 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
PhySe-RPO: Physics and Semantics Guided Relative Policy Optimization for Diffusion-Based Surgical Smoke Removal
Mar 25, 2026Surgical smoke severely degrades intraoperative video quality, obscuring anatomical structures and limiting surgical perception. Existing learning-based desmoking approaches rely on scarce paired supervision and deterministic restoration pipelines, making it difficult to perform exploration or reinforcement-driven refinement under real surgical conditions. We propose PhySe-RPO, a diffusion restoration framework optimized through Physics- and Semantics-Guided Relative Policy Optimization. The core idea is to transform deterministic restoration into a stochastic policy, enabling trajectory-level exploration and critic-free updates via group-relative optimization. A physics-guided reward imposes illumination and color consistency, while a visual-concept semantic reward learned from CLIP-based surgical concepts promotes smoke-free and anatomically coherent restoration. Together with a reference-free perceptual constraint, PhySe-RPO produces results that are physically consistent, semantically faithful, and clinically interpretable across synthetic and real robotic surgical datasets, providing a principled route to robust diffusion-based restoration under limited paired supervision.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Moving Beyond Functional Connectivity: Time-Series Modeling for fMRI-Based Brain Disorder Classification
Feb 09, 2026Functional magnetic resonance imaging (fMRI) enables non-invasive brain disorder classification by capturing blood-oxygen-level-dependent (BOLD) signals. However, most existing methods rely on functional connectivity (FC) via Pearson correlation, which reduces 4D BOLD signals to static 2D matrices, discarding temporal dynamics and capturing only linear inter-regional relationships. In this work, we benchmark state-of-the-art temporal models (e.g., time-series models such as PatchTST, TimesNet, and TimeMixer) on raw BOLD signals across five public datasets. Results show these models consistently outperform traditional FC-based approaches, highlighting the value of directly modeling temporal information such as cycle-like oscillatory fluctuations and drift-like slow baseline trends. Building on this insight, we propose DeCI, a simple yet effective framework that integrates two key principles: (i) Cycle and Drift Decomposition to disentangle cycle and drift within each ROI (Region of Interest); and (ii) Channel-Independence to model each ROI separately, improving robustness and reducing overfitting. Extensive experiments demonstrate that DeCI achieves superior classification accuracy and generalization compared to both FC-based and temporal baselines. Our findings advocate for a shift toward end-to-end temporal modeling in fMRI analysis to better capture complex brain dynamics. The code is available at https://github.com/Levi-Ackman/DeCI.
IdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
Real-World Adverse Weather Image Restoration via Dual-Level Reinforcement Learning with High-Quality Cold Start
Nov 07, 2025Adverse weather severely impairs real-world visual perception, while existing vision models trained on synthetic data with fixed parameters struggle to generalize to complex degradations. To address this, we first construct HFLS-Weather, a physics-driven, high-fidelity dataset that simulates diverse weather phenomena, and then design a dual-level reinforcement learning framework initialized with HFLS-Weather for cold-start training. Within this framework, at the local level, weather-specific restoration models are refined through perturbation-driven image quality optimization, enabling reward-based learning without paired supervision; at the global level, a meta-controller dynamically orchestrates model selection and execution order according to scene degradation. This framework enables continuous adaptation to real-world conditions and achieves state-of-the-art performance across a wide range of adverse weather scenarios. Code is available at https://github.com/xxclfy/AgentRL-Real-Weather
SceneDecorator: Towards Scene-Oriented Story Generation with Scene Planning and Scene Consistency
Oct 27, 2025Recent text-to-image models have revolutionized image generation, but they still struggle with maintaining concept consistency across generated images. While existing works focus on character consistency, they often overlook the crucial role of scenes in storytelling, which restricts their creativity in practice. This paper introduces scene-oriented story generation, addressing two key challenges: (i) scene planning, where current methods fail to ensure scene-level narrative coherence by relying solely on text descriptions, and (ii) scene consistency, which remains largely unexplored in terms of maintaining scene consistency across multiple stories. We propose SceneDecorator, a training-free framework that employs VLM-Guided Scene Planning to ensure narrative coherence across different scenes in a ``global-to-local'' manner, and Long-Term Scene-Sharing Attention to maintain long-term scene consistency and subject diversity across generated stories. Extensive experiments demonstrate the superior performance of SceneDecorator, highlighting its potential to unleash creativity in the fields of arts, films, and games.
