 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtPro: Self-Supervised Articulated Object Reconstruction with Adaptive Integration of Mobility Proposals
Feb 26, 2026Reconstructing articulated objects into high-fidelity digital twins is crucial for applications such as robotic manipulation and interactive simulation. Recent self-supervised methods using differentiable rendering frameworks like 3D Gaussian Splatting remain highly sensitive to the initial part segmentation. Their reliance on heuristic clustering or pre-trained models often causes optimization to converge to local minima, especially for complex multi-part objects. To address these limitations, we propose ArtPro, a novel self-supervised framework that introduces adaptive integration of mobility proposals. Our approach begins with an over-segmentation initialization guided by geometry features and motion priors, generating part proposals with plausible motion hypotheses. During optimization, we dynamically merge these proposals by analyzing motion consistency among spatial neighbors, while a collision-aware motion pruning mechanism prevents erroneous kinematic estimation. Extensive experiments on both synthetic and real-world objects demonstrate that ArtPro achieves robust reconstruction of complex multi-part objects, significantly outperforming existing methods in accuracy and stability.
Adaptive and Iterative Point Cloud Denoising with Score-Based Diffusion Model
Sep 18, 2025Point cloud denoising task aims to recover the clean point cloud from the scanned data coupled with different levels or patterns of noise. The recent state-of-the-art methods often train deep neural networks to update the point locations towards the clean point cloud, and empirically repeat the denoising process several times in order to obtain the denoised results. It is not clear how to efficiently arrange the iterative denoising processes to deal with different levels or patterns of noise. In this paper, we propose an adaptive and iterative point cloud denoising method based on the score-based diffusion model. For a given noisy point cloud, we first estimate the noise variation and determine an adaptive denoising schedule with appropriate step sizes, then invoke the trained network iteratively to update point clouds following the adaptive schedule. To facilitate this adaptive and iterative denoising process, we design the network architecture and a two-stage sampling strategy for the network training to enable feature fusion and gradient fusion for iterative denoising. Compared to the state-of-the-art point cloud denoising methods, our approach obtains clean and smooth denoised point clouds, while preserving the shape boundary and details better. Our results not only outperform the other methods both qualitatively and quantitatively, but also are preferable on the synthetic dataset with different patterns of noises, as well as the real-scanned dataset.
Self-Supervised Continuous Colormap Recovery from a 2D Scalar Field Visualization without a Legend
Jul 28, 2025Recovering a continuous colormap from a single 2D scalar field visualization can be quite challenging, especially in the absence of a corresponding color legend. In this paper, we propose a novel colormap recovery approach that extracts the colormap from a color-encoded 2D scalar field visualization by simultaneously predicting the colormap and underlying data using a decoupling-and-reconstruction strategy. Our approach first separates the input visualization into colormap and data using a decoupling module, then reconstructs the visualization with a differentiable color-mapping module. To guide this process, we design a reconstruction loss between the input and reconstructed visualizations, which serves both as a constraint to ensure strong correlation between colormap and data during training, and as a self-supervised optimizer for fine-tuning the predicted colormap of unseen visualizations during inferencing. To ensure smoothness and correct color ordering in the extracted colormap, we introduce a compact colormap representation using cubic B-spline curves and an associated color order loss. We evaluate our method quantitatively and qualitatively on a synthetic dataset and a collection of real-world visualizations from the VIS30K dataset. Additionally, we demonstrate its utility in two prototype applications -- colormap adjustment and colormap transfer -- and explore its generalization to visualizations with color legends and ones encoded using discrete color palettes.
NeuVAS: Neural Implicit Surfaces for Variational Shape Modeling
Jun 16, 2025Neural implicit shape representation has drawn significant attention in recent years due to its smoothness, differentiability, and topological flexibility. However, directly modeling the shape of a neural implicit surface, especially as the zero-level set of a neural signed distance function (SDF), with sparse geometric control is still a challenging task. Sparse input shape control typically includes 3D curve networks or, more generally, 3D curve sketches, which are unstructured and cannot be connected to form a curve network, and therefore more difficult to deal with. While 3D curve networks or curve sketches provide intuitive shape control, their sparsity and varied topology pose challenges in generating high-quality surfaces to meet such curve constraints. In this paper, we propose NeuVAS, a variational approach to shape modeling using neural implicit surfaces constrained under sparse input shape control, including unstructured 3D curve sketches as well as connected 3D curve networks. Specifically, we introduce a smoothness term based on a functional of surface curvatures to minimize shape variation of the zero-level set surface of a neural SDF. We also develop a new technique to faithfully model G0 sharp feature curves as specified in the input curve sketches. Comprehensive comparisons with the state-of-the-art methods demonstrate the significant advantages of our method.
