 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorBenchX: Large-Scale Chest X-Ray Error Dataset and Vision-Language Model Benchmark for Report Error Correction
May 17, 2025AI-driven models have shown great promise in detecting errors in radiology reports, yet the field lacks a unified benchmark for rigorous evaluation of error detection and further correction. To address this gap, we introduce CorBenchX, a comprehensive suite for automated error detection and correction in chest X-ray reports, designed to advance AI-assisted quality control in clinical practice. We first synthesize a large-scale dataset of 26,326 chest X-ray error reports by injecting clinically common errors via prompting DeepSeek-R1, with each corrupted report paired with its original text, error type, and human-readable description. Leveraging this dataset, we benchmark both open- and closed-source vision-language models,(e.g., InternVL, Qwen-VL, GPT-4o, o4-mini, and Claude-3.7) for error detection and correction under zero-shot prompting. Among these models, o4-mini achieves the best performance, with 50.6 % detection accuracy and correction scores of BLEU 0.853, ROUGE 0.924, BERTScore 0.981, SembScore 0.865, and CheXbertF1 0.954, remaining below clinical-level accuracy, highlighting the challenge of precise report correction. To advance the state of the art, we propose a multi-step reinforcement learning (MSRL) framework that optimizes a multi-objective reward combining format compliance, error-type accuracy, and BLEU similarity. We apply MSRL to QwenVL2.5-7B, the top open-source model in our benchmark, achieving an improvement of 38.3% in single-error detection precision and 5.2% in single-error correction over the zero-shot baseline.
MMR-Mamba: Multi-Modal MRI Reconstruction with Mamba and Spatial-Frequency Information Fusion
Jul 07, 2024Multi-modal MRI offers valuable complementary information for diagnosis and treatment; however, its utility is limited by prolonged scanning times. To accelerate the acquisition process, a practical approach is to reconstruct images of the target modality, which requires longer scanning times, from under-sampled k-space data using the fully-sampled reference modality with shorter scanning times as guidance. The primary challenge of this task is comprehensively and efficiently integrating complementary information from different modalities to achieve high-quality reconstruction. Existing methods struggle with this: 1) convolution-based models fail to capture long-range dependencies; 2) transformer-based models, while excelling in global feature modeling, struggle with quadratic computational complexity. To address this, we propose MMR-Mamba, a novel framework that thoroughly and efficiently integrates multi-modal features for MRI reconstruction, leveraging Mamba's capability to capture long-range dependencies with linear computational complexity while exploiting global properties of the Fourier domain. Specifically, we first design a Target modality-guided Cross Mamba (TCM) module in the spatial domain, which maximally restores the target modality information by selectively incorporating relevant information from the reference modality. Then, we introduce a Selective Frequency Fusion (SFF) module to efficiently integrate global information in the Fourier domain and recover high-frequency signals for the reconstruction of structural details. Furthermore, we devise an Adaptive Spatial-Frequency Fusion (ASFF) module, which mutually enhances the spatial and frequency domains by supplementing less informative channels from one domain with corresponding channels from the other.
MMR-Mamba: Multi-Contrast MRI Reconstruction with Mamba and Spatial-Frequency Information Fusion
Jun 27, 2024Multi-contrast MRI acceleration has become prevalent in MR imaging, enabling the reconstruction of high-quality MR images from under-sampled k-space data of the target modality, using guidance from a fully-sampled auxiliary modality. The main crux lies in efficiently and comprehensively integrating complementary information from the auxiliary modality. Existing methods either suffer from quadratic computational complexity or fail to capture long-range correlated features comprehensively. In this work, we propose MMR-Mamba, a novel framework that achieves comprehensive integration of multi-contrast features through Mamba and spatial-frequency information fusion. Firstly, we design the \textit{Target modality-guided Cross Mamba} (TCM) module in the spatial domain, which maximally restores the target modality information by selectively absorbing useful information from the auxiliary modality. Secondly, leveraging global properties of the Fourier domain, we introduce the \textit{Selective Frequency Fusion} (SFF) module to efficiently integrate global information in the frequency domain and recover high-frequency signals for the reconstruction of structure details. Additionally, we present the \textit{Adaptive Spatial-Frequency Fusion} (ASFF) module, which enhances fused features by supplementing less informative features from one domain with corresponding features from the other domain. These innovative strategies ensure efficient feature fusion across spatial and frequency domains, avoiding the introduction of redundant information and facilitating the reconstruction of high-quality target images. Extensive experiments on the BraTS and fastMRI knee datasets demonstrate the superiority of the proposed MMR-Mamba over state-of-the-art MRI reconstruction methods.