DisCo-Layout: Disentangling and Coordinating Semantic and Physical Refinement in a Multi-Agent Framework for 3D Indoor Layout Synthesis
Oct 02, 2025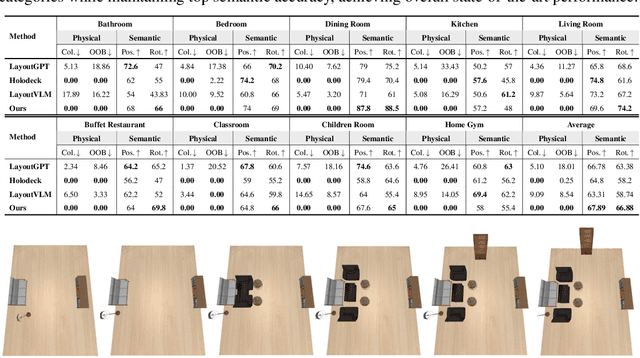
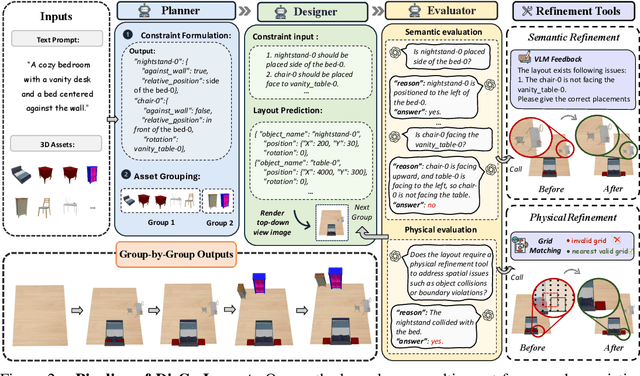
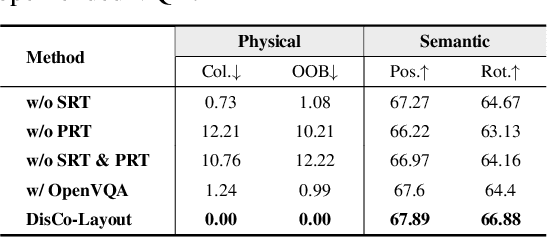
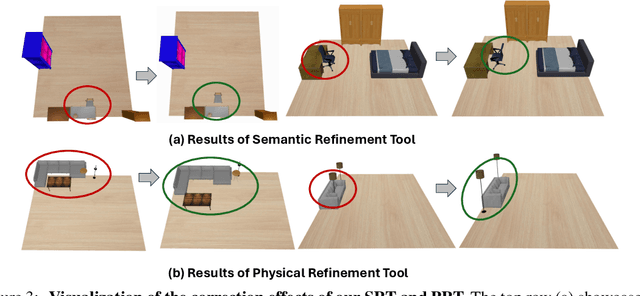
3D indoor layout synthesis is crucial for creating virtual environments. Traditional methods struggle with generalization due to fixed datasets. While recent LLM and VLM-based approaches offer improved semantic richness, they often lack robust and flexible refinement, resulting in suboptimal layouts. We develop DisCo-Layout, a novel framework that disentangles and coordinates physical and semantic refinement. For independent refinement, our Semantic Refinement Tool (SRT) corrects abstract object relationships, while the Physical Refinement Tool (PRT) resolves concrete spatial issues via a grid-matching algorithm. For collaborative refinement, a multi-agent framework intelligently orchestrates these tools, featuring a planner for placement rules, a designer for initial layouts, and an evaluator for assessment. Experiments demonstrate DisCo-Layout's state-of-the-art performance, generating realistic, coherent, and generalizable 3D indoor layouts. Our code will be publicly available.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Silence is Not Consensus: Disrupting Agreement Bias in Multi-Agent LLMs via Catfish Agent for Clinical Decision Making
May 27, 2025Large language models (LLMs) have demonstrated strong potential in clinical question answering, with recent multi-agent frameworks further improving diagnostic accuracy via collaborative reasoning. However, we identify a recurring issue of Silent Agreement, where agents prematurely converge on diagnoses without sufficient critical analysis, particularly in complex or ambiguous cases. We present a new concept called Catfish Agent, a role-specialized LLM designed to inject structured dissent and counter silent agreement. Inspired by the ``catfish effect'' in organizational psychology, the Catfish Agent is designed to challenge emerging consensus to stimulate deeper reasoning. We formulate two mechanisms to encourage effective and context-aware interventions: (i) a complexity-aware intervention that modulates agent engagement based on case difficulty, and (ii) a tone-calibrated intervention articulated to balance critique and collaboration. Evaluations on nine medical Q&A and three medical VQA benchmarks show that our approach consistently outperforms both single- and multi-agent LLMs frameworks, including leading commercial models such as GPT-4o and DeepSeek-R1.