 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPN for Zero-Shot OOD Detection: Teaching CLIP to Say No
Aug 24, 2023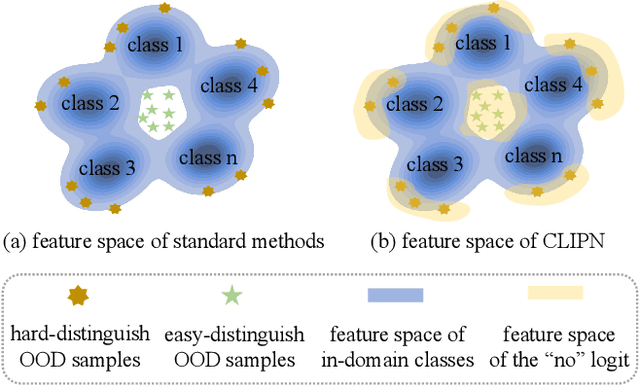
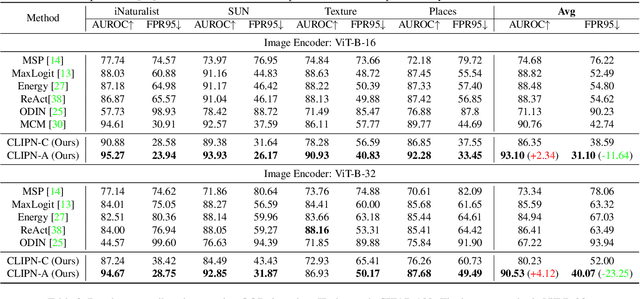
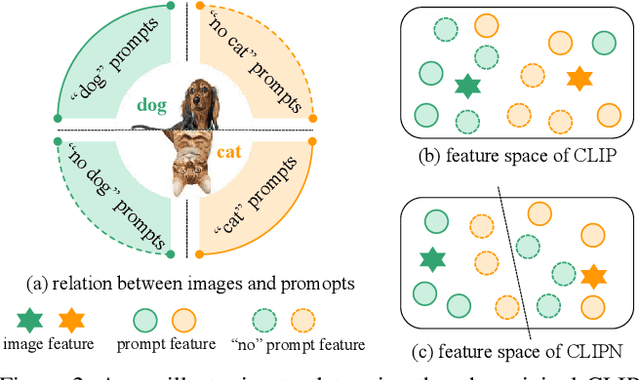
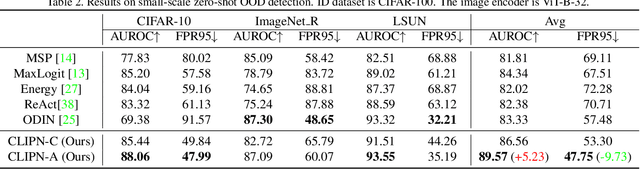
Out-of-distribution (OOD) detection refers to training the model on an in-distribution (ID) dataset to classify whether the input images come from unknown classes. Considerable effort has been invested in designing various OOD detection methods based on either convolutional neural networks or transformers. However, zero-shot OOD detection methods driven by CLIP, which only require class names for ID, have received less attention. This paper presents a novel method, namely CLIP saying no (CLIPN), which empowers the logic of saying no within CLIP. Our key motivation is to equip CLIP with the capability of distinguishing OOD and ID samples using positive-semantic prompts and negation-semantic prompts. Specifically, we design a novel learnable no prompt and a no text encoder to capture negation semantics within images. Subsequently, we introduce two loss functions: the image-text binary-opposite loss and the text semantic-opposite loss, which we use to teach CLIPN to associate images with no prompts, thereby enabling it to identify unknown samples. Furthermore, we propose two threshold-free inference algorithms to perform OOD detection by utilizing negation semantics from no prompts and the text encoder. Experimental results on 9 benchmark datasets (3 ID datasets and 6 OOD datasets) for the OOD detection task demonstrate that CLIPN, based on ViT-B-16, outperforms 7 well-used algorithms by at least 2.34% and 11.64% in terms of AUROC and FPR95 for zero-shot OOD detection on ImageNet-1K. Our CLIPN can serve as a solid foundation for effectively leveraging CLIP in downstream OOD tasks. The code is available on https://github.com/xmed-lab/CLIPN.
