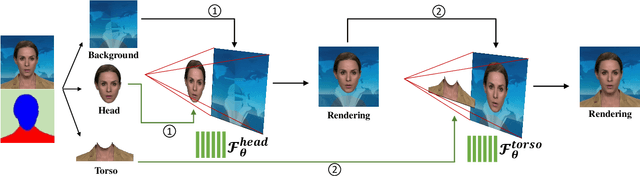
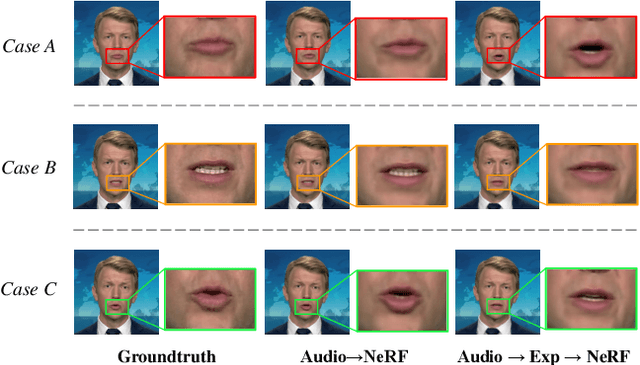
Generating high-fidelity talking head video by fitting with the input audio sequence is a challenging problem that receives considerable attentions recently. In this paper, we address this problem with the aid of neural scene representation networks. Our method is completely different from existing methods that rely on intermediate representations like 2D landmarks or 3D face models to bridge the gap between audio input and video output. Specifically, the feature of input audio signal is directly fed into a conditional implicit function to generate a dynamic neural radiance field, from which a high-fidelity talking-head video corresponding to the audio signal is synthesized using volume rendering. Another advantage of our framework is that not only the head (with hair) region is synthesized as previous methods did, but also the upper body is generated via two individual neural radiance fields. Experimental results demonstrate that our novel framework can (1) produce high-fidelity and natural results, and (2) support free adjustment of audio signals, viewing directions, and background images.