Internal State Estimation in Groups via Active Information Gathering
May 15, 2025Accurately estimating human internal states, such as personality traits or behavioral patterns, is critical for enhancing the effectiveness of human-robot interaction, particularly in group settings. These insights are key in applications ranging from social navigation to autism diagnosis. However, prior methods are limited by scalability and passive observation, making real-time estimation in complex, multi-human settings difficult. In this work, we propose a practical method for active human personality estimation in groups, with a focus on applications related to Autism Spectrum Disorder (ASD). Our method combines a personality-conditioned behavior model, based on the Eysenck 3-Factor theory, with an active robot information gathering policy that triggers human behaviors through a receding-horizon planner. The robot's belief about human personality is then updated via Bayesian inference. We demonstrate the effectiveness of our approach through simulations, user studies with typical adults, and preliminary experiments involving participants with ASD. Our results show that our method can scale to tens of humans and reduce personality prediction error by 29.2% and uncertainty by 79.9% in simulation. User studies with typical adults confirm the method's ability to generalize across complex personality distributions. Additionally, we explore its application in autism-related scenarios, demonstrating that the method can identify the difference between neurotypical and autistic behavior, highlighting its potential for diagnosing ASD. The results suggest that our framework could serve as a foundation for future ASD-specific interventions.
SymbioSim: Human-in-the-loop Simulation Platform for Bidirectional Continuing Learning in Human-Robot Interaction
Feb 11, 2025The development of intelligent robots seeks to seamlessly integrate them into the human world, providing assistance and companionship in daily life and work, with the ultimate goal of achieving human-robot symbiosis. To realize this vision, robots must continuously learn and evolve through consistent interaction and collaboration with humans, while humans need to gradually develop an understanding of and trust in robots through shared experiences. However, training and testing algorithms directly on physical robots involve substantial costs and safety risks. Moreover, current robotic simulators fail to support real human participation, limiting their ability to provide authentic interaction experiences and gather valuable human feedback. In this paper, we introduce SymbioSim, a novel human-in-the-loop robotic simulation platform designed to enable the safe and efficient development, evaluation, and optimization of human-robot interactions. By leveraging a carefully designed system architecture and modules, SymbioSim delivers a natural and realistic interaction experience, facilitating bidirectional continuous learning and adaptation for both humans and robots. Extensive experiments and user studies demonstrate the platform's promising performance and highlight its potential to significantly advance research on human-robot symbiosis.
Deep-PE: A Learning-Based Pose Evaluator for Point Cloud Registration
May 25, 2024



In the realm of point cloud registration, the most prevalent pose evaluation approaches are statistics-based, identifying the optimal transformation by maximizing the number of consistent correspondences. However, registration recall decreases significantly when point clouds exhibit a low overlap rate, despite efforts in designing feature descriptors and establishing correspondences. In this paper, we introduce Deep-PE, a lightweight, learning-based pose evaluator designed to enhance the accuracy of pose selection, especially in challenging point cloud scenarios with low overlap. Our network incorporates a Pose-Aware Attention (PAA) module to simulate and learn the alignment status of point clouds under various candidate poses, alongside a Pose Confidence Prediction (PCP) module that predicts the likelihood of successful registration. These two modules facilitate the learning of both local and global alignment priors. Extensive tests across multiple benchmarks confirm the effectiveness of Deep-PE. Notably, on 3DLoMatch with a low overlap rate, Deep-PE significantly outperforms state-of-the-art methods by at least 8% and 11% in registration recall under handcrafted FPFH and learning-based FCGF descriptors, respectively. To the best of our knowledge, this is the first study to utilize deep learning to select the optimal pose without the explicit need for input correspondences.
