 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
Graph Image Prior for Unsupervised Dynamic MRI Reconstruction
Mar 23, 2024The inductive bias of the convolutional neural network (CNN) can act as a strong prior for image restoration, which is known as the Deep Image Prior (DIP). In recent years, DIP has been utilized in unsupervised dynamic MRI reconstruction, which adopts a generative model from the latent space to the image space. However, existing methods usually utilize a single pyramid-shaped CNN architecture to parameterize the generator, which cannot effectively exploit the spatio-temporal correlations within the dynamic data. In this work, we propose a novel scheme to exploit the DIP prior for dynamic MRI reconstruction, named ``Graph Image Prior'' (GIP). The generative model is decomposed into two stages: image recovery and manifold discovery, which is bridged by a graph convolutional network to exploit the spatio-temporal correlations. In addition, we devise an ADMM algorithm to alternately optimize the images and the network parameters to further improve the reconstruction performance. Experimental results demonstrate that GIP outperforms compressed sensing methods and unsupervised methods over different sampling trajectories, and significantly reduces the performance gap with the state-of-art supervised deep-learning methods. Moreover, GIP displays superior generalization ability when transferred to a different reconstruction setting, without the need for any additional data.
Compound Attention and Neighbor Matching Network for Multi-contrast MRI Super-resolution
Jul 24, 2023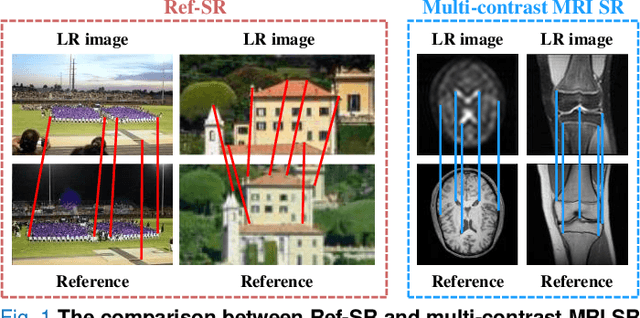
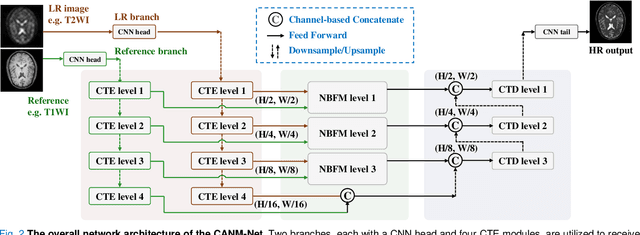

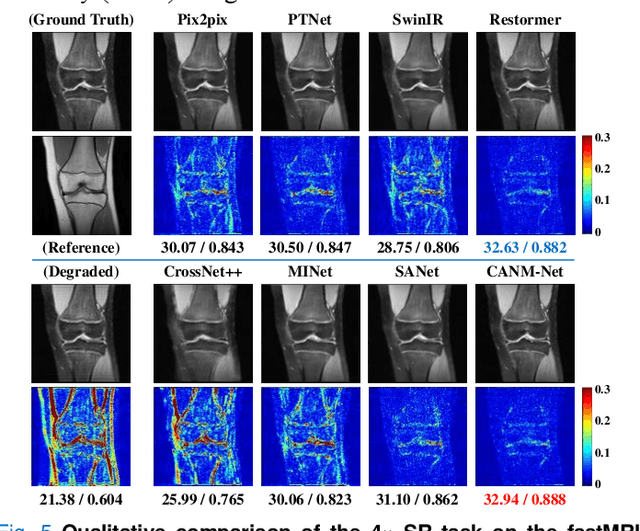
Multi-contrast magnetic resonance imaging (MRI) reflects information about human tissue from different perspectives and has many clinical applications. By utilizing the complementary information among different modalities, multi-contrast super-resolution (SR) of MRI can achieve better results than single-image super-resolution. However, existing methods of multi-contrast MRI SR have the following shortcomings that may limit their performance: First, existing methods either simply concatenate the reference and degraded features or exploit global feature-matching between them, which are unsuitable for multi-contrast MRI SR. Second, although many recent methods employ transformers to capture long-range dependencies in the spatial dimension, they neglect that self-attention in the channel dimension is also important for low-level vision tasks. To address these shortcomings, we proposed a novel network architecture with compound-attention and neighbor matching (CANM-Net) for multi-contrast MRI SR: The compound self-attention mechanism effectively captures the dependencies in both spatial and channel dimension; the neighborhood-based feature-matching modules are exploited to match degraded features and adjacent reference features and then fuse them to obtain the high-quality images. We conduct experiments of SR tasks on the IXI, fastMRI, and real-world scanning datasets. The CANM-Net outperforms state-of-the-art approaches in both retrospective and prospective experiments. Moreover, the robustness study in our work shows that the CANM-Net still achieves good performance when the reference and degraded images are imperfectly registered, proving good potential in clinical applications.
Towards Generalizable Medical Image Segmentation with Pixel-wise Uncertainty Estimation
May 13, 2023Deep neural networks (DNNs) achieve promising performance in visual recognition under the independent and identically distributed (IID) hypothesis. In contrast, the IID hypothesis is not universally guaranteed in numerous real-world applications, especially in medical image analysis. Medical image segmentation is typically formulated as a pixel-wise classification task in which each pixel is classified into a category. However, this formulation ignores the hard-to-classified pixels, e.g., some pixels near the boundary area, as they usually confuse DNNs. In this paper, we first explore that hard-to-classified pixels are associated with high uncertainty. Based on this, we propose a novel framework that utilizes uncertainty estimation to highlight hard-to-classified pixels for DNNs, thereby improving its generalization. We evaluate our method on two popular benchmarks: prostate and fundus datasets. The results of the experiment demonstrate that our method outperforms state-of-the-art methods.
Vector Approximate Message Passing based Channel Estimation for MIMO-OFDM Underwater Acoustic Communications
Nov 22, 2022