Compound Attention and Neighbor Matching Network for Multi-contrast MRI Super-resolution
Jul 24, 2023
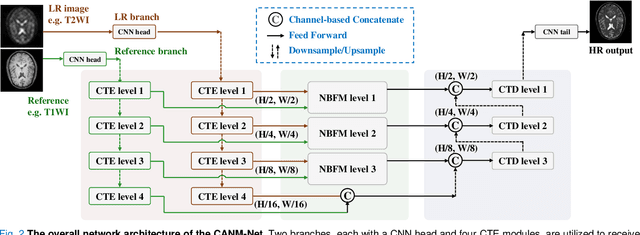

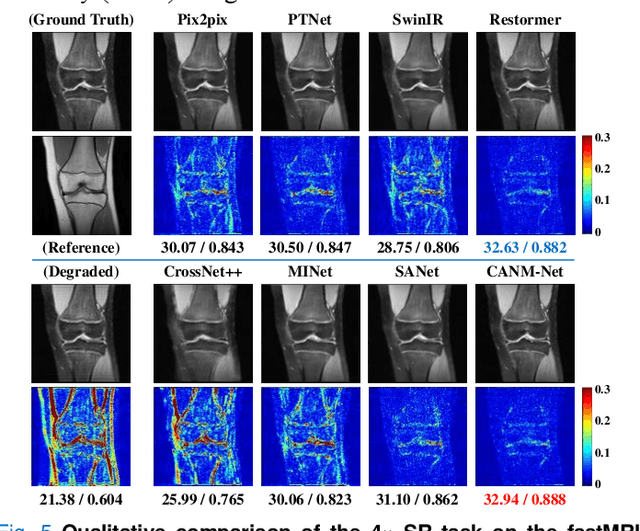
Multi-contrast magnetic resonance imaging (MRI) reflects information about human tissue from different perspectives and has many clinical applications. By utilizing the complementary information among different modalities, multi-contrast super-resolution (SR) of MRI can achieve better results than single-image super-resolution. However, existing methods of multi-contrast MRI SR have the following shortcomings that may limit their performance: First, existing methods either simply concatenate the reference and degraded features or exploit global feature-matching between them, which are unsuitable for multi-contrast MRI SR. Second, although many recent methods employ transformers to capture long-range dependencies in the spatial dimension, they neglect that self-attention in the channel dimension is also important for low-level vision tasks. To address these shortcomings, we proposed a novel network architecture with compound-attention and neighbor matching (CANM-Net) for multi-contrast MRI SR: The compound self-attention mechanism effectively captures the dependencies in both spatial and channel dimension; the neighborhood-based feature-matching modules are exploited to match degraded features and adjacent reference features and then fuse them to obtain the high-quality images. We conduct experiments of SR tasks on the IXI, fastMRI, and real-world scanning datasets. The CANM-Net outperforms state-of-the-art approaches in both retrospective and prospective experiments. Moreover, the robustness study in our work shows that the CANM-Net still achieves good performance when the reference and degraded images are imperfectly registered, proving good potential in clinical applications.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
TripleE: Easy Domain Generalization via Episodic Replay
Oct 04, 2022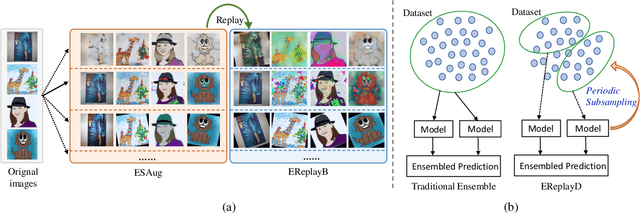