ComboStoc: Combinatorial Stochasticity for Diffusion Generative Models
May 22, 2024
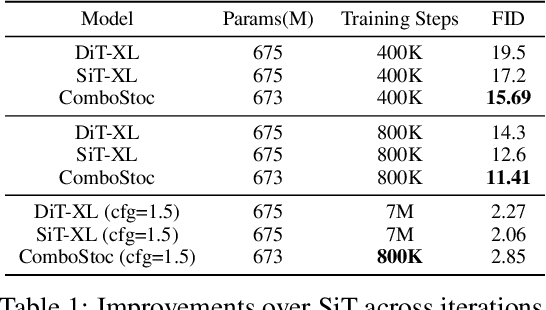

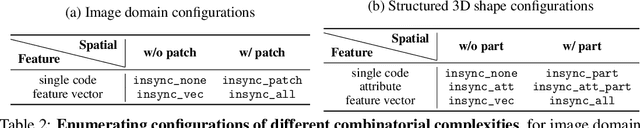
In this paper, we study an under-explored but important factor of diffusion generative models, i.e., the combinatorial complexity. Data samples are generally high-dimensional, and for various structured generation tasks, there are additional attributes which are combined to associate with data samples. We show that the space spanned by the combination of dimensions and attributes is insufficiently sampled by existing training scheme of diffusion generative models, causing degraded test time performance. We present a simple fix to this problem by constructing stochastic processes that fully exploit the combinatorial structures, hence the name ComboStoc. Using this simple strategy, we show that network training is significantly accelerated across diverse data modalities, including images and 3D structured shapes. Moreover, ComboStoc enables a new way of test time generation which uses insynchronized time steps for different dimensions and attributes, thus allowing for varying degrees of control over them.
NeurCross: A Self-Supervised Neural Approach for Representing Cross Fields in Quad Mesh Generation
May 22, 2024

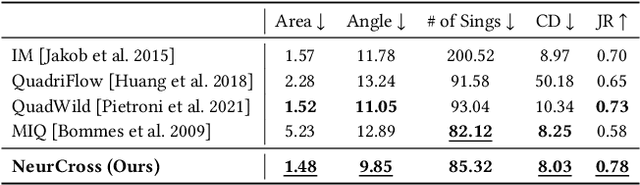
Quadrilateral mesh generation plays a crucial role in numerical simulations within Computer-Aided Design and Engineering (CAD/E). The quality of the cross field is essential for generating a quadrilateral mesh. In this paper, we propose a self-supervised neural representation of the cross field, named NeurCross, comprising two modules: one to fit the signed distance function (SDF) and another to predict the cross field. Unlike most existing approaches that operate directly on the given polygonal surface, NeurCross takes the SDF as a bridge to allow for SDF overfitting and the prediction of the cross field to proceed simultaneously. By utilizing a neural SDF, we achieve a smooth representation of the base surface, minimizing the impact of piecewise planar discretization and minor surface variations. Moreover, the principal curvatures and directions are fully encoded by the Hessian of the SDF, enabling the regularization of the overall cross field through minor adjustments to the SDF. Compared to state-of-the-art methods, NeurCross significantly improves the placement of singular points and the approximation accuracy between the input triangular surface and the output quad mesh, as demonstrated in the teaser figure.
CWF: Consolidating Weak Features in High-quality Mesh Simplification
Apr 24, 2024



In mesh simplification, common requirements like accuracy, triangle quality, and feature alignment are often considered as a trade-off. Existing algorithms concentrate on just one or a few specific aspects of these requirements. For example, the well-known Quadric Error Metrics (QEM) approach prioritizes accuracy and can preserve strong feature lines/points as well but falls short in ensuring high triangle quality and may degrade weak features that are not as distinctive as strong ones. In this paper, we propose a smooth functional that simultaneously considers all of these requirements. The functional comprises a normal anisotropy term and a Centroidal Voronoi Tessellation (CVT) energy term, with the variables being a set of movable points lying on the surface. The former inherits the spirit of QEM but operates in a continuous setting, while the latter encourages even point distribution, allowing various surface metrics. We further introduce a decaying weight to automatically balance the two terms. We selected 100 CAD models from the ABC dataset, along with 21 organic models, to compare the existing mesh simplification algorithms with ours. Experimental results reveal an important observation: the introduction of a decaying weight effectively reduces the conflict between the two terms and enables the alignment of weak features. This distinctive feature sets our approach apart from most existing mesh simplification methods and demonstrates significant potential in shape understanding.