 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSeg: Free Mask from Interpretable Contrastive Language-Image Pretraining for Semantic Segmentation
Paper and Code
Sep 27, 2022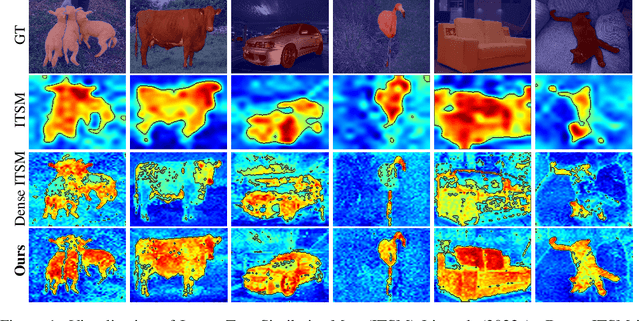
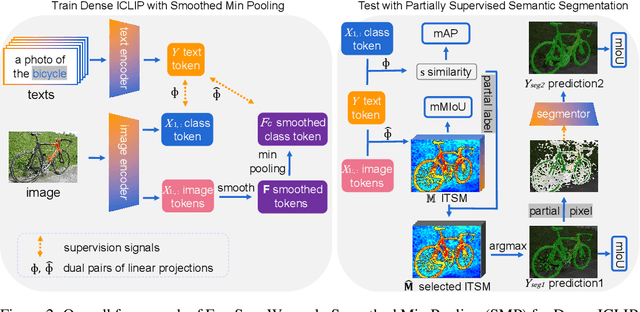

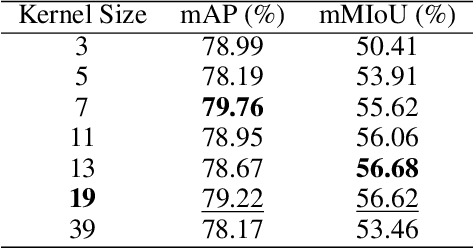
Fully supervised semantic segmentation learns from dense masks, which requires heavy annotation cost for closed set. In this paper, we use natural language as supervision without any pixel-level annotation for open world segmentation. We call the proposed framework as FreeSeg, where the mask is freely available from raw feature map of pretraining model. Compared with zero-shot or openset segmentation, FreeSeg doesn't require any annotated masks, and it widely predicts categories beyond class-agnostic unsupervised segmentation. Specifically, FreeSeg obtains free mask from Image-Text Similarity Map (ITSM) of Interpretable Contrastive Language-Image Pretraining (ICLIP). And our core improvements are the smoothed min pooling for dense ICLIP, with the partial label and pixel strategies for segmentation. Furthermore, FreeSeg is very straight forward without complex design like grouping, clustering or retrieval. Besides the simplicity, the performances of FreeSeg surpass previous state-of-the-art at large margins, e.g. 13.4% higher at mIoU on VOC dataset in the same settings.