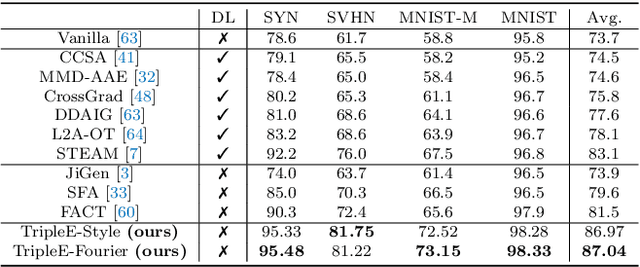

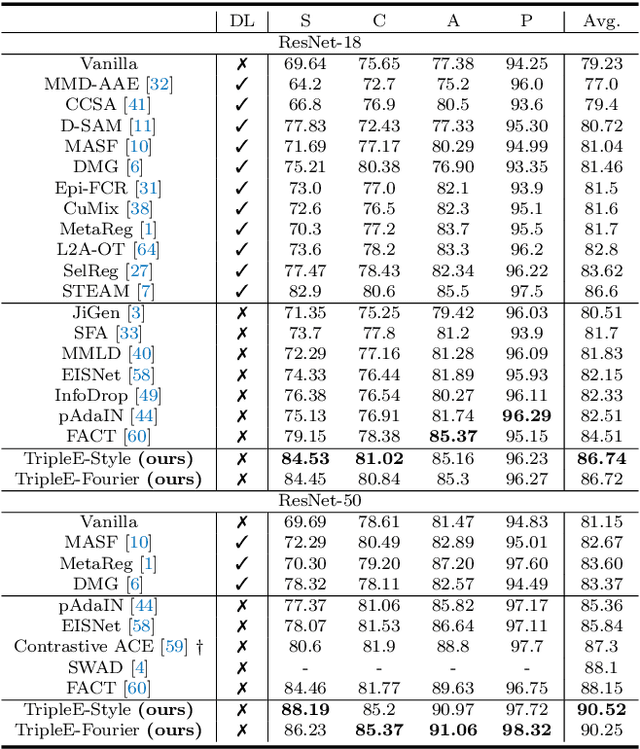
Learning how to generalize the model to unseen domains is an important area of research. In this paper, we propose TripleE, and the main idea is to encourage the network to focus on training on subsets (learning with replay) and enlarge the data space in learning on subsets. Learning with replay contains two core designs, EReplayB and EReplayD, which conduct the replay schema on batch and dataset, respectively. Through this, the network can focus on learning with subsets instead of visiting the global set at a glance, enlarging the model diversity in ensembling. To enlarge the data space in learning on subsets, we verify that an exhaustive and singular augmentation (ESAug) performs surprisingly well on expanding the data space in subsets during replays. Our model dubbed TripleE is frustratingly easy, based on simple augmentation and ensembling. Without bells and whistles, our TripleE method surpasses prior arts on six domain generalization benchmarks, showing that this approach could serve as a stepping stone for future research in domain generalization.
Semi-Supervised Domain Generalization for Cardiac Magnetic Resonance Image Segmentation with High Quality Pseudo Labels
Sep 30, 2022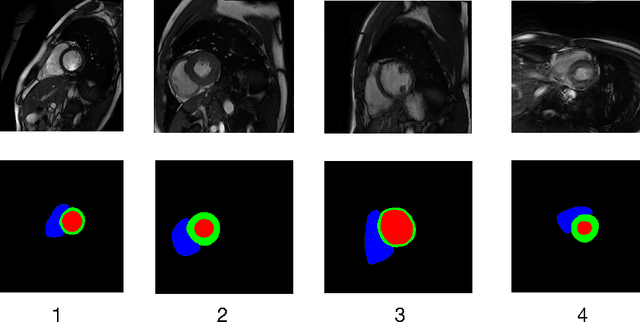

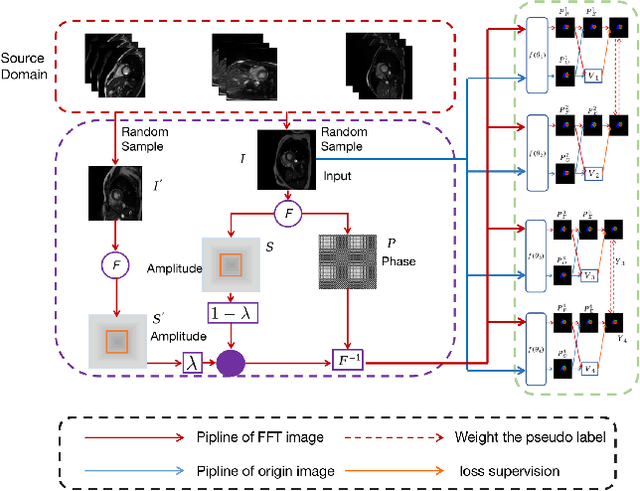
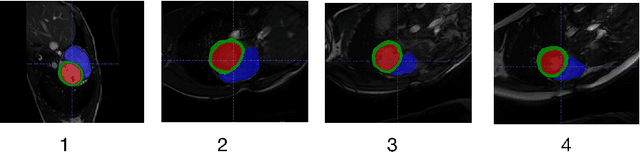
Developing a deep learning method for medical segmentation tasks heavily relies on a large amount of labeled data. However, the annotations require professional knowledge and are limited in number. Recently, semi-supervised learning has demonstrated great potential in medical segmentation tasks. Most existing methods related to cardiac magnetic resonance images only focus on regular images with similar domains and high image quality. A semi-supervised domain generalization method was developed in [2], which enhances the quality of pseudo labels on varied datasets. In this paper, we follow the strategy in [2] and present a