Accurate channel estimation is critical to the performance of orthogonal frequency-division multiplexing (OFDM) underwater acoustic (UWA) communications, especially under multiple-input multiple-output (MIMO) scenarios. In this paper, we explore Vector Approximate Message Passing (VAMP) coupled with Expected Maximum (EM) to obtain channel estimation (CE) for MIMO OFDM UWA communications. The EM-VAMP-CE scheme is developed by employing a Bernoulli-Gaussian (BG) prior distribution for the channel impulse response, and hyperparameters of the BG prior distribution are learned via the EM algorithm. Performance of the EM-VAMP-CE is evaluated through both synthesized data and real data collected in two at-sea UWA communication experiments. It is shown the EM-VAMP-CE achieves better performance-complexity tradeoff compared with existing channel estimation methods.
BCOT: A Markerless High-Precision 3D Object Tracking Benchmark
Mar 25, 2022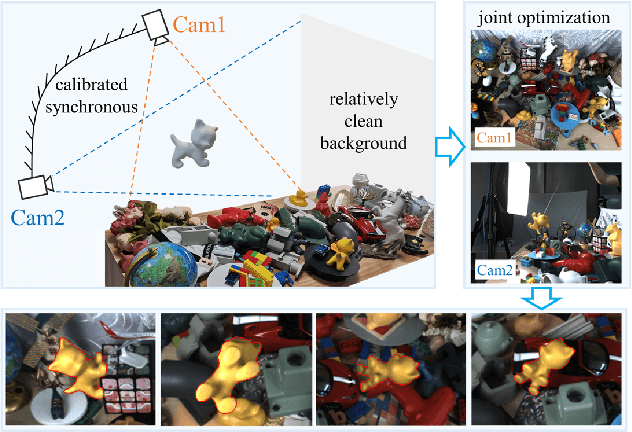
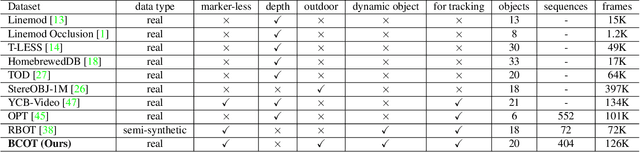


Template-based 3D object tracking still lacks a high-precision benchmark of real scenes due to the difficulty of annotating the accurate 3D poses of real moving video objects without using markers. In this paper, we present a multi-view approach to estimate the accurate 3D poses of real moving objects, and then use binocular data to construct a new benchmark for monocular textureless 3D object tracking. The proposed method requires no markers, and the cameras only need to be synchronous, relatively fixed as cross-view and calibrated. Based on our object-centered model, we jointly optimize the object pose by minimizing shape re-projection constraints in all views, which greatly improves the accuracy compared with the single-view approach, and is even more accurate than the depth-based method. Our new benchmark dataset contains 20 textureless objects, 22 scenes, 404 video sequences and 126K images captured in real scenes. The annotation error is guaranteed to be less than 2mm, according to both theoretical analysis and validation experiments. We re-evaluate the state-of-the-art 3D object tracking methods with our dataset, reporting their performance ranking in real scenes. Our BCOT benchmark and code can be found at https://ar3dv.github.io/BCOT-Benchmark/.