 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransCDR: a deep learning model for enhancing the generalizability of cancer drug response prediction through transfer learning and multimodal data fusion for drug representation
Nov 17, 2023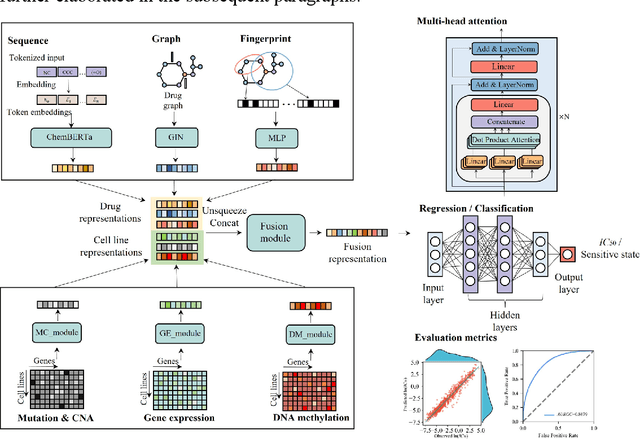



Accurate and robust drug response prediction is of utmost importance in precision medicine. Although many models have been developed to utilize the representations of drugs and cancer cell lines for predicting cancer drug responses (CDR), their performances can be improved by addressing issues such as insufficient data modality, suboptimal fusion algorithms, and poor generalizability for novel drugs or cell lines. We introduce TransCDR, which uses transfer learning to learn drug representations and fuses multi-modality features of drugs and cell lines by a self-attention mechanism, to predict the IC50 values or sensitive states of drugs on cell lines. We are the first to systematically evaluate the generalization of the CDR prediction model to novel (i.e., never-before-seen) compound scaffolds and cell line clusters. TransCDR shows better generalizability than 8 state-of-the-art models. TransCDR outperforms its 5 variants that train drug encoders (i.e., RNN and AttentiveFP) from scratch under various scenarios. The most critical contributors among multiple drug notations and omics profiles are Extended Connectivity Fingerprint and genetic mutation. Additionally, the attention-based fusion module further enhances the predictive performance of TransCDR. TransCDR, trained on the GDSC dataset, demonstrates strong predictive performance on the external testing set CCLE. It is also utilized to predict missing CDRs on GDSC. Moreover, we investigate the biological mechanisms underlying drug response by classifying 7,675 patients from TCGA into drug-sensitive or drug-resistant groups, followed by a Gene Set Enrichment Analysis. TransCDR emerges as a potent tool with significant potential in drug response prediction. The source code and data can be accessed at https://github.com/XiaoqiongXia/TransCDR.
For A More Comprehensive Evaluation of 6DoF Object Pose Tracking
Sep 15, 2023

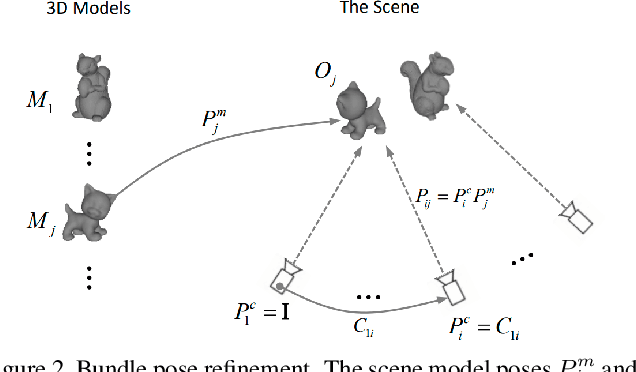

Previous evaluations on 6DoF object pose tracking have presented obvious limitations along with the development of this area. In particular, the evaluation protocols are not unified for different methods, the widely-used YCBV dataset contains significant annotation error, and the error metrics also may be biased. As a result, it is hard to fairly compare the methods, which has became a big obstacle for developing new algorithms. In this paper we contribute a unified benchmark to address the above problems. For more accurate annotation of YCBV, we propose a multi-view multi-object global pose refinement method, which can jointly refine the poses of all objects and view cameras, resulting in sub-pixel sub-millimeter alignment errors. The limitations of previous scoring methods and error metrics are analyzed, based on which we introduce our improved evaluation methods. The unified benchmark takes both YCBV and BCOT as base datasets, which are shown to be complementary in scene categories. In experiments, we validate the precision and reliability of the proposed global pose refinement method with a realistic semi-synthesized dataset particularly for YCBV, and then present the benchmark results unifying learning&non-learning and RGB&RGBD methods, with some finds not discovered in previous studies.
Guided Linear Upsampling
Jul 13, 2023