domain generalization method for semi-supervised medical segmentation. Our main goal is to improve the quality of pseudo labels under extreme MRI Analysis with various domains. We perform Fourier transformation on input images to learn low-level statistics and cross-domain information. Then we feed the augmented images as input to the double cross pseudo supervision networks to calculate the variance among pseudo labels. We evaluate our method on the CMRxMotion dataset [1]. With only partially labeled data and without domain labels, our approach consistently generates accurate segmentation results of cardiac magnetic resonance images with different respiratory motions. Code will be available after the conference.
FreeSeg: Free Mask from Interpretable Contrastive Language-Image Pretraining for Semantic Segmentation
Sep 27, 2022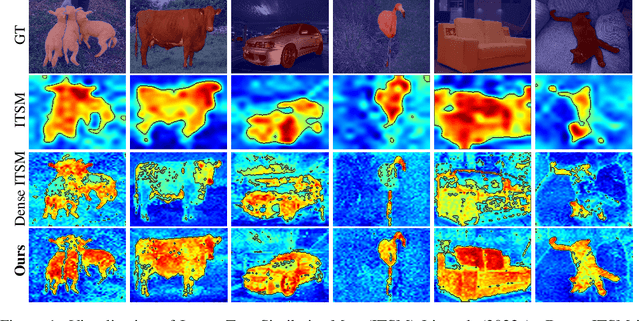
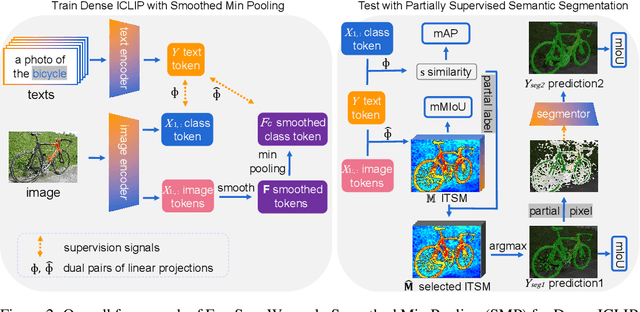

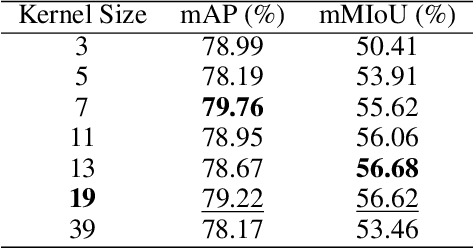
Fully supervised semantic segmentation learns from dense masks, which requires heavy annotation cost for closed set. In this paper, we use natural language as supervision without any pixel-level annotation for open world segmentation. We call the proposed framework as FreeSeg, where the mask is freely available from raw feature map of pretraining model. Compared with zero-shot or openset segmentation, FreeSeg doesn't require any annotated masks, and it widely predicts categories beyond class-agnostic unsupervised segmentation. Specifically, FreeSeg obtains free mask from Image-Text Similarity Map (ITSM) of Interpretable Contrastive Language-Image Pretraining (ICLIP). And our core improvements are the smoothed min pooling for dense ICLIP, with the partial label and pixel strategies for segmentation. Furthermore, FreeSeg is very straight forward without complex design like grouping, clustering or retrieval. Besides the simplicity, the performances of FreeSeg surpass previous state-of-the-art at large margins, e.g. 13.4% higher at mIoU on VOC dataset in the same settings.