Revitalizing Multivariate Time Series Forecasting: Learnable Decomposition with Inter-Series Dependencies and Intra-Series Variations Modeling
Feb 20, 2024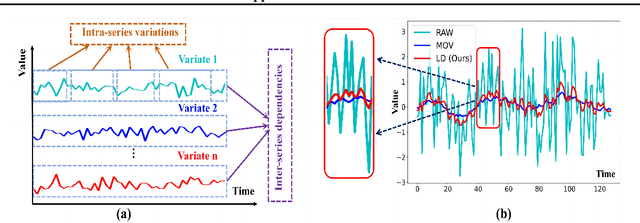


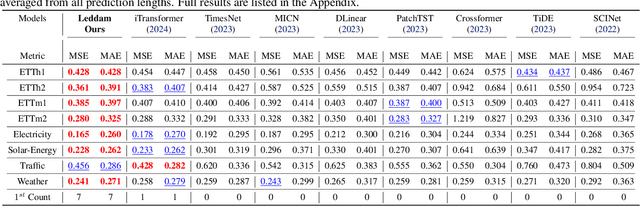
Predicting multivariate time series is crucial, demanding precise modeling of intricate patterns, including inter-series dependencies and intra-series variations. Distinctive trend characteristics in each time series pose challenges, and existing methods, relying on basic moving average kernels, may struggle with the non-linear structure and complex trends in real-world data. Given that, we introduce a learnable decomposition strategy to capture dynamic trend information more reasonably. Additionally, we propose a dual attention module tailored to capture inter-series dependencies and intra-series variations simultaneously for better time series forecasting, which is implemented by channel-wise self-attention and autoregressive self-attention. To evaluate the effectiveness of our method, we conducted experiments across eight open-source datasets and compared it with the state-of-the-art methods. Through the comparison results, our Leddam (LEarnable Decomposition and Dual Attention Module) not only demonstrates significant advancements in predictive performance, but also the proposed decomposition strategy can be plugged into other methods with a large performance-boosting, from 11.87% to 48.56% MSE error degradation.
Homeomorphic Image Registration via Conformal-Invariant Hyperelastic Regularisation
Mar 14, 2023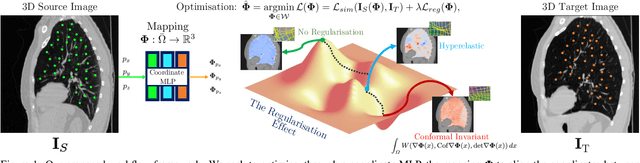
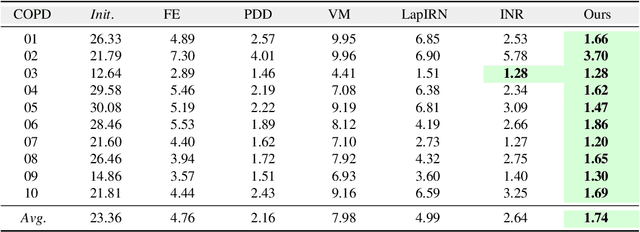
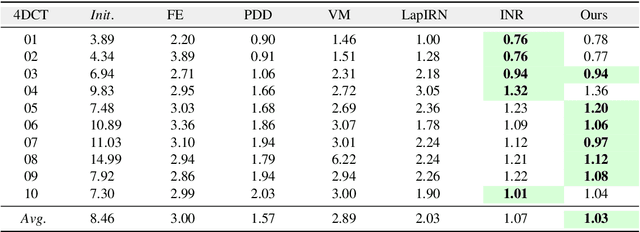
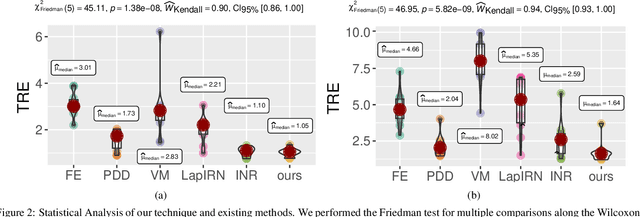
Deformable image registration is a fundamental task in medical image analysis and plays a crucial role in a wide range of clinical applications. Recently, deep learning-based approaches have been widely studied for deformable medical image registration and achieved promising results. However, existing deep learning image registration techniques do not theoretically guarantee topology-preserving transformations. This is a key property to preserve anatomical structures and achieve plausible transformations that can be used in real clinical settings. We propose a novel framework for deformable image registration. Firstly, we introduce a novel regulariser based on conformal-invariant properties in a nonlinear elasticity setting. Our regulariser enforces the deformation field to be smooth, invertible and orientation-preserving. More importantly, we strictly guarantee topology preservation yielding to a clinical meaningful registration. Secondly, we boost the performance of our regulariser through coordinate MLPs, where one can view the to-be-registered images as continuously differentiable entities. We demonstrate, through numerical and visual experiments, that our framework is able to outperform current techniques for image registration.
AMDET: Attention based Multiple Dimensions EEG Transformer for Emotion Recognition
Dec 23, 2022Affective computing is an important branch of artificial intelligence, and with the rapid development of brain computer interface technology, emotion recognition based on EEG signals has received broad attention. It is still a great challenge to effectively explore the multi-dimensional information in the EEG data in spite of a large number of deep learning methods. In this paper, we propose a deep model called Attention-based Multiple Dimensions EEG Transformer (AMDET), which can exploit the complementarity among the spectral-spatial-temporal features of EEG data by employing the multi-dimensional global attention mechanism. We transformed the original EEG data into 3D temporal-spectral-spatial representations and then the AMDET would use spectral-spatial transformer encoder layer to extract effective features in the EEG signal and concentrate on the critical time frame with a temporal attention layer. We conduct extensive experiments on the DEAP, SEED, and SEED-IV datasets to evaluate the performance of AMDET and the results outperform the state-of-the-art baseline on three datasets. Accuracy rates of 97.48%, 96.85%, 97.17%, 87.32% were achieved in the DEAP-Arousal, DEAP-Valence, SEED, and SEED-IV datasets, respectively. We also conduct extensive experiments to explore the possible brain regions that influence emotions and the coupling of EEG signals. AMDET can perform as well even with few channels which are identified by visualizing what learned model focus on. The accuracy could achieve over 90% even with only eight channels and it is of great use and benefit for practical applications.