Guided upsampling is an effective approach for accelerating high-resolution image processing. In this paper, we propose a simple yet effective guided upsampling method. Each pixel in the high-resolution image is represented as a linear interpolation of two low-resolution pixels, whose indices and weights are optimized to minimize the upsampling error. The downsampling can be jointly optimized in order to prevent missing small isolated regions. Our method can be derived from the color line model and local color transformations. Compared to previous methods, our method can better preserve detail effects while suppressing artifacts such as bleeding and blurring. It is efficient, easy to implement, and free of sensitive parameters. We evaluate the proposed method with a wide range of image operators, and show its advantages through quantitative and qualitative analysis. We demonstrate the advantages of our method for both interactive image editing and real-time high-resolution video processing. In particular, for interactive editing, the joint optimization can be precomputed, thus allowing for instant feedback without hardware acceleration.
Large-displacement 3D Object Tracking with Hybrid Non-local Optimization
Jul 26, 2022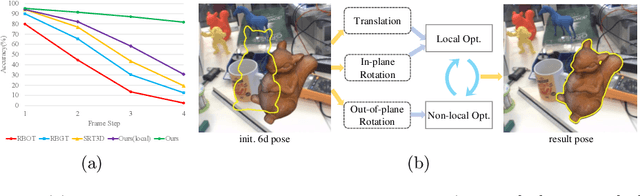



Optimization-based 3D object tracking is known to be precise and fast, but sensitive to large inter-frame displacements. In this paper we propose a fast and effective non-local 3D tracking method. Based on the observation that erroneous local minimum are mostly due to the out-of-plane rotation, we propose a hybrid approach combining non-local and local optimizations for different parameters, resulting in efficient non-local search in the 6D pose space. In addition, a precomputed robust contour-based tracking method is proposed for the pose optimization. By using long search lines with multiple candidate correspondences, it can adapt to different frame displacements without the need of coarse-to-fine search. After the pre-computation, pose updates can be conducted very fast, enabling the non-local optimization to run in real time. Our method outperforms all previous methods for both small and large displacements. For large displacements, the accuracy is greatly improved ($81.7\% \;\text{v.s.}\; 19.4\%$). At the same time, real-time speed ($>$50fps) can be achieved with only CPU. The source code is available at \url{https://github.com/cvbubbles/nonlocal-3dtracking}.
BCOT: A Markerless High-Precision 3D Object Tracking Benchmark
Mar 25, 2022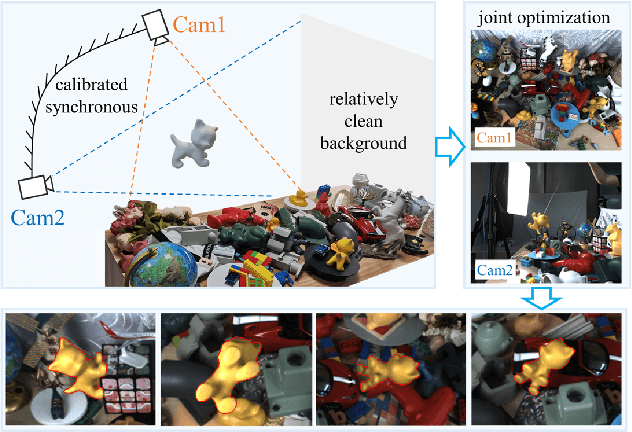
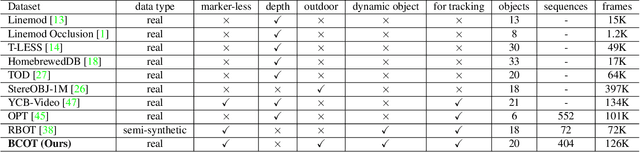