Calibrating Label Distribution for Class-Imbalanced Barely-Supervised Knee Segmentation
May 07, 2022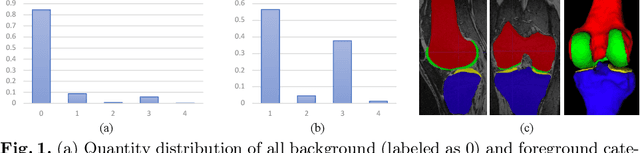
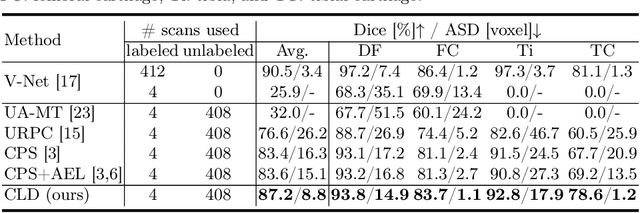
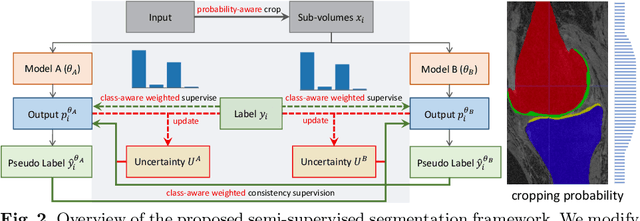
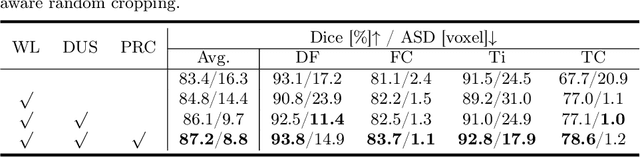
Segmentation of 3D knee MR images is important for the assessment of osteoarthritis. Like other medical data, the volume-wise labeling of knee MR images is expertise-demanded and time-consuming; hence semi-supervised learning (SSL), particularly barely-supervised learning, is highly desirable for training with insufficient labeled data. We observed that the class imbalance problem is severe in the knee MR images as the cartilages only occupy 6% of foreground volumes, and the situation becomes worse without sufficient labeled data. To address the above problem, we present a novel framework for barely-supervised knee segmentation with noisy and imbalanced labels. Our framework leverages label distribution to encourage the network to put more effort into learning cartilage parts. Specifically, we utilize 1.) label quantity distribution for modifying the objective loss function to a class-aware weighted form and 2.) label position distribution for constructing a cropping probability mask to crop more sub-volumes in cartilage areas from both labeled and unlabeled inputs. In addition, we design dual uncertainty-aware sampling supervision to enhance the supervision of low-confident categories for efficient unsupervised learning. Experiments show that our proposed framework brings significant improvements by incorporating the unlabeled data and alleviating the problem of class imbalance. More importantly, our method outperforms the state-of-the-art SSL methods, demonstrating the potential of our framework for the more challenging SSL setting.
Enhancing Pseudo Label Quality for Semi-SupervisedDomain-Generalized Medical Image Segmentation
Jan 21, 2022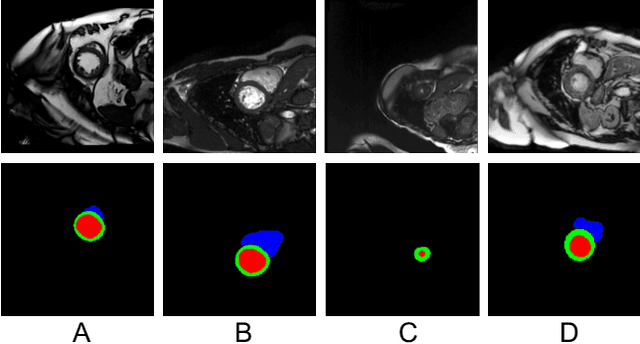
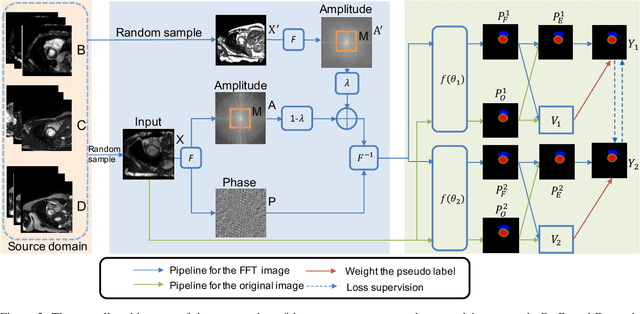

Generalizing the medical image segmentation algorithms tounseen domains is an important research topic for computer-aided diagnosis and surgery. Most existing methods requirea fully labeled dataset in each source domain. Although (Liuet al. 2021b) developed a semi-supervised domain general-ized method, it still requires the domain labels. This paperpresents a novel confidence-aware cross pseudo supervisionalgorithm for semi-supervised domain generalized medicalimage segmentation. The main goal is to enhance the pseudolabel quality for unlabeled images from unknown distribu-tions. To achieve it, we perform the Fourier transformationto learn low-level statistic information across domains andaugment the images to incorporate cross-domain information.With these augmentations as perturbations, we feed the inputto a confidence-aware cross pseudo supervision network tomeasure the variance of pseudo labels and regularize the net-work to learn with more confident pseudo labels. Our methodsets new records on public datasets,i.e., M&Ms and SCGM.Notably, without using domain labels, our method surpassesthe prior art that even uses domain labels by 11.67% on Diceon M&Ms dataset with 2% labeled data. Code will be avail-able after the conference.
Improved Heatmap-based Landmark Detection
Oct 12, 2021
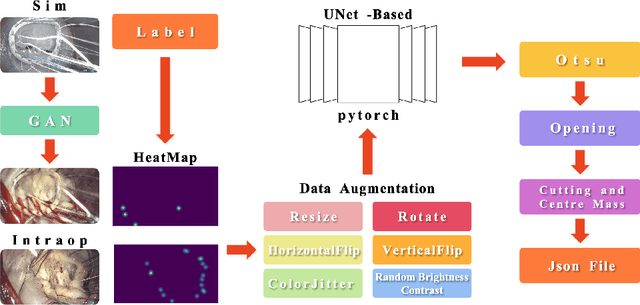
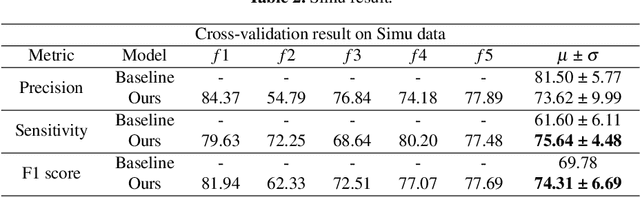
Mitral valve repair is a very difficult operation, often requiring experienced surgeons. The doctor will insert a prosthetic ring to aid in the restoration of heart function. The location of the prosthesis' sutures is critical. Obtaining and studying them during the procedure is a valuable learning experience for new surgeons. This paper proposes a landmark detection network for detecting sutures in endoscopic pictures, which solves the problem of a variable number of suture points in the images. Because there are two datasets, one from the simulated domain and the other from real intraoperative data, this work uses cycleGAN to interconvert the images from the two domains to obtain a larger dataset and a better score on real intraoperative data. This paper performed the tests using a simulated dataset of 2708 photos and a real dataset of 2376 images. The mean sensitivity on the simulated dataset is about 75.64% and the precision is about 73.62%. The mean sensitivity on the real dataset is about 50.23% and the precision is about 62.76%. The data is from the AdaptOR MICCAI Challenge 2021, which can be found at https://zenodo.org/record/4646979\#.YO1zLUxCQ2x.