Template-based 3D object tracking still lacks a high-precision benchmark of real scenes due to the difficulty of annotating the accurate 3D poses of real moving video objects without using markers. In this paper, we present a multi-view approach to estimate the accurate 3D poses of real moving objects, and then use binocular data to construct a new benchmark for monocular textureless 3D object tracking. The proposed method requires no markers, and the cameras only need to be synchronous, relatively fixed as cross-view and calibrated. Based on our object-centered model, we jointly optimize the object pose by minimizing shape re-projection constraints in all views, which greatly improves the accuracy compared with the single-view approach, and is even more accurate than the depth-based method. Our new benchmark dataset contains 20 textureless objects, 22 scenes, 404 video sequences and 126K images captured in real scenes. The annotation error is guaranteed to be less than 2mm, according to both theoretical analysis and validation experiments. We re-evaluate the state-of-the-art 3D object tracking methods with our dataset, reporting their performance ranking in real scenes. Our BCOT benchmark and code can be found at https://ar3dv.github.io/BCOT-Benchmark/.
Sparsely Grouped Multi-task Generative Adversarial Networks for Facial Attribute Manipulation
Oct 19, 2018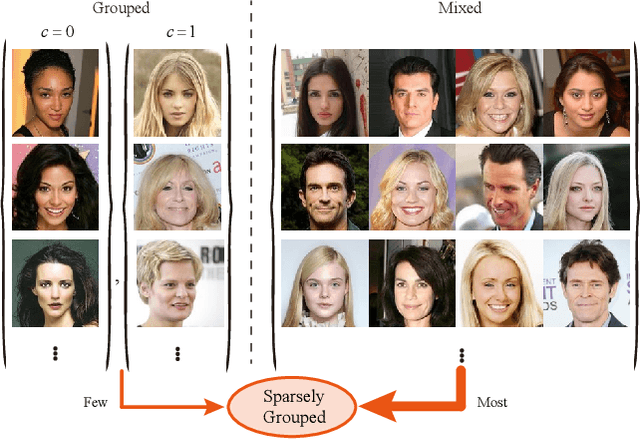
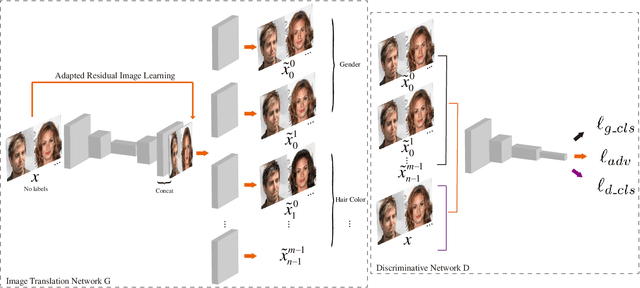
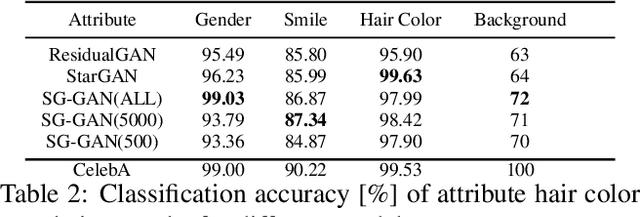
Recently, Image-to-Image Translation (IIT) has achieved great progress in image style transfer and semantic context manipulation for images. However, existing approaches require exhaustively labelling training data, which is labor demanding, difficult to scale up, and hard to adapt to a new domain. To overcome such a key limitation, we propose Sparsely Grouped Generative Adversarial Networks (SG-GAN) as a novel approach that can translate images in sparsely grouped datasets where only a few train samples are labelled. Using a one-input multi-output architecture, SG-GAN is well-suited for tackling multi-task learning and sparsely grouped learning tasks. The new model is able to translate images among multiple groups using only a single trained model. To experimentally validate the advantages of the new model, we apply the proposed method to tackle a series of attribute manipulation tasks for facial images as a case study. Experimental results show that SG-GAN can achieve comparable results with state-of-the-art methods on adequately labelled datasets while attaining a superior image translation quality on sparsely grouped datasets.